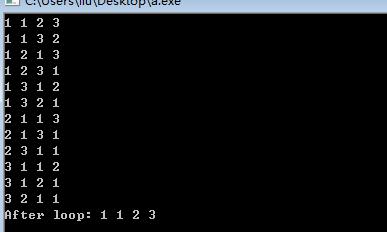
全排列生成算法:next_permutation――步骤/方法
全排列生成算法:next_permutation 1、
按照STL文档的描述,next_permutation函数将按字母表顺序生成给定序列的下一个较大的排列,直到整个序列为降序为止。prev_permutation函数与之相反,是生成给定序列的上一个较小的排列。二者原理相同,仅遍例顺序相反,这里仅以next_permutation为例介绍算法。
先对序列大小的比较做出定义:两个长度相同的序列,从两者的第一个元素开始向后寻找,直到出现一个不同元素(也可能就是第它们的第一个元素),该元素较大的序列为大,反之序列为小;若一直到最后一个元素都相同,那么两个序列相等。
全排列生成算法:next_permutation 2、
设当前序列为pn,下一个较大的序列为pn+1,这里蕴藏的含义是再也找不到另外的序列pm,使得pn < pm < pn+1。
问题
给定任意非空序列,生成下一个较大或较小的排列。
过程
根据上述概念易知,对于一个任意序列,最小的排列是增序,最大的为减序。那么给定一个pn要如何才能生成pn+1呢?先来看下面的例子:
全排列生成算法:next_permutation 3、
设3 6 4 2为pn,下一个序列pn+1应该是4 2 3 6。观察第一个序列可以发现pn中的6 4 2已经为减序,在这个子集中再也无法排出更大的序列了,因此必须移动3的位置且要找一个数来取代3的位置。在6 4 2中6和4都比3大,但6比3大的太多了,只能选4。将4和3的位置对调后形成排列4 6 3 2。注意,由于4和3大小的相邻关系,对调后产生的子集6 3 2仍保持逆序,即该子集最大的一种排列。而4是第一次移动到头一位的,需要后面的子集为最小的排列,因此直接将6 3 2倒转为2 3 6便得到了正确的一个序列pn+1。
全排列生成算法:next_permutation 4、
下面归纳分析该过程。假设一个有m个元素的序列pn,其下一组较大排列为pn+1:
若pn的最后的2个元素构成一个最小的增序子集,那么直接反转这2个元素使该子集成为减序即可得到pn+1。理由是pn和pn+1的前面m-2个元素都相等(没有对前面的元素进行操作),仅能靠最后2个元素来分出大小。而这2个元素只能出现2种排列,其中较大的一种是减序。
若pn的最后最多有s个元素构成一个减序子集,令i = m - s,则有pn(i) < pn(i+1),因此若将pn(i)和pn(i+1)调换必能得到一个较大的排列(不一定是下一个),因此必须保持pn(i)之前的元素不动,并在子集{pn(i+1), pn(i+2), ..., pn(m)}中找到一个仅比pn(i)大的元素pn(j),将二者调换位置。此时只要得到新子集{pn(i+1), pn(i+2), ..., pn(i), ...,pn(m)}的最小排列即可。注意到新子集仍保持减序,那么直接将其反转即可得到最小的增序子集。
按以上步骤便可从pn得到pn+1了。
全排列生成算法:next_permutation 5、
复杂度
最好的情况为pn的最后的2个元素构成一个最小的增序子集,交换次数为1,复杂度为O(1),最差的情况为1个元素最小,而后面的所有元素构成减序子集,这样需要先将第1个元素换到最后,然后反转后面的所有元素。交换次数为1+(n-1)/2,复杂度为O(n)。这样平均复杂度即为O(n/2)。
全排列生成算法:next_permutation 6、
C++/STL实现
01#include <algorithm>
02#include <iostream>
03#include <string>
04using namespace std;
05//主函数,算法详见相关说明
06int main(void) {
07 //循环处理输入的每一个字符串
08 for (string str; cin >> str;) {
09 if (str.empty()) {
10 continue;
11 }
12 //如果字符串只有1个字符,则直接输出结束
13 if (str.length() <= 1) {
14 cout << "No more Permutation" << endl;
15 }
16 //iPivot为右边最大减序子集左边相邻的一个元素
17 string::iterator iPivot = str.end(), iNewHead;
18 //查找右边最大的减序子集
19 for (--iPivot; iPivot != str.begin(); --iPivot) {
20 if (*(iPivot - 1) < *iPivot ) {
21 break;
22 }
23 }
24 //如果整个序列都为减序,则重排结束。
25 if (iPivot == str.begin()) {
26 cout << "No more Permutation" << endl;
27 }
28 //iPivot指向子集左边相邻的一个元素
29 iPivot--;
30 //iNewHead为仅比iPivot大的元素,在右侧减序子集中寻找
31 for (iNewHead = iPivot + 1; iNewHead != str.end(); ++iNewHead) {
32 if (*iNewHead < *iPivot) {
33 break;
34 }
35 }
36 //交换iPivot和iNewHead的值,但不改变它们的指向
37 iter_swap(iPivot, --iNewHead);
38 //反转右侧减序子集,使之成为最小的增序子集
39 reverse(iPivot + 1, str.end());
40 //本轮重排完成,输出结果
41 cout << str << endl;
42 }
43 return 0;
44}