高性能计算(HPC)是一个计算机集群系统,它通过各种互联技术将多个计算机系统连接在一起,利用所有被连接系统的综合计算能力来处理大型计算问题,所以又通常被称为高性能计算集群。
高性能计算_高性能计算 -概述
高性能计算(HPC) 指通常使用很多处理器(作为单个机器的一部分)或者某一集群中组织的几台计算机(作为单个计图1.HPC 总线网络拓扑算资源操作)的计算系统和环境。有许多类型的HPC 系统,其范围从标准计算机的大型集群,到高度专用的硬件。大多数基于集群的HPC系统使用高性能网络互连,比如那些来自 InfiniBand 或 Myrinet 的网络互连。基本的网络拓扑和组织可以使用一个简单的总线拓扑,在性能很高的环境中,网状网络系统在主机之间提供较短的潜伏期,所以可改善总体网络性能和传输速率。
图1.HPC 总线网络拓扑图1显示了标准总线拓扑中使用标准 Ethernet 的 HPC 解决方案或专门的网络连接解决方案的布局示例。
图2显示了一网状 HPC 系统。在网状网络拓扑中,该结构支持通过缩短网络节点之间的物理和逻辑距离来加快跨主机的通信。图2.HPC 网状网络拓扑
图2.HPC 网状网络拓扑
尽管网络拓扑、硬件和处理硬件在 HPC 系统中很重要,但是使系统如此有效的核心功能是由操作系统和应用软件提供的。
HPC 系统使用的是专门的操作系统,这些操作系统被设计为看起来像是单个计算资源。正如从图1和图2中可以看到的,其中有一个控制节点,该节点形成了 HPC 系统和客户机之间的接口。该控制节点还管理着计算节点的工作分配。
对于典型 HPC 环境中的任务执行,有两个模型:单指令/多数据 (SIMD) 和多指令/多数据 (MIMD)。SIMD在跨多个处理器的同时执 行相同的计算指令和操作,但对于不同数据范围,它允许系统同时使用许多变量计算相同的表达式。MIMD允许HPC 系统在同一时间 使用不同的变量执行不同的计算,使整个系统看起来并不只是一个没有任何特点的计算资源(尽管它功能强大),可以同时执行许多计算。
不管是使用 SIMD 还是MIMD,典型 HPC 的基本原理仍然是相同的:整个HPC 单元的操作和行为像是单个计算资源,它将实际请求的加载展开到各个节点。HPC 解决方案也是专用的单元,被专门设计和部署为能够充当(并且只充当)大型计算资源。
高性能计算_高性能计算 -与传统网格比较
网格计算概述
网格对于高性能计算系统而言是相对较新的新增内容,它有自己的历史,并在不同的环境中有它自己的应用。网格计算系统的关键元素是网格中的各个节点,它们不是专门的专用组件。在网格中,各种系统常常基于标准机器或操作系统,而不是基于大多数并行
计算解决方案中使用的严格受控制的环境。位于这种标准环境顶部的是应用软件,它们支持网格功能。
网格可能由一系列同样的专用硬件、多种具有相同基础架构的机器或者由多个平台和环境组成的完全异构的环境组成。专用计算资
源在网格中并不是必需的。许多网格是通过重用现有基础设施组件产生新的统一计算资源来创建的。
不需要任何特别的要求就可以扩展网格,使进一步地使用节点变得比在典型HPC环境中还要轻松。有了HPC解决方案,就可以设计和
部署基于固定节点数的系统。扩展该结构需要小心规划。而扩展网格则不用考虑那么多,节点数会根据您的需要或根据可用资源动
态地增加和减少。图3.网格网络架构
尽管有了拓扑和硬件,网格就可以以图1和图2中所示结构的相同结构为基础,但使用标准网络连接组件支持网格也是有可能的。甚
至可以交叉常规网络边界,在WAN或互联网上合并计算资源,如图3所示。
图3 网格网络架构
作为执行模型和环境,网格还被设计成在操作和执行方面更具灵活性。尽管可以使用网格解决诸如HPC解决方案之类的计算任务,但网格可能更灵活,可以使用各种节点执行不同的计算、表达式和操作。网格并不只是一种没有任何特点的计算资源,可将它分布到各种节点中使用,并且一直运行到作业和操作都已完成。这使得网格在不同计算和组件的执行顺序对于剩余任务的连续执行不那么重要的地方变得更加实用。
利用这种可变长度灵活性和较孤立任务的网格解决方案的一个好例子是计算机合成电影和特技效果中的表演。在这里,生成的顺序并不重要。单帧或更大的多秒的片段可以彼此单独呈现。尽管最终目标是让电影以正确的顺序播放,但最后五分钟是否在最初的五分钟之前完成是无关紧要的;稍后可以用正确的顺序将它们衔接在一起。
网格与传统HPC解决方案之间的其他主要不同是:HPC解决方案设计用于提供特定资源解决方案,比如强大的计算能力以及在内存中保存大量数据以便处理它们的能力。另一方面,网格是一种分布式计算资源,这意味着网格可以根据需要共享任何组件,包括内存、CPU电源,甚至是磁盘空间。
因为这两个系统之间存在这些不同,因此开发出了简化该过程的不同编程模型和开发模型。
并行计算
HPC解决方案的专用特性在开发应用程序以使用这种能力时提供了一些好处。大多数HPC系统将自己表现为单个计算资源,因此它成为一种编程责任,需要通过专用库来构建一个能够分布到整个资源中的应用程序。
HPC环境中的应用程序开发通常是通过专用库来处理,这极大简化了创建应用程序的过程以及将该应用程序的任务分配到整个HPC系统中的过程。
最流行的解决方案之一是消息传递接口(MPI)。MPI提供了一个创建工作的简化方法,使用消息传递在各个节点之间交换工作请求。作为开发过程的一部分,可能知道想要使用的处理器(在这里指单独节点,而非单独CPU)的数量。HPC环境中的劳动分工取决于应用程序,并且很显然还取决于HPC环境的规模。如果将进行的工作分配依赖于多个步骤和计算,那么HPC环境的并行和顺序特性将在网格的速度和灵活性方面起到重要作用。
图4.HPC功能图一旦分配好工作,就可以给每个节点发送一条消息,让它们执行自己的那部分工作。工作被放入HPC单元中同时发给每个节点,通常会期望每个节点同时给出结果作为响应。来自每个节点的结果通过MPI提供的另一条消息返回给主机应用程序,然后由该应用程序接收所有消息,这样工作就完成了。图4中显示了这种结构的一个示例。
图4.HPC功能图
执行模型通常是固定的,并且连续到完成某个单个应用程序。例如,如果将一项任务分配给256 个单元,而HPC系统中有64个节点,那么需要4个过程迭代来完成工作。工作通常是并行完成的,在整个应用程序完成之前,所有64个节点都仍将保持忙碌。在整个过程中,HPC系统充当一台机器。尽管消息已经被用来在多个计算节点中分配工作,但整个应用程序被有效地操作为一个单独的应用程序。
