语音识别_语音识别芯片 -简介
语音识别芯片也叫语音识别IC,与传统的语音芯片相比,语音识别芯片最大的特点就是能够语音识别,它能让机器听懂人类的语音,并且可以根据命令执行各种动作,如眨眼睛、动嘴巴(智能娃娃)。除此之外,语音识别芯片还具有高品质、高压缩率录音放音功能,可实现人机对话。
语音识别芯片所涉及的技术包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
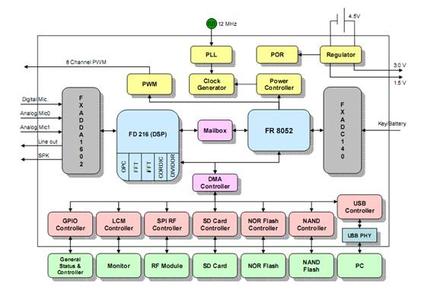
语音识别控制系统结构图
语音识别_语音识别芯片 -语音识别芯片分类
按照使用者的限制而言,语音识别芯片可以分为特定人语音识别芯片和非特定人语音识别芯片。
特定人语音识别特定人语音识别芯片是针对指定人的语音识别,其他人的话玩具不识别,须先把使用者的语音参考样本存入当成比对的资料库,即特定人语音识别在使用前必须要进行语音训练,一般按照机器提示训练2遍语音词条即可使用。
非特定人语音识别非特定人语音识别是不用针对指定的人的识别技术,不分年龄、性别,只要说相同语言就可以,应用模式是在产品定型前按照确定的十几个语音交互词条,采集200人左右的声音样本,经过PC算法处理得到交互词条的语音模型和特征数据库,然后烧录到芯片上。应用这种芯片的机器(智能娃娃、电子宠物、儿童电脑)就具有交互功能了。
非特定人语音识别应用有的是基于音素的算法,这种模式下不需要采集很多人的声音样本就可以做交互识别,但是缺点是识别率不高,识别性能不稳定。
按照说话方式的连续性,语音识别芯片又可分为非连续语音识别和连续语音识别。
对于非连续语音来说,识别所说的每一个字必须分开辨认,要求说完每个字后都要停顿。
连续语音识别连续语音识别可以一般自然流利的说话方式来进行人性化的语音识别,但由于关系到相连音的问题,很难达到好的辨认效果。
语音识别_语音识别芯片 -基本原理
嵌入式语音识别系统都采用了模式匹配的原理。录入的语音信号首先经过预处理,包括语音信号的采样、反混叠滤波、语音增强,接下来是特征提取,用以从语音信号波形中提取一组或几组能够描述语音信号特征的参数。特征提取之后的数据一般分为两个步骤,第一步是系统“学习”或“训练”阶段,这一阶段的任务是构建参考模式库,词表中每个词对应一个参考模式,它由这个词重复发音多遍,再经特征提取和某种训练中得到。第二是“识别”或“测试”阶段,按照一定的准则求取待测语音特征参数和语音信息与模式库中相应模板之间的失真测度,最匹配的就是识别结果。
语音识别_语音识别芯片 -语音识别系统的结构
一个完整的基于统计的语音识别系统可大致分为三部分:
(1)语音信号预处理与特征提取;(2)声学模型与模式匹配;(3)语言模型与语言处理
选择识别单元是语音识别研究的第一步。语音识别单元有单词(句)、音节和音素三种,具体选择哪一种,由具体的研究任务决定。
单词(句)单元广泛应用于中小词汇语音识别系统,但不适合大词汇系统,原因在于模型库太庞大,训练模型任务繁重,模型匹配算法复杂,难以满足实时性要求。
音节单元多见于汉语语音识别,主要因为汉语是单音节结构的语言,而英语是多音节,并且汉语虽然有大约1300个音节,但若不考虑声调,约有408个无调音节,数量相对较少。因此,对于中、大词汇量汉语语音识别系统来说,以音节为识别单元基本是可行的。
音素单元以前多见于英语语音识别的研究中,但目前中、大词汇量汉语语音识别系统也在越来越多地采用。原因在于汉语音节仅由声母(包括零声母有22个)和韵母(共有28个)构成,且声韵母声学特性相差很大。实际应用中常把声母依后续韵母的不同而构成细化声母,这样虽然增加了模型数目,但提高了易混淆音节的区分能力。由于协同发音的影响,音素单元不稳定,所以如何获得稳定的音素单元,还有待研究。 语音识别一个根本的问题是合理的选用特征。特征参数提取的目的是对语音信号进行分析处理,去掉与语音识别无关的冗余信息,获得影响语音识别的重要信息,同时对语音信号进行压缩。在实际应用中,语音信号的压缩率介于10-100之间。语音信号包含了大量各种不同的信息,提取哪些信息,用哪种方式提取,需要综合考虑各方面的因素,如成本,性能,响应时间,计算量等。非特定人语音识别系统一般侧重提取反映语义的特征参数,尽量去除说话人的个人信息;而特定人语音识别系统则希望在提取反映语义的特征参数的同时,尽量也包含说话人的个人信息。
线性预测(LP)分析技术是目前应用广泛的特征参数提取技术,许多成功的应用系统都采用基于LP技术提取的倒谱参数。但线性预测模型是纯数学模型,没有考虑人类听觉系统对语音的处理特点。
