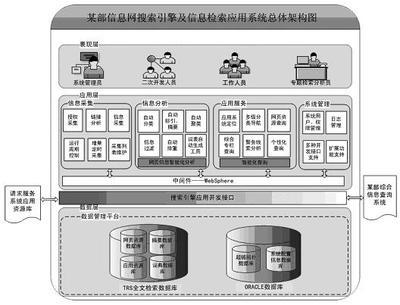
1全文搜索引擎 首先,Robot从www的各站点上搜集Web页面或其它各种信息项,并将其存入数据库中。 其次,根据用户通过web浏览器的用户界面输入的提问词,web浏览器将查询请求通过HTTP协议传到Searcher,Searcher通过索引库找出相关文档,在索引数据库中进行提问词与索引词的匹配运算,并将查询结果按相关程度排序并输出到用户接口子系统。 最后,用户通过Web浏览器看到结果、web页面的摘要或其它信息项的TITLEs列表后,若想看其中某个Web页面或其它信息项,则点击相应标题,web浏览器的用户查询界面在metadata数据库的支持下,通过HTTP协议可从信息所在的原始位置或Searcher所在的位置取回Web页面或其它信息项。 3.2.2目录(Directory)搜索引擎 另一类搜索引擎是不使用Spider程序,而是靠网站主动提交信息,人工输入数据,参照分类法的思路,按照主题建立分类索引,形成一个树形等级式的分类体系结构,建立起一套既可搜索又可浏览的等级式主题分类目录,以超文本链接方式把资源按不同类型划分成不同的目录,各类目录下面引出属于这一类别的网站名称和网址链接以及每个网站的内容简介。用户在查询信息时,只需按分类目录逐层查找,搜索引擎就会将找到的相关网站名称、网址及内容简介显示在屏幕上,用户单击网站名称即可进入相应的网站。这类搜索引擎我们称之为分类搜索引擎、目录搜索引擎或主题查询型搜索引擎。 由于目录是依靠人工进行整理搜索的,而且只在保存的对站点的描述中进行搜索,因此搜索范围较小,查全率较低,对偏僻主题、新兴学科、交叉学科不能很好地涵盖,类目间的交叉又会导致重复和资源浪费。另外,由于数据库更新速度比较慢,站点本身的动态变化不能及时地反映到搜索结果中,严重影响了查询结果的时效性。这是目录搜索引擎相对于Robot搜索引擎的不足之处。但同时,由于用户在进行信息查询时,只要遵循系统的分类体系按图索骥、层层深入即可,操作比较简单,大大方便了用户。另外,由于系统是依靠人工来评价描述网站,准确性比较高,因此用户从目录搜索所得到结果的准确度一般比较高,参考价值也比较大。 3.2.3元搜索引擎 所谓元搜索引擎(MetaSearchEngine),即指在统一的用户查询界面与信息反馈的形式下,共享多个搜索引擎的资源库,为用户提供信息服务的系统,又称作搜索引擎之上的搜索引擎。它将现有的多个搜索引擎看成一个整体,为用户提供一个统一的查询界面。用户只需提交一次搜索请求,元搜索引擎根据知识库中的信息,将用户请求转换为多个搜索引擎所能识别的格式,由元搜索引擎负责转换处理后提交给多个预先选定的独立搜索引擎,由这些搜索引擎完成实际的信息检索,最后元搜索引擎再把从各个搜索引擎返回的结果收集起来,进行比较分析,合并冗余信息,去除重复信息,以一定的格式返回给用户。 元搜索引擎主要由检索请求预处理、检索接口代理及检索结果处理等三部分构成。其中,检索请求预处理部分负责实现用户“个性化”的检索设置要求,包括调用哪些搜索引擎、检索时间限制、结果数量限制等。检索接口代理负责将用户的检索请求“翻译”成满足不同搜索引擎本地化要求的格式。检索结果处理负责所有源搜索引擎检索结果的去重、合并、输出处理等。 3.2.4各类搜索引擎比较分析

目录搜索引擎与Robot搜索引擎的主要不同,在于目录搜索引擎是通过人工方式进行资源搜集,且采取人工方式来进行网站描述,系统在保存的对站点的描述中进行信息搜索时,就确保了查准率。但同时,由于所有这些工作大部分是依靠人工方式来进行的,搜索范围较小,很多有用的信息可能由于没有收集到而没被检索到,从而一定程度上牺牲了查全率。 元搜索引擎本着利用各种搜索引擎优点的思想,基于一些独立的搜索引擎组合起来,查找范围得到了很大的扩展。它通过对通用搜索引擎得到的直接查询结果使用过滤器或改进算法。这样在一定程度上就利用了目录式搜索引擎查准率高而机器人搜索引擎查全率高的优点。这些都是元搜索引擎相对于独立搜索引擎的优势。 元搜索引擎是通过一个统一用户界面帮助用户利用若干直接搜索引擎来实现检索操作,因此它在查询输入处理及输出显示时均可能一些出现问题,如:多关键词处理,重复记录处理等。由于大部分搜索引擎互不兼容,相互操作性差,而且用户接口不一致,使得检索式处理非常复杂。如果查询请求包含超过一个或两个词或更复杂的逻辑,位于查询请求中较后面的词和逻辑很可能被忽略,因为只有少数支持这些逻辑的直接搜索引擎才能进行这样的输入处理。其次,作为一个元搜索引擎,如何能够将获取的信息按照相关度进行排序也是非常复杂的问题:因为不同搜索引擎在本身查询结果排序过程中采用的算法相差很大。甚至有一些未知的算法,而元搜索引擎必须结合这些使用不同排序算法产生的结果,并以统一的结果形式返回给用户,如果仅按各搜索引擎自己的结果序列顺序显示输出,结果很可能有重复。这些都是在元搜索引擎遇到的难题。