其他HPC库和接口的工作方式类似,具体的方式取决于开发用于HPC环境中的应用程序。无论什么时候,都可以将工作分配和执行看作一个单独的过程。尽管应用程序的执行可能要排队等候,但一旦应用程序开始运行,将立即在HPC系统的所有节点上执行该工作的各个组件。
为了处理多个同时发生的应用程序,多数HPC系统使用了一个不同应用程序在其中可以使用不同处理器/节点设置的系统。例如256个节点的HPC系统可以同时执行两个应用程序,如果每个应用程序都使用整个计算资源的一个子集的话。
网格编程
网格的分布式(常常是非专用的)结构需要为工作的执行准备一个不同的模型。因为网格的这种特性,无法期望同时执行各种工作单元。有许多因素影响了工作的执行时间,其中包括工作分配时间以及每个网格节点的资源的有效功率。
因为各个节点中存在的不同之处和工作被处理的方式,网格使用了一个将网格节点的监视与工作单元的排队系统相结合的系统。该监视支持网格管理器确定各个节点上的当前负载。然后在分配工作时使用该信息,把要分配的工作单元分配给没有(或有少量)当前资源负载的节点。
图5.网格功能图所以,整个网格系统基于一系列的队列和分布,通过在节点之间共享负载,在节点变得可用时将工作分配给队列中的每个节点,使网格作为一个整体得到更有效的使用。
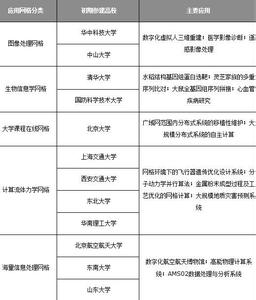
图5.网格功能图
响应和结果都同样地在网格控制器上进行排队,以便在处理完所有工作单元(及其结果)时将它们收集到应用程序的最终结果集中。图5中显示了这样一个示例。
网格模型允许使用各种级别的资源、工作单元规模和分配级别,而不只是HPC解决方案使用的执行模型提供的那些。大多数网格支持使用每个将被排队和分配的应用程序的各种工作单元同时执行多个工作请求。例如,可以在一些节点仍然在完成Job1上的工作时开始Job2上的工作,为了完成工作,两项作业以某种动态的方式使用相同数量的可用节点。
此过程的灵活特性不但允许以更动态更适应的方式执行工作,还允许网格与各种硬件和平台一起使用。即使网格中的某些节点比其他一些节点更快或更慢一些,也不再有任何关系;它们可以在自己(比较)空闲的时间完成工作,并且结果将被排队。其间,更快的系统可能被分配更多的工作并完成更多的工作单元。
出现这种不利现象是因为需要更繁重的管理费用来观察和监视各个节点,以便能够在节点间有效分配工作。在异构环境中,还必须
考虑不同的平台,并开发跨支持环境兼容的应用程序。但在网格空间中,Web服务已简化了该过程,使分配工作变得更容易,不必担心这些不同。
在查看Web服务的效果之前,查看HPC和网格之间的会合区域,并了解这将如何影响不同的执行模型。
会合区域
HPC 和网格环境之间存在一些类似之处,在许多方面,这二者都出现了一些会合和分歧,不同的团体利用了这两个系统的各自优点 。许多网格环境已从HPC解决方案的扩展中产生,基于HPC环境中的工作,网格中使用的许多技术得到了优化和采用。
一些显而易见的类似之处是工作被分配到更小的单元和组件中的方式,以及各个工作节点之间的工作分配方式。在HPC环境中,这种 劳动分配通常受到严格控制,并且是根据您的可用资源进行的。网格使用了一种更灵活的模型,该模型允许将工作分配给大小不标准的单元,因此可以在截然不同的网格节点数组之间分配工作。
尽管工作的分配方式上存在不同,但分配的基本原则仍然是相同的:先确定工作及其分配方式,然后相应地创建工作单元。例如,如果遇到计算问题,可以通过创建不同的参数集,利用将应用于每个节点的每个集合的变量来分配工作。
HPC 系统中使用的消息传递结构和系统也已开发并适用于网格系统。许多 HPC 消息传递库使用共享内存结构来支持节点之间的工作单元分配。
在网格中,共享的内存环境是不存在的。此外,工作是利用标准网络连接(通常使用TCP/IP)上发送的不同消息来分配的。系统的核心没有什么不同:交换包含工作参数的消息。只有交换信息的物理方法是不同的。
Web 服务的影响
尽管平台独立 HPC 系统非常常见(比如 MPI,它支持多个平台和架构),但 HPC 解决方案并不能直接使用,并且许多使用仍然依赖于架构的统一。
典型网格的不同特性导致工作分配方式发生了变化。因为网格节点可能基于不同平台和架构,所以在不同公用和私用网络上,需要某种以平台为核心的交换工作和请求的方法,该方法使分配工作变得更容易,不必担心目标环境。
Web 服务基于开放标准,使用XML来分配和交换信息。该效果实质上将消除在平台和架构间共享信息的复杂性。可以编写一系列支持不同操作的Web服务,而不是编写跨网格执行的二进制应用程序,这些 Web 服务是为各种节点和平台量身订做的。部署Web服务的费用也比较低,这使得它们对于不使用专用计算节点的网格中的操作比较理想。
通过消除兼容性问题并简化信息分配方法,Web服务使网格的扩展变得更轻松。使用HPC解决方案,通常必须使用基于相同硬件的节点来扩展HPC环境的功能。而使用网格,特别是在使用Web服务时,系统几乎可以在任何平台上扩展。
网格和Web服务的其他问题是由于不再应用关闭的HPC系统和内部HPC系统而导致的常见分配和安全考虑事项。在WAN或公用网络上使用网络节点时尤为如此。对于HPC 解决方案,系统的安全可通过硬件的统一特性得到控制;对于某一位置上的所有机器,安全性更容易控制。
为了提高Web服务的互操作性,特别是在网格环境中,OASIS 团队开发了许多Web服务标准。这些标准都是通过其WS前缀来标识的。通用规范包含一些顶级 Web服务支持和全面保护规范,用于发现Web服务和选项以及信息交换(通过WS-Security)。
更深一层的标准提供了用来共享资源和信息的标准化方法(WS-Resource 和 WS-Resource Framework)、用来可靠地交换消息的标准化方法(WS-Reliable Messaging)、用于事件通知的标准化方法(WS-Notification),甚至是用于 Web 服务管理的标准化方法(WS-Distributed Management)。
出于安全考虑,可以 WS-Reliable Messaging 交换与WS-Security 标准包装在一起,这定义了用于身份验证、授权和消息交换加密的方法和过程。
