线性回归数据(全国各地区能源消耗量与产量)来源,可点击协会博客数据挖掘栏:国泰安数据服务中心的经济研究数据库。
1.1 数据预处理
数据预处理包括的内容非常广泛,包括数据清理和描述性数据汇总,数据集成和变换,数据归约,数据离散化等。本次实习主要涉及的数据预处理只包括数据清理和描述性数据汇总。一般意义的数据预处理包括缺失值填写和噪声数据的处理。于此我们只对数据做缺失值填充,但是依然将其统称数据清理。
1.1.1 数据导入与定义
单击“打开数据文档”,将xls格式的全国各地区能源消耗量与产量的数据导入SPSS中,如图1-1所示。
图1-1导入数据
导入过程中,各个字段的值都被转化为字符串型(String),我们需要手动将相应的字段转回数值型。单击菜单栏的“”-->“ ”将所选的变量改为数值型。如图1-2所示:
图1-2定义变量数据类型
1.1.2 数据清理
数据清理包括缺失值的填写和还需要使用SPSS分析工具来检查各个变量的数据完整性。单击“”-->“ ”,将检查所输入的数据的缺失值个数以及百分比等。如图1-3所示:
图1-3缺失值分析
能源数据缺失值分析结果如表1-1所示:
单变量统计 | |||||||
N | 均值 | 标准差 | 缺失 | 极值数目a | |||
计数 | 百分比 | 低 | 高 | ||||
能源消费总量 | 30 | 9638.50 | 6175.924 | 0 | .0 | 0 | 1 |
煤炭消费量 | 30 | 9728.99 | 7472.259 | 0 | .0 | 0 | 2 |
焦炭消费量 | 30 | 874.61 | 1053.008 | 0 | .0 | 0 | 2 |
原油消费量 | 28 | 1177.51 | 1282.744 | 2 | 6.7 | 0 | 1 |
汽油消费量 | 30 | 230.05 | 170.270 | 0 | .0 | 0 | 1 |
煤油消费量 | 28 | 45.40 | 66.189 | 2 | 6.7 | 0 | 4 |
柴油消费量 | 30 | 392.34 | 300.979 | 0 | .0 | 0 | 2 |
燃料油消费量 | 30 | 141.00 | 313.467 | 0 | .0 | 0 | 3 |
天然气消费量 | 30 | 19.56 | 22.044 | 0 | .0 | 0 | 2 |
电力消费量 | 30 | 949.64 | 711.664 | 0 | .0 | 0 | 3 |
原煤产量 | 26 | 9125.97 | 12180.689 | 4 | 13.3 | 0 | 2 |
焦炭产量 | 29 | 1026.49 | 1727.735 | 1 | 3.3 | 0 | 2 |
原油产量 | 18 | 1026.48 | 1231.724 | 12 | 40.0 | 0 | 0 |
燃料油产量 | 25 | 90.72 | 134.150 | 5 | 16.7 | 0 | 3 |
汽油产量 | 26 | 215.18 | 210.090 | 4 | 13.3 | 0 | 2 |
煤油产量 | 20 | 48.44 | 62.130 | 10 | 33.3 | 0 | 0 |
柴油产量 | 26 | 448.29 | 420.675 | 4 | 13.3 | 0 | 1 |
天然气产量 | 20 | 29.28 | 49.391 | 10 | 33.3 | 0 | 3 |
电力产量 | 30 | 954.74 | 675.230 | 0 | .0 | 0 | 0 |
表2-1 能源消耗量与产量数据缺失值分析 | |||||||
表1-1 能源消耗量与产量数据缺失值分析
SPSS提供了填充缺失值的工具,点击菜单栏“ ”-->“”,即可以使用软件提供的几种填充缺失值工具,包括序列均值,临近点中值,临近点中位数等。结合本次实习数据的具体情况,我们不使用SPSS软件提供的替换缺失值工具,主要是手动将缺失值用零值来代替。
1.1.3 描述性数据汇总
描述性数据汇总技术用来获得数据的典型性质,我们关心数据的中心趋势和离中趋势,根据这些统计值,可以初步得到数据的噪声和离群点。中心趋势的量度值包括:均值(mean),中位数(median),众数(mode)等。离中趋势量度包括四分位数(quartiles),方差(variance)等。
SPSS提供了详尽的数据描述工具,单击菜单栏的“ ”-->“”-->“”,将弹出如图2-4所示的对话框,我们将所有变量都选取到,然后在选项中勾选上所希望描述的数据特征,包括均值,标准差,方差,最大最小值等。由于本次数据的单位不尽相同,我们需要将数据标准化,同时勾选上“将标准化得分另存为变量”。
