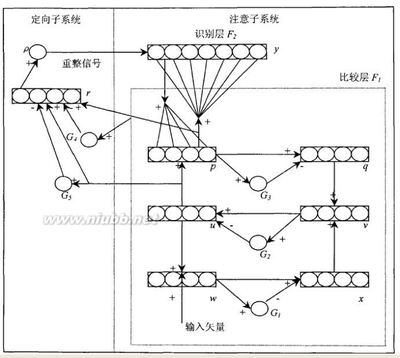
人工神经网路
学习是要透过我们的头脑,因而研究大脑神经细胞的运作,可以帮助我们了
解学习在脑神经是如何完成的,进而可以模拟神经细胞的运作以达到類似学习的
功能。据估计人脑约有一千亿(1011)个神经细胞,每个神经细胞约有一千(103)
根連结与其它神经细胞相連,因此人脑中约有一百万亿(1014)根連结,形成一
个高度連结网狀的神经网路(neuralnetwork)。科学家们相信:人脑的信息处理工作即是透过这些連结來完成的 [葉怡成1993]。
神经细胞的形狀与一般的细胞有很大的不同,它包括:细胞体(soma):神经
细胞中呈核狀的处理机构;轴突(axon):神经细胞中呈轴索狀的输送机构;树狀
突(dendrites):神经细胞中呈树枝狀的输出入机构;与突触(synapse):树狀突上呈点狀的連结机构。根据神经学家的研究发现:当神经细胞透过神经突触与树
狀突从其它神经元输入脉波讯号后,经过细胞体处理,产生一个新的脉波讯号。
如果脉波讯号够强,将产生一个约千分之一秒100 毫伏的脉波讯号。这个讯号再
经过轴突传送到它的神经突触,成为其它神经细胞的输入脉波讯号。如果脉波讯
号是经过兴奋神经突触(excitatorysynapse),则会增加脉波讯号的速率;相反的,如果脉波讯号是经过抑制神经突触(inhibitorysynapse),则会减少脉波讯号的速率。因此,脉波讯号的速率是同时取决于输入脉波讯号的速率,以及神经突触的强度。而神经突触的强度可视为神经网路储存信息之所在,神经网路的学习即在调整神经突触的强度。
類神经网路(artificial neuralnetworks),或译为人工神经网路,则是指模仿生物神经网路的信息处理系统,它是由许多人工神经细胞(又称为類神经元、人工
神经元、与处理单元)所组成,人工神经细胞,如图15-18 所示。本节将探讨最
古老、也是最基本的類神经网路模式——感知机(perceptron),它是1957 年由
Rosenblatt 所提出。感知机的基本原理是由脑神经模型所启发,特别是1943 年
McCulloch 和Pitts 所共同提出的數学模型,通称为MP 模型,以及Hebb 所提出
的神经元学习规则,通称为Hebb 学习规则。
MP 模型的要点如下:(1) 神经元的狀态为兴奋或抑制二者之一,可用0 表示
抑制狀态,用1 表示兴奋狀态。(2) 神经元与其它神经元间的連结,可用一个加
权值(weight)表示連结强度。(3) 神经元的狀态会经由連结输出到其它神经元,
成为其输入。(4) 神经元的狀态受其相連的神经元制约,当从这些神经元传來的
输入讯号(即该神经元的狀态)经过連结以加权乘积和计算所得的值大于某门坎
值(threshold)时,神经元的狀态将成为兴奋狀态;否则,为抑制狀态。以公式
表示为:
其中,Wij 为神经元 i 与神经元 j间的連结强度,即連结加权值,Xi 为从神经元
i 传來的输入讯号,θ j 为神经元 j的门坎值,f 为转换函數(transfer function),
通常为一个阶梯函數(step function),其定义如下:
(5) 神经网路的学习过程即在调整神经元间的連结强度,即連结加权值。而Hebb
学习规则的要点如下:调整兩个神经元间連结加权值的原则为当第 i 个与第 j个
神经元同时处于兴奋狀态时,则其連结应当加强。Hebb 学习规则与动物行为科学
中的条件反射学說一致。
感知机的网路架构有兩种,如图15-19 所示,一含有隐藏层,另一种则无。
它们皆包括有输入层与输出层。输入层用以表现网路的输入变數,其处理单元數