通过将Web服务标准支持、安全规范和您自己的定制Web 服务组件结合在一起,可以构建一个使用多个平台和环境的高效网格。然后可以在LAN环境中使用应用程序,或者安全地通过公用网络提供与典型HPC解决方案同样强大的计算资源,但具有扩展的灵活性和对网格技术的标准支持。
结束语
网格计算从技术上说是一种高性能计算机,但它在许多方面不同于传统的HPC 环境。大多数传统HPC技术都是基于固定的和专用的硬件,并结合了一些专门的操作系统和环境来产生高性能的环境。相比较而言,网格可以使用日用硬件、不同平台,甚至被配置成可以使用现有基础设施中的多余容量。
尽管存在一些不同,但两个系统也有许多相似之处,特别是查看跨节点的工作分工和分配时。在两种情况下,都可以使用Web服务来帮助支持系统操作。通过使用开放标准并允许支持更广范围的操作系统和环境,Web 服务和网格技术可能在高性能计算解决方案的功效和灵活性方面带来很大的不同。
高性能计算_高性能计算 -优化
高性能计算(HighPerformanceComputing)是计算机科学的一个分支,主要是指从体系结构、并行算法和软件开发等方面研究开发高性能计算机的技术。
随着计算机技术的飞速发展,高性能计算机的计算速度不断提高,其标准也处在不断变化之中。
曙光CAE高性能计算平台高性能计算简单来说就是在16台甚至更多的服务器上完成某些类型的技术工作负载。到底这个数量是需要8 台,12台还是16台服务器这并不重要。在定义下假设每一台服务器都在运行自己独立的操作系统,与其关联的输入/输出基础构造都是建立在COTS系统之上。
曙光CAE高性能计算平台
简而言之,讨论的就是Linux高性能计算集群。
一个拥有20000台服务器的信息中心要进行分子动力学模拟无疑是毫无问题的,就好比一个小型工程公司在它的机房里运行计算流体动力学(CFD)模拟。解决工作负载的唯一限制来自于技术层面。接下来我们要讨论的问题是什么能直接加以应用。
量度(Metrics)
性能(Performance),每瓦特性能(Performance/Watt),每平方英尺性能(Performance/Squarefoot)和性能价格比
(Performance/dollar)等,对于提及的20000台服务器的动力分子簇来说,原因是显而易见的。运行这样的系统经常被服务器的能量 消耗(瓦特)和体积(平方英尺)所局限。这两个要素都被计入总体拥有成本(TCO)之列。在总体拥有成本(TCO)方面取得更大的经济效益是大家非常关注的。
议题的范围限定在性能方面来帮助大家理解性能能耗,性能密度和总体拥有成本(TCO)在实践中的重要性。
性能的定义
在这里把性能定义为一种计算率。例如每天完成的工作负载,每秒钟浮点运算的速度(FLOPs)等等。接下来要思考的是既定工作量的完成时间。这两者是直接关联的,速度=1/(时间/工作量)。因此性能是根据运行的工作量来进行测算的,通过计算其完成时间来转化成所需要的速度。
定量与定性
从定性的层面上来说这个问题很容易回答,就是更快的处理器,更多容量的内存,表现更佳的网络和磁盘输入/输出子系统。但当要
在决定是否购买Linu集群时这样的回答就不够准确了。
对Linux高性能计算集群的性能进行量化分析。
为此介绍部分量化模型和方法技巧,它们能非常精确的对大家的业务决策进行指导,同时又非常简单实用。举例来说,这些业务决策涉及的方面包括:
购买---系统元件选购指南来获取最佳性能或者最经济的性能Linux高性能计算集群模型
配置---鉴别系统及应用软件中的瓶颈
计划---突出性能的关联性和局限性来制定中期商业计划
Linux高性能计算集群模型
Linux高性能计算集群模型包括四类主要的硬件组成部分。
(1)执行技术工作负载的计算节点或者服务器;
(2)一个用于集群管理,工作控制等方面的主节点;
(3)互相连接的电缆和现在高度普及的千兆以太网(GBE);
(4)一些全球存储系统,像由主节点输出的NFS文件一样简单易用。
高性能计算机的衡量标准主要以计算速度(尤其是浮点运算速度)作为标准。高性能计算机是信息领域的前沿高技术,在保障国家安全、推动国防科技进步、促进尖端武器发展方面具有直接推动作用,是衡量一个国家综合实力的重要标志之一。
随着信息化社会的飞速发展,人类对信息处理能力的要求越来越高,不仅石油勘探、气象预报、航天国防、科学研究等需求高性能计算机,而金融、政府信息化、教育、企业、网络游戏等更广泛的领域对高性能计算的需求迅猛增长。
一个简单量化的运用模型
这样一个量化的运用模型非常直观。在一个集群上对既定的工作完成的时间大约等同于在独立的子系统上花费的时间:
e
1、时间(Time)=节点时间(Tnode)+电缆时间(Tfabric)+存储时间(Tstorage)
Time = Tnode + Tfabric + Tstorag
这里所说的时间(Time)指的是执行工作量的完成时间,节点时间(Tnode)是指在计算节点上花费的完成时间,电缆时间(Tfabric)是指在互联网上各个节点进行互联的完成时间,而存储时间(Tstorage)则是指访问局域网或全球存储系统的完成时间。
计算节点的完成时间大约等同于在独立的子系统上花费的时间:
2、节点时间(Tnode)=内核时间(Tcore) +内存时间(Tmemory)
这里所说的内核时间(Tcore)指的是在微处理器计算节点上的完成时间。而内存时间(Tmemory)就是指访问主存储器的完成时间。这个模型对于单个的CPU计算节点来说是非常实用的,而且能很容易的扩展到通用双插槽(SMP对称多处理)计算节点。为了使第二套模型更加实用,子系统的完成时间也必须和计算节点的物理配置参数相关联,例如处理器的速度,内存的速度等等。
计算节点
图示中的计算节点原型来认识相关的配置参数。图示上端的是2个处理器插槽,通过前端总线(FSB-front side bus)与内存控制中心(MCH)相连。这个内存控制中心(MCH)有四个存储信道。同时还有一个Infiniband HCA通过信道点对点串行(PCIe)连接在一起。性能参数像千兆以太网和串行接口(SATA)硬盘之类的低速的输入输出系统都是通过芯片组中的南桥通道(South Bridge)相连接的。在图示中,大家可以看到每个主要部件旁边都用红色标注了一个性能相关参数。这些参数详细的说明了影响性能(并非全部)的硬件的特性。它们通常也和硬件的成本直接相关。举例来说,处理器时钟频率(fcore)在多数工作负荷状态下对性能影响巨大。根据供求交叉半导体产额曲线原理,处理器速度越快,相应成本也会更高。
