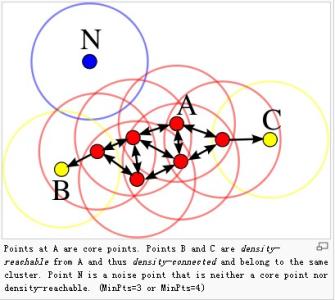
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
DBSCAN算法描述:
输入: 包含n个对象的数据库,半径e,最少数目MinPts;
输出:所有生成的簇,达到密度要求。
(1)Repeat
(2)从数据库中抽出一个未处理的点;
(3)IF抽出的点是核心点 THEN 找出所有从该点密度可达的对象,形成一个簇;
(4)ELSE 抽出的点是边缘点(非核心对象),跳出本次循环,寻找下一个点;
(5)UNTIL 所有的点都被处理。
DBSCAN对用户定义的参数很敏感,细微的不同都可能导致差别很大的结果,而参数的选择无规律可循,只能靠经验确定。
描述二:
DBSCAN(基于密度的空间成群应用以噪声)是a 数据成群 马丁・ Ester, Hans彼得Kriegel, Jörg沙磨机和Xiaovei提议的算法xui1996. 因为它从对应的结的估计的密度发行开始,发现一定数量的群它是密度基群算法。 domenica Arlia和Massimo提出DBSCAN算法的parallelisation Coppola2001.
内容
1 步2 伪码3 好处4 缺点5 参考
dbscan_DBSCAN -步骤
DBScan要求二个参量: ε (eps)和极小的点(minPts)。 它开始以unvisited的一个任意出发点。 它在出发点的距离eps之内发现所有附近点。
如果附近点的数量是大于或等于minPts,群被形成。 出发点和它的邻居增加到这群,并且出发点被标记为visited。 然后递归评估所有未被标记为visited的该群成员,从而对群进行扩展。
如果邻居的数量比minPts是较少,则该点暂时被标记作为噪声。
如果群充分地被扩展(群内的所有点被标记为visited),然后重复的算法去处理unvisited点。
dbscan_DBSCAN -伪码
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。它采用迭代查找的方法,通过迭代地查找所有直接密度可达的对象,找到各个所有密度可达的对象,具体算法描述如下:
(1)检测数据库中尚未检查过的对象p,如果p未被处理(归为某个簇或者标记为噪声),则检查其邻域,若包含的对象数不小于,建立新簇C,将中所有点加入C;
(2)对C中所有尚未被处理的对象q,检查其邻域,若中至少包含个对象,则将中未归入任何一个簇的对象加入C;
(3)重复步骤2),继续检查C中未处理的对象,知道没有新的对象加入当前簇C;
(4)重复步骤1)~3),直到所有对象都归入了某个簇或标记为噪声。
其伪代码描述如下:
输入:数据对象集合D,半径Eps,密度阈值MinPts
输出:聚类C
DBSCAN(D, Eps, MinPts)
Begin
init C=0; //初始化簇的个数为0
for each unvisited point p in D
mark p as visited; //将p标记为已访问
N = getNeighbours (p, Eps);
if sizeOf(N) < MinPts then
mark p as Noise; //如果满足sizeOf(N) < MinPts,则将p标记为噪声
else
C= next cluster; //建立新簇C
ExpandCluster (p, N, C, Eps, MinPts);
end if
end for
End
其中ExpandCluster算法伪码如下:
ExpandCluster(p, N, C, Eps, MinPts)
add p to cluster C; //首先将中所有点加入C
for each point p’ in N
mark p as visited;
N’ = getNeighbours (p’, Eps); //对N邻域内的所有点在进行半径检查
if sizeOf(N’) >= MinPts then
N = N+N’; //如果大于MinPts,就扩展N的数目
end if
if p’ is not member of any cluster
add p’ to cluster C; //将p' 加入簇C
end if
end for
End ExpandCluster
dbscan_DBSCAN -好处
1. DBScan在数据不要求您知道群的数量演绎。 此与K手段比较。
2. DBScan没有偏心往特殊群形状或大小。 此与K手段比较。
3. 如果需要DBScan对噪声是有抵抗性并且为噪声提供手段过滤。
dbscan_DBSCAN -缺点
1. DBScan不很好反应高尺寸数据。 当幅员增加,因此做使它的点之间的相对距离更加坚硬执行密度分析。
2. DBScan不很好反应数据集以变化的密度。
dbscan_DBSCAN -参考
“一种基于密度的算法为在大空间数据库发现群以噪声”。第2次国际会议记录关于KDD的AAAI Press。 检索 2007-10-15.“实验在平行成群与DBSCAN”。欧洲同水准2001年: 并行处理: 第7国际欧洲同水准会议曼彻斯特,英国2001年8月28-31,行动Springer柏林。 检索2004-02-19.