楚截图和文字分不清楚,因此用粉色背景来区分。
第一步、确定采集的网站(我们以DEDE的官方站做为采集站做示范)
Quote:
http://www.dedecms.com/plus/list.php?tid=10
第二步、确定被采集站的编码。打开被采集的网页之后,查看源代码(IE:查看 - > 源代码)
在 之间找到 charset 这个,后面就显示网页的编码了,截图的是 “gb2312”
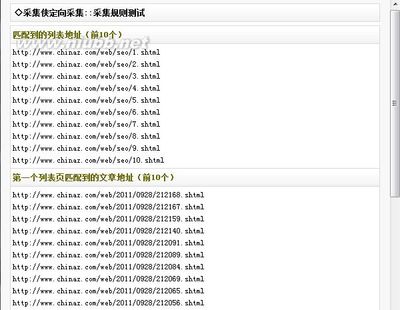
第三步、采集列表获取规则写法
来源网址写法 很明显pageno是表示分页页码 那么有多页列表的采集就要用“[var:分页]”来替换分页页码,截图如下
http://www.dedecms.com/ plus/list.php?tid=10&pageno=[var:分页]
文章网址需包含 网址不能包含 这两个一般不用写,用于采集列表范围有很多不需要的连接才用到他来做过滤使用。
上面的网址并没有带有至于http://www.dedecms.com 为什么要在前面加上,这个就不要我说了吧。
如果只有一个列表页,那么在来源网址就直接写上网址就OK了。
注意这里,最关键就是这里。
下面就是“采集获取文章列表的规则写法”,
就是上面打开的被采集页面的源代码文件,找到文章列表之前 和本页面没有其他相同的代码
在DedeCms官方站的列表页文章列表之前和之后最近的且没有相同的是“
”和“ ”,分别写入“起始HTML”和“结束HTML”,写法看截图
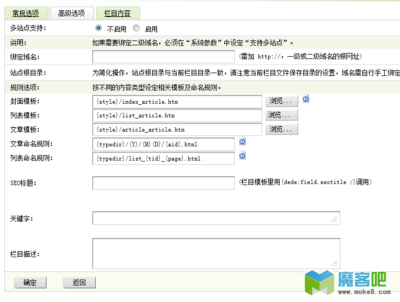
第四步、采集文章标题,文章内容,文章作者,文章来源等规则写法,分页采集等。
“起始HTML”和“结束HTML”写法参考第三步中的“获取文章列表的规则写法”
下面讲的是如何采集分页内容 看截图圈着的地方 截图
文档是否分页 里面选择“全部列出的分页列表”
“起始HTML”和“结束HTML”写法参考第三步中的“获取文章列表的规则写法”
当然 上面这些不能用来采集带有视频的,因为已经过滤了,后面的四行是过滤掉视频的。