性能参数
高速缓存存储器的体积也会对性能产生影响,它能减少主频所承载的工作负荷以提高其运算速度。处理器内核的数量(Ncores)同样会影响性能和成本。内存子系统的速度可以根据双列直插内存模块频率(fDIMM)和总线频率(fBus)进行参数化,它在工作负荷状态下也对性能产生影响。同样,电缆相互连接(interconnect fabric)的速度取决于信道点对点串行的频率。
而其他一些因素,比如双列直插内存模块内存延迟(DIMMCAS Latency),存储信道的数量等都做为次要因素暂时忽略不计。
使用的性能参数
在图示中标明的6个性能参数中,保留四个和模型相关的参数。
首先忽略信道点对点串行的频率(fPCIe),因为它主要影响的是电缆相互连接(interconnect fabric)速度的性能,这不在范围之列。
接下来注意一下双列直插内存模块频率(fDIMM)和总线频率(fBus)会由于内存控制中心(MCH)而限于固定比率。
使用的双核系统中,这些比率最具代表性的是4:5, 1:1, 5:4。一般情况下只会用到其中的一个。高速缓存存储器的体积非常重要。
在这个模型中保留这个参数。内核的数量(Ncores)和内核频率(fcore)也非常重要,保留这两个参数。
高性能计算(HPC)模型
这第二个模型的基本形式在计算机体系研究领域已经存在了很多年。
A普通模式是:
(3) CPI = CPI0 + MPI * PPM
这里的CPI指的是处理器在工作负荷状态下每执行一个指令的周期。CPI0是指内核CPI,MPI I则是指在工作负荷状态下高速缓存存储器每个指令失误的次数(注释:在高性能计算领域,MPI主要用于信息传递界面,在此处主要是指处理器构造惯例),PPM是指以处理器时钟滴答声为单位对高速缓存存储器每个指令失误的次数的记录。第二和第三个方程式相互吻合。这第一个术语代表的是处理器,第二个术语代表的是内存。
可以直观的看到,假设每项工作下执行的P指令的工作负荷与代表处理器的频率的内核频率(每秒钟处理器运行周期的单位)再与方程式(3)相乘,就得到了方程式(4):
Tnode = (CPIo * P) * (1 / fcore) + (MPI * P) * PPM * (1 / fcore)
在这里要注意(CPIo * P)是以每项工作分配下处理器的运行周期为单位,对微处理器架构上运行的既定工作负荷通常是个恒量。因 此把它命名为α。(处理器周期本身无法对时间进行测算,如果乘以内核的频率就可以得到时间的测算标准。因此Tnode在方程式(4) 的右边)。
(MPI * P)也是同理。对于既定工作负荷和体系结构来说它也是个恒量,但它主要依赖于高速缓存存储器的体积。我们把它命名为M (MBcache)。而PPM是指访问主存的成本。对于既定的工作负荷来说,通常是个固定的数字C。PPM乘以内存频率和总线频率的比值(fcore / fBus)就从总线周期(bus cycles)转化成了处理器周期。因此PM = C * fcore / fBus。套入M(MBcache)就可以得到:
(5) Tnode = α * (1 / fcore) + M(MBcache) * (1 / fbus)
这个例子说明总线频率(bus frequency)也是个恒量,方程式(5)可以简化为方程式(6):
(6) Tnode = α * (1 / fcore) + β
在这里Tcore = α * (1 / fcore),而Tmemory = β(也就是公式2里的术语。我们把这些关键点关联在一起)。
首先在模型2里,公式5和公式6都有坚实的理论基础,因为经分析过它是如何从公式3推理而来(它主要应用于计算机体系理论)。其次,这个模型4个硬件性能参数的3个已经包括其中。还差一个参数就是内核数量(Ncores)。
用直观的方式来说明内核的数量,就是假设把N个内核看做是一个网络频率上运行的一个内核,称之为N*fcore。那么根据公式(6)我们大致可以推算出:
(7) Tcore ~ α / (N*fcore)
Tcore~ ( α / N) * (1 / fcore )
也可以把它写成:
(8) αN = ( α / N)
多核处理器的第一个字母Alpha可能是单核处理器的1/N次。
通过数学推算这几乎是完全可能的。
通常情况下我们是根据系统内核和总线频率(bus frequencies)来衡量计算机系统性能,如公式(5)所阐述的。但是公式(5)的左边是 时间单位--这个时间单位指的是一项工作量的完成时间。这样就能更清楚的以时间为单位说明右侧的主系统参数。同时请注意内核的时钟周期τcore(是指每次内核运行周期所需的时间)也等同于(1 / fcore)。总线时钟(bus clock)周期也是同理。
(9) Tnode = αN * τcore + M(MBcache) * τBus
这个公式的转化也给了一个完成时间的模型,那就是2个基本的自变量τcore和τBus呈现出直线性变化。这对使用一个简单的棋盘
式对照表对真实系统数据进行分析是有帮助的。
高性能计算_高性能计算 -应用和发展趋势
大家已逐渐认同这一观点,高性能计算机是价格在10万元以上的服务器。之所以称为高性能计算机,主要是它跟微机与低档PC服务器相比而言具有性能、功能方面的优势。高性能计算机也有高、中、低档之分,中档系统市场发展最快。从应用与市场角度来划分 ,中高档系统可分为两种,曙光2000一种叫超级计算机,主要是用于科学工程计算及专门的设计,如Cray T3E;另一种叫超级服务器,可以用来支持计算、事务处理、数据库应用、网络应用与服务,如IBM的SP和国产的曙光2000。
曙光2000
从市场的角度来讲,高性能计算机是高技术、高利润而且市场份额在不断扩大的一个产业。高性能计算机在政府部门、科研等领域的广泛应用,对增强一个国家的科技竞争力有着不可替代的作用。另外,美国和欧洲的经验已经证明,企业使用高性能计算机能够有效地提高生产率。