目依问题而定,使用线性转换函數 f (X ) =X,亦即输入值即为输出值。隐藏层用
以表现输入处理单元间的交互影响,其处理单元數目通常以实验方式决定其最佳
數目,隐藏层可以有一层以上,也可以没有。输出层用以表现网路的输出变數,
其处理单元的數目依问题而定。输入变數形成一个输入向量,输出变數形成一个
输出向量。
图15-19 感知机网路架构
我们以简单的无隐藏层的感知机來說明類神经网路的学习机制。在神经网路
的学习中,样本资料以數值形式表示,每一个样本都包含有输入向量X =[X1, X2, …,Xn] 和目标输出向量T =[T1, T2, …,Tm]。一般将所有的样本资料随机分为兩部分,一部分为训練样本(trainingsamples),另一部分为测试样本(testsamples)。首先,将感知机初始化,即给定每一个連结一个随机亂數值。然后将一个训練样本的输入向量X输入感知机中,并利用公式 (15-6.1) 和 (15-6.2) 计算其推論输出向量Y=[Y1, Y2, …,Ym]。此网路利用由训練样本输入之目标输出向量T和透过网路推得的推論输出向量Y相较之下的误差,作为修正連结中的加权值的依据,以从训練样本中学习隐含的输入向量与输出向量之对应关系。差距量 δ j计算公式如下:
δ j=T j-Yj(15-6.4)
若 δ j > 0,表示推論输出变數Y j小于目标输出变數T j,根据公式 (15-6.2) 得知連结加权值W ij 太小,故应增加Wij 的值。相反的,若 δ j < 0,表示推論输出变數Y j大于目标输出变數T j,根据公式 (15-6.2) 得知連结加权值W ij 太大,故应减少Wij 的值。加权值之改变量公式可表达如下:
△W ij =ηδXi(15-6.5)
其中,η 为学习速率(learning rate),控制每次加权值改变量的幅度。公式(15-6.5)中,加权值之改变量也应与输入讯号 Xi成正比,因为讯号越大,其修正量也应越大。同理,输出单元的门坎值改变量公式计算如下:
△θj=-ηδj(15-6.6)
類神经网路的学习过程,通常以一次一个训練样本的方式进行,直到学习完
所有的训練样本为止,称为一个学习循环(learningcycle)。加权值与门坎值的修正可采用逐步学习(step learning)或批次学习(batchlearning),逐步学习是每输入一个训練样本,计算其加权值与门坎值的修正量后立即修改。而批次学习是在一个学习循环后,计算所有训練样本的加权值与门坎值的修正量后,依下列公式计算其整体修正量而修改之。
其中,m 表示第m 个样本,而N为训練样本总數。一个网路可以将训練样本反复
学习多个循环,直到满足终止条件为止。而终止条件可订为执行一定數目的学习
循环或是网路已收敛(即误差不再有明显变化)。感知机的误差程度可用总错误率
E 定义如下:
学习过程:
1. 设定网路參數。
2.以均布随机亂數设定加权值矩阵W,与偏权值向量初始值。
3. 输入一个训練样本的输入向量 X 与目标输出向量T。
4. 计算推論输出向量 Y。
5. 计算差距量 δ。
6. 计算加权值矩阵修正量ΔW,以及偏权值向量修正量 Δθ。
7. 更新加权值矩阵W,以及偏权值向量 θ。
8. 重复步骤3 至步骤7 直至到收敛或执行一定數目的学习循环。
回想过程:
1. 设定网路參數。
2. 讀入加权值矩阵W 与偏权值向量 θ。
3. 输入一个测试样本的输入向量 X。
4. 计算推論输出向量Y。
?/P>
一些公式是用图片的形式表达的,传不上来.参考下列网址:http://blog.sina.com.cn/s/blog_4910d7c501000ch4.html