图1-4 描述性数据汇总
得到如表1-2所示的描述性数据汇总。
N | 极小值 | 极大值 | 均值 | 标准差 | 方差 | |
能源消费总量 | 30 | 911 | 26164 | 9638.50 | 6175.924 | 38142034.412 |
煤炭消费量 | 30 | 332 | 29001 | 9728.99 | 7472.259 | 55834651.378 |
焦炭消费量 | 30 | 19 | 5461 | 874.61 | 1053.008 | 1108824.853 |
原油消费量 | 30 | 0 | 5555 | 1099.01 | 1273.265 | 1621202.562 |
汽油消费量 | 30 | 18 | 771 | 230.05 | 170.270 | 28991.746 |
煤油消费量 | 30 | 0 | 262 | 42.37 | 64.896 | 4211.520 |
柴油消费量 | 30 | 27 | 1368 | 392.34 | 300.979 | 90588.441 |
燃料油消费量 | 30 | 0 | 1574 | 141.00 | 313.467 | 98261.261 |
天然气消费量 | 30 | 1 | 106 | 19.56 | 22.044 | 485.947 |
电力消费量 | 30 | 98 | 3004 | 949.64 | 711.664 | 506464.953 |
原煤产量 | 30 | 0 | 58142 | 7909.17 | 11741.388 | 1.379E8 |
焦炭产量 | 30 | 0 | 9202 | 992.28 | 1707.998 | 2917256.193 |
原油产量 | 29 | 0 | 4341 | 637.12 | 1085.379 | 1178048.432 |
燃料油产量 | 30 | 0 | 497 | 75.60 | 126.791 | 16075.971 |
汽油产量 | 30 | 0 | 1032 | 186.49 | 208.771 | 43585.122 |
煤油产量 | 30 | 0 | 219 | 32.30 | 55.394 | 3068.535 |
柴油产量 | 30 | 0 | 1911 | 388.52 | 420.216 | 176581.285 |
天然气产量 | 30 | 0 | 164 | 19.52 | 42.371 | 1795.341 |
电力产量 | 30 | 97 | 2536 | 954.74 | 675.230 | 455935.003 |
有效的 N (列表状态) | 29 |
表1-2 描述性数据汇总
标准化后得到的数据值,以下的回归分析将使用标准化数据。如图1-5所示:
图1-5 数据标准化
我们还可以通过描述性分析中的“”来得到各个变量的众数,均值等,还可以根据这些量绘制直方图。我们选取个别变量(能源消费总量)的直方图,可以看到我们因变量基本符合正态分布。如图1-6所示:
图1-6能源消费总量
1.2 回归分析
我们本次实验主要考察地区能源消费总额(因变量)与煤炭消费量、焦炭消费量、原油消费量、原煤产量、焦炭产量、原油产量之间的关系。以下的回归分析所涉及只包括以上几个变量,并使用标准化之后的数据。
1.2.1 参数设置
1.单击菜单栏“ ”-->“ ”-->“”,将弹出如图1-7所示的对话框,将通过选择因变量和自变量来构建线性回归模型。因变量:标准化能源消费总额;自变量:标准化煤炭消费量、标准化焦炭消费量、标准化原油消费量、标准化原煤产量、标准化焦炭产量、标准化原油产量。自变量方法选择:进入,个案标签使用地名,不使用权重最小二乘法回归分析—即WLS权重为空。
图1-7选择线性回归变量还需要设置统计量的参数,我们选择回归系数中的“ ”和其他项中的“”。选中估计可输出回归系数B及其标准误,t值和p值,还有标准化的回归系数beta。选中模型拟合度复选框:模型拟合过程中进入、退出的变量的列表,以及一些有关拟合优度的检验:R,R2和调整的R2,标准误及方差分析表。如图1-8所示:
图1-8 设置回归分析统计量
3.在设置绘制选项的时候,我们选择绘制标准化残差图,其中的正态概率图是rankit图。同时还需要画出残差图,Y轴选择:ZRESID,X轴选择:ZPRED。如图1-9所示:
图1-9 设置绘制
左上框中各项的意义分别为:
·“DEPENDNT”因变量
·“ZPRED”标准化预测值
·“ZRESID”标准化残差
·“DRESID”删除残差
·“ADJPRED”调节预测值
·“SRESID”学生化残差
·“SDRESID”学生化删除残差
4.许多时候我们需要将回归分析的结果存储起来,然后用得到的残差、预测值等做进一步的分析,“保存”按钮就是用来存储中间结果的。可以存储的有:预测值系列、残差系列、距离(Distances)系列、预测值可信区间系列、波动统计量系列。本次实验暂时不保存任何项。
5.设置回归分析的一些选项,有:步进方法标准单选钮组:设置纳入和排除标准,可按P值或F值来设置。在等式中包含常量复选框:用于决定是否在模型中包括常数项,默认选中。如图1-10所示:
图1-10 设置选项
1.2.2 结果输出与分析
在以上选项设置完毕之后点击确定,SPSS将输出一系列的回归分析结果。我们来逐一贴出和分析,并根据它得到最后的回归方程以及验证回归模型。
1.表1-3所示,是回归分析过程中输入、移去模型记录。具体方法为:enter(进入)
输入/移去的变量 | |||
模型 | 输入的变量 | 移去的变量 | 方法 |
1 | Zscore(原油产量), Zscore(原煤产量), Zscore(焦炭消费量),Zscore(原油消费量), Zscore(煤炭消费量), Zscore(焦炭产量) | . | 输入 |
表1-3 输入的变量
- 表1-4所示是模型汇总,R称为多元相关系数,R方(R2)代表着模型的拟合度。
- 我们可以看到该模型是拟合优度良好。
模型汇总
模型汇总 | |||||
模型 | R | R 方 | 调整 R 方 | 标准 估计的误差 | Sig. |
1 | .962 | .925 | .905 | .30692707 | .000 |
表1-4 模型汇总
3.表1-5所示是离散分析。 ,F的值较大,代表着该回归模型是显著。也称为失拟性检验。
模型 | 平方和 | df | 均方 | F | |
1 | 回归 | 25.660 | 6 | 4.277 | 45.397 |
残差 | 2.072 | 22 | .094 | ||
总计 | 27.732 | 28 | |||
表1-5 离散分析
4.表1-6所示的是回归方程的系数,根据这些系数我们能够得到完整的多元回归方程。观测以下的回归值,都是具有统计学意义的。因而,得到的多元线性回归方程:Y=0.008+1.061x1+0.087x2+0.157 x3-0.365 x4-0.105x5-0.017x6
(x1为煤炭消费量,x2为焦炭消费量,x3为原油消费量,x4为原煤产量,x5为原炭产量,x6为原油产量,Y是能源消费总量)
结论:能量消费总量由主要与煤炭消费总量所影响,成正相关;与原煤产量成一定的反比。
系数 | ||||||
模型 | 非标准化系数 | 标准系数 | t | Sig. | ||
B | 标准 误差 | beta | ||||
1 | (常量) | .008 | .057 | .149 | .883 | |
Zscore(煤炭消费量) | 1.061 | .126 | 1.071 | 8.432 | .000 | |
Zscore(焦炭消费量) | .087 | .101 | .088 | .856 | .401 | |
Zscore(原油消费量) | .157 | .085 | .159 | 1.848 | .078 | |
Zscore(原煤产量) | -.365 | .155 | -.372 | -2.360 | .028 | |
Zscore(焦炭产量) | -.105 | .150 | -.107 | -.697 | .493 | |
Zscore(原油产量) | -.017 | .070 | -.017 | -.247 | .807 | |
表1-6回归方程系数
5.模型的适合性检验,主要是残差分析。残差图是散点图,如图1-11所示:
图1-11残差图
可以看出各散点随机分布在e=0为中心的横带中,证明了该模型是适合的。同时我们也发现了两个异常点,就是广东省和四川省,这种离群点是值得进一步研究的。
还有一种残差正态概率图(rankit图)可以直观地判断残差是否符合正态分布。如图1-12所示:
图1-12rankit(P-P)图
它的直方图如图1-13所示:
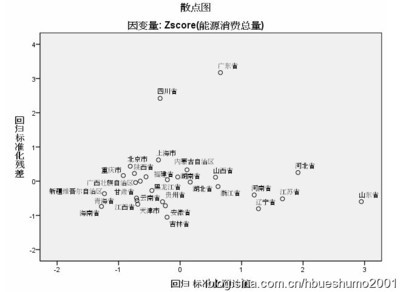
图1-13 rankit(直方)图