高性能计算机的发展趋势主要表现在网络化、体系结构主流化、开放和标准化、应用的多样化等方面。网络化的趋势将是高性能计算机最重要的趋势,高性能计算机的主要用途是网络计算环境中的主机。以后越来越多的应用是在网络环境下的应用,会出现数以十亿计的客户端设备,所有重要的数据及应用都会放在高性能服务器上,Client/Server模式会进入到第二代,即服务器聚集的模式,这是一个发展趋势。
网格(Gird)已经成为高性能计算的一个新的研究热点,是非常重要的新兴技术。网络计算环境的应用模式将仍然是Internet/Web ,但5~10年后,信息网格模式将逐渐成为主流。在计算网格方面美国大大领先于其他国家。有一种观点认为,美国当前对于网格研究的支持可与其70年代对Internet研究的支持相比,10年后可望普及到国民经济和社会发展的各个领域。网格与Internet/Web的主要不同是一体化,它将分布于全国的计算机、数据、贵重设备、用户、软件和信息组织成一个逻辑整体。各行业可以在此基础上运行各自的应用网格。最近美国开始了STAR-TAP计划,试图将网格扩展到全世界。
在体系结构上,一个重要的趋势是超级服务器正取代超级计算机而成为高性能计算的主流体系结构技术。高性能计算机市场的低档产品将主要是SMP(Symmetric MultiProcessor,对称多处理机),中档产品是SMP、CC-NUMA(Cache Coherent-Non Uniform Memory Access,支持缓存一致性的非均匀内存访问)和机群,高档产品则将采用SMP或CC-NUMA节点的机群。在2001年左右,将会出现结合了NUMA(COMA和CC-NUMA)和机群体系结构优点的混合式结构,称之为Cluster-NUMA(C-NUMA)系统。可重构、可分区、可配置特性将变得越来越重要。此外还有一种新兴的称为多线程(Multithreading)体系结构将用于超级计算机中,它的代表是Tera公司的MTA系统,一台8CPU的MTA已经成功地运行在圣地亚哥超级计算机中心。值得注意的是,所有厂家规划的高档系统都是机群,已经有厂家开始研究C-NUMA结构。
美国一直是世界上最重视高性能计算机、投入最多和受益最大的国家,其研究也领先于世界。美国能源部的加速战略计算ASCI计划 ,目标是构造100万亿次的超级计算机系统、软件和算法,在2004年真实地模拟核爆炸;白宫直属的HECC(High-End Computing and Computations)计划,对高性能计算的关键技术进行研发,并构建高性能基础设施;PetaFLOPS计划开发构造千万亿次级系统的技术;最新的Ultrascale计划目标在2010年研制万万亿次级系统。日本计划将于2002年研制成40万亿次的并行向量机。欧洲的强项则主要体现在高性能计算机的应用方面。
总的来说,国外的高性能计算机应用已经具有相当的规模,在各个领域都有比较成熟的应用实例。在政府部门大量使用高性能计算机,能有效地提高政府对国民经济和社会发展的宏观监控和引导能力,包括打击走私、增强税收、进行金融监控和风险预警、环境和资源的监控和分析等等。
在发明创新领域,壳牌石油公司通过全球内部网和高性能服务器收集员工的创新建议,加以集中处理。其中产生了一种激光探测地下油床的新技术,为该公司发现了3亿桶原油。在设计领域,好利威尔公司和通用电气公司用网络将全球各地设计中心的服务器和贵重设备连于一体,以便于工程师和客户共同设计产品,设计时间可缩短100倍。对很多大型企业来说,采购成本是总成本的重要组成部分。
福特用高性能计算机构造了一个网上集市,通过网络连到它的3万多个供货商。这种网上采购不仅能降低价格,减少采购费用,还能缩短采购时间。福特估计这样做大约能节省80亿美元的采购成本。此外,制造、后勤运输、市场调查等领域也都是高性能计算机大显身手的领域。
高性能计算机能为企业创造的价值是非凡的,国外的企业和用户已经充分地认识到这一点。一个证明是,20世纪90年代中期以来,国外80%以上企业的信息主管在选购机器时考虑高性能计算机,而在20世纪90年代初,这个数字只有15%。
在国内这方面的宣传教育工作还很不够,没有让企业、政府和社会充分认识到高性能计算机的益处,从而导致了一些观念上的误解。以往一提起高性能计算机,人们马上就会联想到用于尖端科学计算的超级计算机。实际上,高性能计算机90%的用途是非科学计算的数据处理、事务处理和信息服务,它早已不是象牙塔里的阳春白雪。随着“网络计算”和“后PC时代”的到来,全世界将有数十亿的客户端设备,它们需要连到数百万台高性能服务器上。高性能计算机将越来越得到产业界的认同,成为重要的生产工具。
此外,人们一直以来还有这样一个认识误区,认为高性能计算机是面向高新产业和服务业的,而传统产业(尤其是制造业)并不需要使用。事实上,高性能计算机能够广泛应用于生物、信息、电子商务、金融、保险等产业,它同时也是传统产业(包括制造业)实现技术改造、提高生产率――“电子生产率”(e-productivity)和竞争力的重要工具。高性能计算已从技术计算(即科学计算和工程计算)扩展到商业应用和网络信息服务领域。的曙光2000-Ⅱ就瞄准了技术计算、商业应用和网络服务这3个领域的应用。
应该说,高性能计算机在国内的研究与应用已取得了一些成功,包括曙光2000超级服务器的推出和正在推广的一些应用领域,如航 空航天工业中的数字风洞,可以减少实验次数,缩短研制周期,节约研制费用;利用高性能计算机做气象预报和气候模拟,对厄尔尼诺现象及灾害性天气进行预警,国庆50周年前,国家气象局利用国产高性能计算机,对北京地区进行了集合预报、中尺度预报和短期天气预报,取得了良好的预报结果;此外,在生物工程、生物信息学、船舶设计、汽车设计和碰撞模拟以及三峡工程施工管理和质量控制等领域都有高性能计算机成功应用的实例。
但是总的说来,高性能计算机在国内的应用还比较落后,主要原因在于装备不足、联合和配套措施不力及宣传教育力度不够。首先,国内高性能计算机的装量明显不足。1997年世界高性能计算机的销售额美国约为220亿美元,中国约为7亿美元。美国的微机销售额约占世界市场的38%,高性能计算机占世界的34%,均高于其GDP所占世界份额(25%左右)。中国的微机销售额约占世界市场的3%,高于中国GDP的份额(2.6%);但中国高性能计算机销售额所占世界份额仅为1%左右,低于GDP的份额。从另一个角度看,中国的微机市场接近美国的1/10,但中国的高性能计算机市场不到美国的1/30。
