聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇)。其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的。组内相似性越大,组间差别越大,聚类就越好。
先介绍下聚类的不同类型,通常有以下几种:
(1)层次的与划分的:如果允许簇具有子簇,则我们得到一个层次聚类。层次聚类是嵌套簇的集族,组织成一棵树。划分聚类简单地将数据对象划分成不重叠的子集(簇),使得每个数据对象恰在一个子集中。
(2)互斥的、重叠的与模糊的:互斥的指每个对象都指派到单个簇。重叠的或是模糊聚类用来反映一个对象同时属于多个组的事实。在模糊聚类中,每个数据对象以一个0和1之间的隶属权值属于每个簇。每个对象与各个簇的隶属权值之和往往是1。
(3)完全的与部分的:完全聚类将每个对象指派到一个簇中。部分聚类中,某些对象可能不属于任何组,比如一些噪音对象。
聚类分析后发现的簇往往也具有不同的类型:
(1)明显分离的:簇是对象的集合,不同组中的任意两点之间的距离都大于组内任意两点之间的距离。(1)
(2)基于原型的:簇是对象的集合,其中每个对象到定义该簇的原型的距离比到其他簇的原型的距离更近(或更加相似)。对于具有连续属性的数据,簇的原型通常是质心,即簇中所有点的平均值。这种簇倾向于呈球状。
(3)基于图的:如果数据用图表示,其中节点是对象,而边代表对象之间的联系,则簇可以定义为连通分支,即互相连通但不与组外对象连通的对象组。基于图的簇一个重要例子就是基于临近的簇,其中两个对象是相连的,仅当他们的距离在指定的范围之内。也就是说,每个对象到该簇某个对象的距离比不同簇中的任意点的距离更近。
(4)基于密度的:簇是对象的稠密区域,被低密度的区域环绕。当簇不规则或互相盘绕,并且有噪声和离群点时,常常使用基于密度的簇定义。
下面介绍三种常用的聚类算法:
(1)基本K均值:基于原型的,划分的聚类技术,试图从全部数据对象中发现用户指定个数的簇。
(2)凝聚层次聚类:开始每个点各成一簇,然后重复的合并两个最近的簇,直到指定的簇个数。
(3)DBSCAN:一种划分的,基于密度的聚类算法。
下面我们以对二维空间的数据点对象的聚类为例,依次介绍三面三种聚类算法。我们使用的表示二维空间的数据点的源文件中,每行为一个数据点,格式是x坐标值# y坐标值。
基本K均值:选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。每次循环中,每个点被指派到最近的质心,指派到同一个质心的点集构成一个簇。然后,根据指派到簇的点,更新每个簇的质心。重复指派和更新操作,直到质心不发生明显的变化。
为了定义二维空间的数据点之间的“最近”概念,我们使用欧几里得距离的平方,即点A(x1,y1)与点B(x2,y3)的距离为dist(A,B)=(x1-x2)2+(y1-y2)2。另外我们使用误差的平方和SSE作为全局的目标函数,即最小化每个点到最近质心的欧几里得距离的平方和。在设定该SSE的情况下,可以使用数学证明,簇的质心就是该簇内所有数据点的平均值。
根据该算法,实现如下代码:
https://github.com/intergret/snippet/blob/master/Kmeans.py
或是 http://www.oschina.net/code/snippet_176897_14731
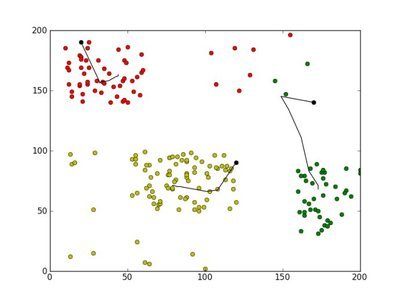
聚类的效果如下图,图中的折线是历次循环时3个簇的质心的更新轨迹,黑点是初始质心:我们查看基本K均值算法实现步骤及上面的聚类效果可以发现,该聚类算法将所有数据点都进行了指派,不识别噪音点。另外选择适当的初试质心是基本K均值过程的关键。其实,只要两个初试质心落在一个簇对的任何位置,就能得到最优聚类,因为质心将自己重新分布,每个簇一个,是SSE最小。如果初试时一个簇只有一个质心,那么基本K均值算法不能将该质心在簇对之间重新分布,只能有局部最优解。另外,它不能处理非球形簇,不同尺寸和不同密度的簇。
关于基本K均值算法的其他还可以查阅陈皓的博客:http://coolshell.cn/articles/7779.html
凝聚层次聚类:所谓凝聚的,指的是该算法初始时,将每个点作为一个簇,每一步合并两个最接近的簇。另外即使到最后,对于噪音点或是离群点也往往还是各占一簇的,除非过度合并。对于这里的“最接近”,有下面三种定义。我在实现是使用了MIN,该方法在合并时,只要依次取当前最近的点对,如果这个点对当前不在一个簇中,将所在的两个簇合并就行:
(1)单链(MIN):定义簇的邻近度为不同两个簇的两个最近的点之间的距离。
(2)全链(MAX):定义簇的邻近度为不同两个簇的两个最远的点之间的距离。
(3)组平均:定义簇的邻近度为取自两个不同簇的所有点对邻近度的平均值。
根据该算法,实现如下代码。开始时计算每个点对的距离,并按距离降序依次合并。另外为了防止过度合并,定义的退出条件是90%的簇被合并,即当前簇数是初始簇数的10%:
https://github.com/intergret/snippet/blob/master/HAC.py
或是 http://www.oschina.net/code/snippet_176897_14732
聚类的效果如下图,黑色是噪音点:另外我们可以看出凝聚的层次聚类并没有类似基本K均值的全局目标函数,没有局部极小问题或是很难选择初始点的问题。合并的操作往往是最终的,一旦合并两个簇之后就不会撤销。当然其计算存储的代价是昂贵的。
DBSCAN:是一种简单的,基于密度的聚类算法。本次实现中,DBSCAN使用了基于中心的方法。在基于中心的方法中,每个数据点的密度通过对以该点为中心以边长为2*EPs的网格(邻域)内的其他数据点的个数来度量。根据数据点的密度分为三类点:
(1)核心点:该点在邻域内的密度超过给定的阀值MinPs。
(2)边界点:该点不是核心点,但是其邻域内包含至少一个核心点。
(3)噪音点:不是核心点,也不是边界点。
有了以上对数据点的划分,聚合可以这样进行:各个核心点与其邻域内的所有核心点放在同一个簇中,把边界点跟其邻域内的某个核心点放在同一个簇中。
根据该算法,实现如下代码:
https://github.com/intergret/snippet/blob/master/Dbscan.py
或是 http://www.oschina.net/code/snippet_176897_14734
聚类的效果如下图,黑色是噪音点:因为DBSCAN使用簇的基于密度的定义,因此它是相对抗噪音的,并且能处理任意形状和大小的簇。但是如果簇的密度变化很大,例如ABCD四个簇,AB的密度大大大于CD,而且AB附近噪音的密度与簇CD的密度相当,这是当MinPs较大时,无法识别簇CD,簇CD和AB附近的噪音都被认为是噪音;当MinPs较小时,能识别簇CD,但AB跟其周围的噪音被识别为一个簇。这个问题可以基于共享最近邻(SNN)的聚类结局。