Mel参数和基于感知线性预测(PLP)分析提取的感知线性预测倒谱,在一定程度上模拟了人耳对语音的处理特点,应用了人耳听觉感知方面的一些研究成果。实验证明,采用这种技术,语音识别系统的性能有一定提高。从目前使用的情况来看,梅尔刻度式倒频谱参数已逐渐取代原本常用的线性预测编码导出的倒频谱参数,原因是它考虑了人类发声与接收声音的特性,具有更好的鲁棒性(Robustness)。
也有研究者尝试把小波分析技术应用于特征提取,但目前性能难以与上述技术相比,有待进一步研究。
声学模型通常是将获取的语音特征使用训练算法进行训练后产生。在识别时将输入的语音特征同声学模型(模式)进行匹配与比较,得到最佳的识别结果。
声学模型是识别系统的底层模型,并且是语音识别系统中最关键的一部分。声学模型的目的是提供一种有效的方法计算语音的特征矢量序列和每个发音模板之间的距离。声学模型的设计和语言发音特点密切相关。声学模型单元大小(字发音模型、半音节模型或音素模型)对语音训练数据量大小、系统识别率,以及灵活性有较大的影响。必须根据不同语言的特点、识别系统词汇量的大小决定识别单元的大小。
以汉语为例:
汉语按音素的发音特征分类分为辅音、单元音、复元音、复鼻尾音四种,按音节结构分类为声母和韵母。并且由音素构成声母或韵母。有时,将含有声调的韵母称为调母。由单个调母或由声母与调母拼音成为音节。汉语的一个音节就是汉语一个字的音,即音节字。由音节字构成词,最后再由词构成句子。
汉语声母共有22个,其中包括零声母,韵母共有38个。按音素分类,汉语辅音共有22个,单元音13个,复元音13个,复鼻尾音16个。
目前常用的声学模型基元为声韵母、音节或词,根据实现目的不同来选取不同的基元。汉语加上语气词共有412个音节,包括轻音字,共有1282个有调音节字,所以当在小词汇表孤立词语音识别时常选用词作为基元,在大词汇表语音识别时常采用音节或声韵母建模,而在连续语音识别时,由于协同发音的影响,常采用声韵母建模。
基于统计的语音识别模型常用的就是HMM模型λ(N,M,π,A,B),涉及到HMM模型的相关理论包括模型的结构选取、模型的初始化、模型参数的重估以及相应的识别算法等。
语言模型包括由识别语音命令构成的语法网络或由统计方法构成的语言模型,语言处理可以进行语法、语义分析。
语言模型对中、大词汇量的语音识别系统特别重要。当分类发生错误时可以根据语言学模型、语法结构、语义学进行判断纠正,特别是一些同音字则必须通过上下文结构才能确定词义。语言学理论包括语义结构、语法规则、语言的数学描述模型等有关方面。目前比较成功的语言模型通常是采用统计语法的语言模型与基于规则语法结构命令语言模型。语法结构可以限定不同词之间的相互连接关系,减少了识别系统的搜索空间,这有利于提高系统的识别。
语音识别_语音识别芯片 -语音识别系统设计
系统硬件设计对于嵌入式系统而言,语音识别硬件组成要考虑很多其它因素,首先由于成本的限制,一般使用定点DSP,这意味着算法的复杂度受到限制;其次,对产品化有各种严格的限制,这就需要一个高度集成的硬件DSP,因此最理想的硬件组成是系统级的芯片。
一般采用的是一个16位结构的微控制器,将MCU、A/D、D/A、RAM、ROM集成在一块芯片上,具有很高的集成度。同时具有较高运算速度的16×16位的乘法语音和内积运算指令,CPU最高可达时钟49MHz,因此在复杂的数字信号处理方面既非常便利又比专用的DSP芯片便宜得多。并具有12位ADC,和14位DAC保证音频精度,配置带自动增益控制(AGC)的麦克风输入方式,为语音处理带来了极大的方便。既具有体积小、集成度高、可靠性好的特点,又具有较强的中断处理能力、高性能的价格比和功能强、效率高的指令系统及低功耗、低电压的特点,所以非常适合用于嵌入式语音识别系统。
以SR160X为核心的嵌入式语音识别系统硬件的电路系统,主要包括麦克风输入电路、ADC、DAC、功放输出电路、键盘电路和各种通信电路等,语音保存到SPI Flash存储器中。
非特定人语音识别要经过语音训练后才能识别,将语音训练过程中建立的参考模式库和从待识别语音信号中提取的特征参数都存放在外扩的SPI Flash中,这样就可以保证掉电后重新开机继续识别。语音识别系统软件主程序由语音训练程序、语音识别程序、语音播放程序、中断程序、初始化程序等子程序组成。由于嵌入式平台存储资源少、实时性要求高的特点,因此算法在保证识别效果的前提下要尽可能优化。
软件包括A/D变换、预加重、分帧和加窗、端点检测、特征参数提取、放宽端点限制的DTW算法,最后识别结果输出。
在应用层软件考虑到用户的实际需求,增加了能快速开发的虚拟软件开发技术,能快速完成产品。