装备不足严重影响了高性能计算机应用的开发和人才的培养,这些反过来又影响了高性能计算机的使用和装备。值得庆幸的是,随着网络化和信息化工作的深入,国内社会已开始意识到高性能计算机的重要性。1999年,中国高性能计算机的市场销售额猛增了50% 以上。
除了装备不足之外,我认为社会各行业、各层次的合作和配合不力也是阻碍高性能计算机应用发展的重要原因。应用市场的扩展关键要靠联合,在中国高性能计算机领域,系统厂商、应用软件厂商与最终用户和服务商之间并没有结成有效的战略联盟,形成优势互补的局面。我希望看到的是,曙光、联想、浪潮的服务器,运行着东大阿尔派、用友、同创等厂家的软件,在新浪网、8848网上为各行业的用户提供各种服务。国家正在实施一个“国家高性能计算环境”的计划,正朝着这方面努力。
国家863计划主题正在实施一个“国家高性能计算环境”的项目,计划到2000年年底在全国建设10个左右的高性能计算中心,这些中心将通过千兆位网络互连。目标就是尽量让全国用户免费共享全国的计算资源、信息资源和人才资源。这只是一个初期的项目,估计在2000年下半年会规划更大的项目。值得注意的是,已经规划的应用包括生物信息学、数字图书馆、科学数据库、科普数据库、汽车碰撞、船舶设计、石油油藏模拟、数字风洞、气象预报、自然资源考察和远程教育等领域。
2000年5月14~17日,国内将在北京组织一个“亚太地区高性能计算国际会议及展览”,届时全球二十几个国家和地区的代表以及国内外主流的服务器厂商将参加会议,会议计划围绕一些课题做特邀报告:美国工程院院士、Microsoft资深科学家Gordon Bell将讨论“后PC时代:当计算、存储和带宽都免费时,我们面临什么样的挑战?”,自由软件创始人Richard Stallman 将讨论“自由软件运动及GNU/Linux”, 俄罗斯科学院院士Boris Babayan将介绍俄罗斯花了6年功夫新近发明的一种电脑芯片,据称它比Intel的Pentium Ⅲ和Itanium快几倍,而且具有安全、防病毒功能。
IBM深度计算研究所所长Pulley Blank将介绍“深蓝、基因蓝以及IBM的深度计算战略”。从会议的内容上我们能够看出,高性能计算的范围已超出了高端科学计算的领域。相信这次会议对国内高性能产业的发展将起到一定的推动作用。
此外,国家还有一个重大基础研究计划(也叫973项目)。高性能计算已经成为科技创新的主要工具,能够促成理论或实验方法不能取得的科学发现和技术创新。973项目中的很多项目(尤其是其中的“高性能软件”和“大规模科学计算”项目)都与高性能计算机有着密切的关系。
高性能计算_高性能计算 -相关
想象一下,你是科研机构里的实验狂人,要进行一个复杂的X射线转化运算或者为下一个实体实验进行电脑仿真模拟。如果使用普通PC,基本无法进行;如果使用一个普通的工作站,至少需要数周的时间;如果使用单位里的服务器集群,得出结果的运算时间并长,但你需要很长的排队时间,因为它是公用的。但是,如果你拥有一台基于GPU运算的超级计算机,足不出户,只要在自己的桌面上,就可以轻松完成这项复杂工作,而所用的时间,甚至比实验室里的大块头服务器集群还要短。
现在,对于国内用户来说,个人桌面超级运算不再是梦想。近日,在其工作站业务迎来10周年之际,方正科技宣布将在中国市场推出具有超级计算能力的高性能工作站。其最新推出的旗舰机型美仑3400 2800,提供强大图形处理与高性能计算解决方案,采用全新英特尔“至强”处理器,搭载新一代NVIDIA Tesla GPU,能实现高性能的GPU超级运算,从而将工作站变身为桌面型超级计算机,满足专业用户的高性能计算需求。
对于国内用户来说,GPU(图形处理器)并不陌生,但对于GPU计算这一新兴运算方式,可能还不熟悉。简单来说,GPU计算即使用GPU(图形处理器)来执行通用科学与工程计算。目前的CPU最多只集成了4个内核,而GPU已经拥有数以百计的内核,在高密度并行计算方面拥有得天独厚的优势。方正科技推出的高性能计算工作站,使用CPU+GPU的异构计算模型,应用程序的顺序部分在CPU上运行,而计算密集型部分则由GPU来分担。这样,系统计算力得到淋漓尽致的释放,应用程序的运行速度能够提升1-2个数量级。
GPU计算的概念一经提出,就在高性能计算领域掀起了一场前所未有的风暴。在过去4年里,已经有累计1亿颗以上的GPU被三星、摩托罗拉等公司和哈佛、斯坦福等上百所高校研究机构应用于癌症的治疗和科研教学等多种领域。日本最快的超级电脑也采用了GPU计算这项技术。目前,微软的WIN7已经融入GPU运算功能。而下游厂商如惠普、方正、联想等也一直积极紧跟技术潮流,积极研发GPU计算应用产品。NVIDIA的首席执行官黄仁勋曾大胆预言:“2009年是GPU引爆年,CPU+GPU的个人运算时代已经来临。”
方正科技将GPU计算应用带入中国,为国内教育科研院校和机构、各大企业打造了一款桌面型高性能计算工作站。该产品可广泛应用于生物信息及生命科学、流体动力学、大气和海洋建模、空间科学、电子设计自动化、图形成像等众多领域。相对于传统的服务器集群,方正科技推出的GPU超级计算机在性价比、占地空间、功耗等方面的优势是压倒性的。做一个简单的算术:某大学原来用的服务器集群拥有256颗AMD皓龙双核处理器核,构建成本是500万美元,由全校共同来使用;但如果换成4台方正美仑3400 2800高性能计算工作站,性能更优,成本只有1万美元,耗电能减少10倍以上,即使每个研究人员桌面配备一台仍然划算。
作为国内较早涉足工作站业务的民族厂商,方正科技在工作站领域的研发与开拓上已经走过了10个春秋,取得了不俗的成绩。其工作站负责人表示,在10周年这个具有强烈纪念意义的时间点上,推出基于全新计算方式的GPU超级计算机,表明方正科技工作站根植 客户应用需求,紧跟技术潮流,不断推陈出新的决心。
高性能计算_高性能计算 -走向普及
中国在高端计算机的研制方面已经取得了较好的成绩,掌握了研制高端计算机的一些关键技术,参与高端计算机研制的单位已经从科研院所发展到企业界,有力地推动了高端计算的发展。随着中国信息化建设的发展,高性能计算的应用需求在深度和广度上都面临蓬勃发展。
高性能计算作为第三大科学方法和第一生产力的地位与作用被广泛认识,并开始走出原来的科研计算向更为广阔的商业计算和信息化服务领域扩展。更多的典型应用在电子政务、石油物探、分子材料研究、金融服务、教育信息化和企业信息化中得以展现。经过十年的发展,中国在高性能计算水平上已跻身世界先进水平。
企业界参与研制
国内做高性能计算的企业中有三家主力厂商,他们是曙光、联想和浪潮。863计划十几年来,曙光始终在研发过程中起着带头作用。高性能市场中,曙光高性能计算机销量已超过1000套,在国内应用是最广泛的。联想进入高性能市场比较晚,但是从其公司运作能力和市场化的能力看,虽然其遇到了一些困难,但是未来的发展潜力巨大。而浪潮以服务器起家,但在高性能方面,原来技术较弱,但是比较专一于高端商用市场,通过与大专院校的合作,发展比较快。
赛迪顾问分析师刘新在接受《中国电子报》记者采访时称,看国内高性能计算的前三名,曙光的整合计算、细分应用是其特点。由于具有长期的技术积淀,深厚的行业背景,鲜明的品牌形象,是国内三大品牌中商业化最成功的企业,但面临国内、国外的双向夹击,发展道路坎坷不平。而联想长期“贸工技”的战略使其可能会缺乏技术的积淀,做惯了PC设备供应和服务,在高性能计算领域显得底气不足,其主要市场策略依然延续PC模式,依靠低价等吸引用户是一大特色。而浪潮给人的感觉是在高性能方面有点缺乏技术实力和远见。
也许有人认为,高性能计算离我们的实际生活还很遥远,但是金融、电信、税务、能源、制造等行业中的很多企事业都已经开始应用高性能计算,而作为普通百姓的衣食住行,我们在刷卡购物、打电话、听天气预报、出门坐车时也已经在享受高性能计算所带来的准确与方便。
通过记者的采访,相关厂商一致认为,高性能计算走向普及已是大势所趋。这主要是由于商品化趋势使得大量生产的商品部件接近了高性能计算机专有部件,标准化趋势使得这些部件之间能够集成在一个系统中。
机群――未来高性能的发展方向
高性能计算机的主流体系结构收缩成了三种,即SM、CC-NUMA、Cluster。在产品上,只有两类产品具有竞争力:一是高性能共享存储系统;二是工业标准机群,包括以IA架构标准服务器为节点的PC机群和以RISC SMP标准服务器为节点的RISC机群。当前,对高性能计算机产业影响最大的就是“工业标准机群”了,这也反映了标准化在信息产业中的巨大杀伤力。工业标准机群采用量产的标准化部件构成高性能计算机系统,极大地提高了性能价格比,从科学计算开始逐渐应用到各个领域。
浪潮北京公司服务器产品经理丁昱对《中国电子报》记者说,事实上,中国机群发展进入了一个瓶颈期,多数稍具技术实力的厂商都可以设计出计算速度上万亿次的高性能计算机。可以说,在充足的资金前提下,设计一套进入全球前十名的高性能机群系统,并非难事。在科学计算方面,唯一的问题因素是资金。浪潮基于弹性部署理念的计算能力、数据通信、输入输出非单极优化的MABS体系结构,为高性能商用服务器系统实现技术突破奠定了理论基础。
曙光公司天潮系列产品经理曹振南告诉《中国电子报》记者,机群的优势主要体现在更高的性能价格比,机群系统已经成为高性能计算机的发展方向,世界上TOP500排行榜的高性能计算机系统绝大多数是机群系统;更高的可扩展性,机群系统可以通过原有预留的扩展接口进行无缝的扩展;更高的可管理性,通常管理一个机群系统要比管理一个小型机系统要简单得多;更高的系统鲁棒性(健壮或强壮),机群系统都是采用了标准的硬件设备,容易采购,同时也较容易维护,有更多国内厂商支持;对应用系统的更多的支持,机群系统可以支持大量的操作系统并且可以支持多种操作系统,也支持32位和64位的软件系统,在机群系统上运行的软件是小型机系统的成百上千倍。
关键在应用
20世纪90年代以来,中国在高性能计算机的研制方面已经取得了较好的成绩,掌握了研制高性能计算机的一些关键技术,参与高性能计算机研制的单位已经从科研院所发展到企业界,有力地推动了高端计算的发展。中国的高性能计算环境已得到重大改善,总计算能力与发达国家的差距正逐步缩小。
随着曙光、神威、银河、联想、浪潮、同方等一批知名产品的出现,中国成为继美、日之后第三个具备高端计算机系统研制能力的国家,被誉为世界未来高性能计算市场的“第三股力量”。在国家相关部门的不断支持下,一批国产超级计算机相继面世,大量的高性能计算系统进入教育、科研、石油、金融等领域,尤其值得一提的是曙光4000A在全球TOP500中排名进入前十,并成功应用于国家网格主节点之一――上海超级计算中心。
但是,从总体上讲,中国高性能计算应用的研究与开发明显滞后于高性能计算机的发展,应用的并行度普遍在百十量级,应用到更大规模的很少(并非没有需求)。
浪潮丁昱告诉《中国电子报》记者,中国的高性能计算发展最大的障碍是品牌的障碍和应用的障碍。这和中国高性能发展起步较慢有关系。年限比较短,应用的经验比较少。但随着国内高性能计算的快速发展,这方面的缺陷会得到很大改善。但随着越来越多的用户开始采用高性能计算机,应用软件的发展后滞明显严重。另外,一些用户对传统RISC小型机存在使用习惯和品牌偏好,接受Linux机群需要厂商做大量的工作。
曙光曹振南在接受《中国电子报》记者采访时称,中国高端计算应用的研究与开发明显滞后于高端计算机的发展,应用到大规模的很少。高端应用软件的开发和高效并行算法的研究尚不能与高端计算机发展同步,在一定程度上存在为计算机“配”软件的思想。对应用的投入远远不够,应用研发的力量薄弱且分散,缺乏跨学科的综合型人才,从事高端应用软件研发的单位很少,没有良好的、相互交流的组织渠道等。还有就是政府在采购中依然选择国际品牌,缺乏对国产品牌的支持。
联想高性能服务器事业部总经理祝明发则认为,中国高性能计算生存的关键在应用。他谈到IBM、惠普、Sun等公司的高性能计算业务在商业市场的比例为90%,而中国的高性能计算在商业计算市场开拓方面仍存在很大差距。从来看,中国的联想、曙光、浪潮等厂家完全有能力做出运算速度达到40万亿次的超级计算机,但关键就是有没有找到应用需求。比如,在科学计算中独树一帜的向量计算,因为成本高、商用计算能力不强而仅停留在科学计算的狭窄领域。
高性能计算_高性能计算 -超越摩尔定律
提及摩尔定律,作为计算机发展的第一定律一直在引领IT产业的前行。不过随着多核技术的发展和应用,目前摩尔定律在面临挑战的同时,在某些领域已经被超越。例如在日益普及的高性能计算(HPC)中。那为何摩尔定律会首先在高性能计算领域被超越?这之中又隐含着怎样的产业趋势?
首先从代表全球高性能计算水平和趋势的全球高性能计算TOP500近几年性能发展的趋势看,无论是最大性能(全球排名第一的系统)、还是最小性能(全球排名最后)和平均性能,其发展曲线的速度是基本一致的。但与摩尔定律的发展曲线相比,则明显处于陡势的增长态势。这说明这两年来,高性能计算性能和应用的发展速度已经超越了摩尔定律。熟悉摩尔定律的人都知道,摩尔定律有三种解释。一种是集成电路芯片上所集成的电路的数目,每隔18个月就翻一番;第二种是微处理器的性能每隔18个月提高一倍,而价格下降一半;第三种解释是用一个美元所能买到的电脑性能,每隔18个月翻两番。这三种解释中业内引用最多的是第一种。但具体到高性能计算,笔者更愿意用第二或者第三种来解释。
按理说,随着高性能计算性能的不断提升和系统的日益庞大,高性能计算用户无论在初期的采购搭建系统,还是后期的使用中的成本都会大幅的增加,在经济危机的特殊时期,高性能计算如此大的TCO会导致用户的减少和整体性能的下降才对。但前不久发布的全球高性能计算TOP500证明,增长的势头未减,这除了市场和用户的需求外,更在于处理器厂商采用新的技术,在性能提升的同时,让用户以更低的成本享受到更高、更多的计算性能。从这个意义上看,摩尔定律在被延续的同时也正在被超越,即在高性能计算领域,用户性能/投入比远远大于摩尔定律。当然这主要得益于处理器制程、架构技术、多核技术、节能技术、软件优化和快速部署等。
例如从制程和核数上看,最新的全球高性能计算TOP500排名显示,45纳米已经占据了绝对的主流。而多核也达到了全球TOP500的2/3。从部署的速度看,AMD刚刚发布不久的6核就已经有两套进入TOP500中。而英特尔今年3月才正式发布的新的Nehalem多核架构的高性能计算系统更有33套(基于这个处理器的系统)进入TOP500,其中有两套在TOP20里。快速的部署给用户带来的是最新技术和性能的获得。
当然对于用户而言,多核并非是关键,重要的是如何充分发挥多核的效能。这就需要相关的平台技术和软件优化。例如在高性能计算领域,业内都听说过“半宽板”这个标准。这个“半宽板”标准其实是英特尔在几年前提出的,半宽的小板在加高计算密度的同时,节约了很多复用的部件,在加强高性能计算的密度同时,配合散热的技术设计,可以提供更多的计算能力同时降低能耗。这就引出了一个新的发展方向,即高性能计算未来发展就是能耗更多被用于计算性能的提高,而不是散热。此外,就是SSD(固态硬盘),它可以在大幅提高高性能计算系统可靠性和I/O性能的同时,还可以降低功耗。而软件优化更是高性能计算中重中之重的部分,编译器、函数库以及MPI库,所有这些可以帮助ISV能够把多核处理器的计算性能充分发挥出来。
由此来看,在高性能计算领域,单纯的处理器已经不能满足市场和用户的需求,它们需要的是高性能计算平台级的解决技术及方案。这也是为什么在去年全球高性能计算TOP500开始引入能效的主要原因。
说到能效,笔者早就听说在业内有个与摩尔定律同样重要的“基辛格规则”。它是以处理器业界闻名的英特尔首席技术官帕特・基辛格名字命名的。该规则的主旨是今后处理器的发展方向将是研究如何提高处理器能效,并使得计算机用户能够充分利用多任务处理、安全性、可靠性、可管理性和无线计算方面的优势。如果说“摩尔定律”是以追求处理性能为目标,而“基辛格规则”则是追求处理器的能效,这规则目前至少在高性能计算领域已经得到了验证,而它由此带来的是摩尔定律的被超越,即用户将会在更短的周期,以更低的价格获得更高的能效。
高性能计算_高性能计算 -推动发展
人类从人力推算到高性能计算机,倾注了无数人大量的心血和努力。对于现代天气预报和气象研究工作,高性能计算机则占据了极其重要的位置。
气象工作离不开高性能计算机
随着社会经济的发展,政府、社会和公众对气象预报和服务提出了更高的要求,特别是一些特殊气象保障任务需要预报员提供定点、定时、定量的精细气象预报和服务。而对于现代天气预报而言,为确保其实施的实效性和运行的稳定性,必然要求建立在数值预报基础之上,但数值模式普遍具有计算规模巨大、高精度等特点,于是高性能计算机便成为了现代气象研究的中流砥柱。
数值天气预报水平的高低已成为衡量世界各国气象事业现代化程度的重要标志。美国国家大气研究中心与科罗拉多大学合作,采用了IBM蓝色基因超级计算机来仿真海洋、天气和气候现象,并研究这些现象对农业生产、石油价格变动和全球变暖等问题的影响。日本科学家研制成功了代号为“地球模拟器”的超级计算机,其主要目的就是要提供准确的全球性天气预报,使各个国家和地区更好地防御暴风雪、寒流和酷暑期的到来。
我国是一个幅员辽阔的国家,在气候上呈现多层次、多样性、多变性等特点,尤其是近几年洪涝、干旱等自然灾害比较严重,及时、准确的天气预报逐步受到重视,因此随着地区气象市场的逐步成熟,更高效率的高性能计算机成为了人们关注的对象。作为国产服务器第一品牌的曙光公司,一直以来就非常关注气象领域对高性能计算机的需求。
由于采用了软硬件一体化设计,曙光气象专用机在硬件平台上直接移植了目前在中尺度数值天气预报领域处于领先地位的NCA MM5系统,这套系统每天自动定时定点进行业务系统预报,从数据导入到气象绘图的整个流程自动完成,不需要人工干预;用户可以随时监控整个系统的运行,大大节约了操作的时间。甚至不需要任何计算机系统知识的培训,用户就可以快速掌握整个预报系统。而且该系统既可以作为业务预报系统,又可以作为气象研究和测试的平台,一机多用,用户可以根据自己的需要进行参数设定和算法调试。系统还提供了数据保存功能,使得用户可以对以往一个月内不满意的预报进行重新计算和分析,最大限度地满足了气象部门准确及时预报的需求。
气象工作离不开高性能计算机,而且每隔三四年就有一次主机的更新,速度还要提高一个数量级。在前10年,我们还只能选择国外品牌高性能计算机,而近几年以曙光为代表的高性能计算机已经明显提升了气象服务的综合实力。曙光机在我国气象领域取得了非常广泛的应用,大大促进了中国气象科技水平的提升,为老百姓的日常出行和众多国家重大工程提供了强有力的保障。从日常天气预报到大型气候研究、从陆地到海洋、从地面水文气象到太空天气等领域,都活跃着曙光高性能计算机的身影。