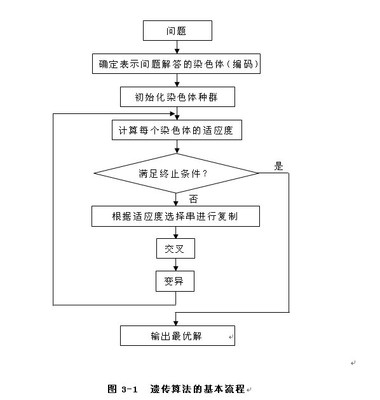
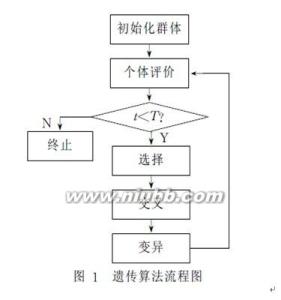
遗传算法(Genetic Algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一定数目的个体(individual)组成。每个个体实际上是染色体(chromosome)带有特征的实体。染色体作为遗传物质的主要载体,即多个基因的集合,其内部表现(即基因型)是某种基因组合,它决定了个体的形状的外部表现,如黑头发的特征是由染色体中控制这一特征的某种基因组合决定的。因此,在一开始需要实现从表现型到基因型的映射即编码工作。由于仿照基因编码的工作很复杂,我们往往进行简化,如二进制编码,初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度(fitness)大小选择(selection)个体,并借助于自然遗传学的遗传算子(genetic operators)进行组合交叉(crossover)和变异(mutation),产生出代表新的解集的种群。这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码(decoding),可以作为问题近似最优解。
遗传算法流程图_遗传算法 -基本框架
GA的流程图
GA的流程图
GA的流程图如右图所示
编码
遗传算法不能直接处理问题空间的参数,必须把它们转换成遗传空间的由基因按一定结构组成的染色体或个体。这一转换操作就叫做编码,也可以称作(问题的)表示(representation)。
评估编码策略常采用以下3个规范:
a)完备性(completeness):问题空间中的所有点(候选解)都能作为GA空间中的点(染色体)表现。
b)健全性(soundness): GA空间中的染色体能对应所有问题空间中的候选解。
c)非冗余性(nonredundancy):染色体和候选解一一对应。
目前的几种常用的编码技术有二进制编码,浮点数编码,字符编码,变成编码等。
而二进值编码是目前遗传算法中最常用的编码方法。即是由二进值字符集{0,1}产生通常的0,1字符串来表示问题空间的候选解。它具有以下特点:
a)简单易行
b)符合最小字符集编码原则
c)便于用模式定理进行分析,因为模式定理就是以基础的。
适应度函数
进化论中的适应度,是表示某一个体对环境的适应能力,也表示该个体繁殖后代的能力。遗传算法的适应度函数也叫评价函数,是用来判断群体中的个体的优劣程度的指标,它是根据所求问题的目标函数来进行评估的。
遗传算法在搜索进化过程中一般不需要其他外部信息,仅用评估函数来评估个体或解的优劣,并作为以后遗传操作的依据。由于遗传算法中,适应度函数要比较排序并在此基础上计算选择概率,所以适应度函数的值要取正值。由此可见,在不少场合,将目标函数映射成求最大值形式且函数值非负的适应度函数是必要的。
适应度函数的设计主要满足以下条件:
a)单值、连续、非负、最大化
b) 合理、一致性
c)计算量小
d)通用性强。
在具体应用中,适应度函数的设计要结合求解问题本身的要求而定。适应度函数设计直接影响到遗传算法的性能。
初始群体的选取
遗传算法中初始群体中的个体是随机产生的。一般来讲,初始群体的设定可采取如下的策略:
a)根据问题固有知识,设法把握最优解所占空间在整个问题空间中的分布范围,然后,在此分布范围内设定初始群体。
b)先随机生成一定数目的个体,然后从中挑出最好的个体加到初始群体中。这种过程不断迭代,直到初始群体中个体数达到了预先确定的规模。
遗传算法流程图_遗传算法 -一般算法
遗传算法是模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型。它的思想源于生物遗传学和适者生存的自然规律,是具有“生存+检测”的迭代过程的搜索算法。遗传算法以一种群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、交叉和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定五个要素组成了遗传算法的核心内容。 作为一种新的全局优化搜索算法,遗传算法以其简单通用、鲁棒性强、适于并行处理以及高效、实用等显着特点,在各个领域得到了广泛应用,取得了良好效果,并逐渐成为重要的智能算法之一。
遗传算法是基于生物学的,理解或编程都不太难。下面是遗传算法的一般算法: