注明:此文为转载,感谢http://home.jmu.edu.cn/oho/lab/ortho.htm
1. 正交试验设计法的基本思想
正交试验设计法,就是使用已经造好了的表格--正交表--来安排试验并进行数据分析的一种方法。它简单易行,计算表格化,使用者能够迅速掌握。下边通过一个例子来说明正交试验设计法的基本想法。
[例1]为提高某化工产品的转化率,选择了三个有关因素进行条件试验,反应温度(A),反应时间(B),用碱量(C),并确定了它们的试验范围:
A:80-90℃
B:90-150分钟
C:5-7%
试验目的是搞清楚因子A、B、C对转化率有什么影响,哪些是主要的,哪些是次要的,从而确定最适生产条件,即温度、时间及用碱量各为多少才能使转化率高。试制定试验方案。
这里,对因子A,在试验范围内选了三个水平;因子B和C也都取三个水平:
A:Al=80℃,A2=85℃,A3=90℃
B:Bl=90分,B2=120分,B3=150分
C:Cl=5%,C2=6%,C3=7%
当然,在正交试验设计中,因子可以是定量的,也可以是定性的。而定量因子各水平间的距离可以相等,也可以不相等。
这个三因子三水平的条件试验,通常有两种试验进行方法:
(Ⅰ)取三因子所有水平之间的组合,即AlBlC1,A1BlC2,A1B2C1, ……,A3B3C3,共有
33=27次
试验。用图表示就是图1 立方体的27个节点。这种试验法叫做全面试验法。
全面试验对各因子与指标间的关系剖析得比较清楚。但试验次数太多。特别是当因子数目多,每个因子的水平数目也多时。试验量大得惊人。如选六个因子,每个因子取五个水平时,如欲做全面试验,则需56=15625次试验,这实际上是不可能实现的。如果应用正交实验法,只做25次试验就行了。而且在某种意义上讲,这25次试验代表了15625次试验。
图1 全面试验法取点..........
(Ⅱ)简单对比法,即变化一个因素而固定其他因素,如首先固定B、C于Bl、Cl,使A变化之:
↗A1
B1C1 →A2
↘A3 (好结果)
如得出结果A3最好,则固定A于A3,C还是Cl,使B变化之:
↗B1
A3C1 →B2 (好结果)
↘B3
得出结果以B2为最好,则固定B于B2,A于A3,使C变化之:
↗C1
A3B2→C2 (好结果)
↘C3
试验结果以C2最好。于是就认为最好的工艺条件是A3B2C2。
这种方法一般也有一定的效果,但缺点很多。首先这种方法的选点代表性很差,如按上述方法进行试验,试验点完全分布在一个角上,而在一个很大的范围内没有选点。因此这种试验方法不全面,所选的工艺条件A3B2C2不一定是27个组合中最好的。其次,用这种方法比较条件好坏时,是把单个的试验数据拿来,进行数值上的简单比较,而试验数据中必然要包含着误差成分,所以单个数据的简单比较不能剔除误差的干扰,必然造成结论的不稳定。
简单对比法的最大优点就是试验次数少,例如六因子五水平试验,在不重复时,只用5+(6-1)×(5-1)=5+5×4=25次试验就可以了。
考虑兼顾这两种试验方法的优点,从全面试验的点中选择具有典型性、代表性的点,使试验点在试验范围内分布得很均匀,能反映全面情况。但我们又希望试验点尽量地少,为此还要具体考虑一些问题。
如上例,对应于A有Al、A2、A3三个平面,对应于B、C也各有三个平面,共九个平面。则这九个平面上的试验点都应当一样多,即对每个因子的每个水平都要同等看待。具体来说,每个平面上都有三行、三列,要求在每行、每列上的点一样多。这样,作出如图2所示的设计,试验点用⊙表示。我们看到,在9个平面中每个平面上都恰好有三个点而每个平面的每行每列都有一个点,而且只有一个点,总共九个点。这样的试验方案,试验点的分布很均匀,试验次数也不多。
当因子数和水平数都不太大时,尚可通过作图的办法来选择分布很均匀的试验点。但是因子数和水平数多了,作图的方法就不行了。
试验工作者在长期的工作中总结出一套办法,创造出所谓的正交表。按照正交表来安排试验,既能使试验点分布得很均匀,又能减少试验次数,图2正交试验设计图例
而且计算分析简单,能够清晰地阐明试验条件与指标之间的关系。
用正交表来安排试验及分析试验结果,这种方法叫正交试验设计法。
返回
2.正交表
本书附录给出了常用的正交表。为了叙述方便,用L代表正交表,常用的有L8(27),L9(34),L16(45),L8(4×24),L12(211),等等。此符号各数字的意义如下:
L8(27)
7为此表列的数目(最多可安排的因子数)
2为因子的水平数
8为此表行的数目(试验次数)
L18(2×37)
有7列是3水平的
有1列是2水平的
L18(2×37)的数字告诉我们,用它来安排试验,做18个试验最多可以考察一个2水平因子和7个3水平因子。
在行数为mn型的正交表中(m,n是正整数),
试验次数(行数)=Σ(每列水平数一1)+l (1)
如L8(27),
8=7×(2-1)+l
利用上述关系式可以从所要考察的因子水平数来决定最低的试验次数,进而选择合适的正交表。比如要考察五个3水平因子及一个2水平因子,则起码的试验次数为
5×(3-1)+1×(2-1)+1=12(次)
这就是说,要在行数不小于12,既有2水平列又有3水平列的正交表中选择,L18(2×37)适合。
正交表具有两条性质:(1)每一列中各数字出现的次数都一样多。(2)任何两列所构成的各有序数对出现的次数都一样多。所以称之谓正交表。
例如在L9(34)中(见表1),各列中的l、2、3都各自出现3次;任何两列,例如第3、4列,所构成的有序数对从上向下共有九种,既没有重复也没有遗漏。其他任何两列所构成的有序数对也是这九种各出现一次。这反映了试验点分布的均匀性。
返回
3.试验方案的设计
安排试验时,只要把所考察的每一个因子任意地对应于正交表的一列(一个因子对应一列,不能让两个因子对应同一列),然后把每列的数字"翻译"成所对应因子的水平。这样,每一行的各水平组合就构成了一个试验条件(不考虑没安排因子的列)。
对于[例1],因子A、B、C都是三水平的,试验次数要不少于
3×(3-1)+1=7(次)
可考虑选用L9(34)。因子A、B、C可任意地对应于L9(34)的某三列,例如A、B、C分别放在l、2、3列,然后试验按行进行,顺序不限,每一行中各因素的水平组合就是每一次的试验条件,从上到下就是这个正交试验的方案,见表2。这个试验方案的几何解释正好是图2。
三个3水平的因子,做全面试验需要33=27次试验,现用L9(34)来设计试验方案,只要做9次,工作量减少了2/3,而在一定意义上代表了27次试验.。
再看一个用L9(34)安排四个3水平因子的例子。
[例2]某矿物气体还原试验中,要考虑还原时间(A)、还原温度(B)、还原气体比例(D)、气体流速(C)这四个因子对全铁合量X〔越高越好)、金属化率Y(越高超好)、二氧化钛含量Z(越低越好)这三项指标的影响。希望通过试验找出主要影响因素,确定最适工艺条件。
首先根据专业知以确定各因子的水平:
时间:A1=3(小时),A2=4(小时),A3=5(小时)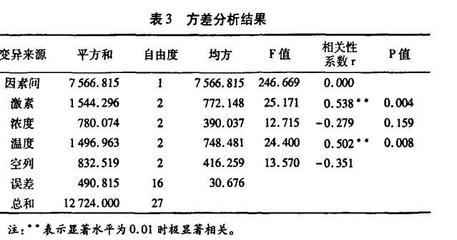
温度:B1=1000(℃),B2=1100(℃),B3=1200(℃)
流速:Cl=600(毫升/分),C2=400(毫升/分),
C3=800(毫升/分)
CO:H2:D1=1:2,D2=2:1,D3=1:1
这是四因子3水平的多指标(X、Y、Z)问题,如果做全面试验需34=81次试验,而用L9(34)来做只要9次。具体安排如表3。
同全面试验比较,工作量少了8/9。由于缩短了试验周期,可以提高试验精度,时间越长误差于扰越大。并且对于多指标问题,采用简单对比法,往往顾此失彼,最适工艺条
件很难找;而应用正交表来设计试验时可对各指标通盘考虑,结论明确可靠。
返回
4.试验数据的直观分析
正交表的另一个好处是简化了试验数据的计算分折。还是以[例1]为例来说明。按照表2的试验方案进行试验,测得9个转化率数据,见表4。
通过9次试验,我们可以得两类收获。第一类收获是拿到手的结果。第9号试验的转化率为64,在所做过的试验中最好,可取用之。因为通过L9(34)已经把试验条件均衡地打散到不同的部位,代表性是好的。假如没有漏掉另外的重要因素,选用的水平变化范围也合适的话,那么,这9次试验中最好的结果在全体可能的结果中也应该是相当好的了,所以不要轻易放过。
第二类收获是认识和展望。9次试验在全体可能的条件中(远不止33=27个组合,在试验范围内还可以取更多的水平组合)只是一小部分,所以还可能扩大。精益求精。寻求更好的条件。利用正交表的计算分折,分辨出主次因素,预测更好的水平组合,为进一步的试验提供有份量的依据。
其中I、Ⅱ、Ⅲ分别为各对应列(因子)上1、2、3水平效应的估计值,其计算式是:
Ⅰi(Ⅱi,Ⅲi)=第i列上对应水平1(2,3)的数据和
K1 为1水平数据的综合平均=Ⅰ/水平1的重复次数
Si为变动平方和=
[例1]的转化率试验数据与计算分析见表4。
先考虑温度对转比率的影响。但单个拿出不同温度的数据是不能比较的,因为造成数据差异的原因除温度外还有其他因素。但从整体上看,80℃时三种反应时间和三种用碱量全遇到了,86℃时、90℃时也是如此。这样,对于每种温度下的三个数据的综合数来说,反应时间与加碱量处于完全平等状态,这时温度就具有可比性。所以算得三个温度下三次试验的转化率之和:
80℃: ⅠA=xl+x2+x3=31+54+38=123;
85℃: ⅡA=x4+x5+x6=53+49+42=144;
90℃: ⅢA=x7+x8+x9=57+62+64=183。
分别填在A列下的Ⅰ、Ⅱ、Ⅲ三行。再分别除以3,表示80℃、85℃、90℃时综合平均意义下的转化率,填入下三行Kl、K2、K3。R行称为极差,表明因子对结果的影响幅度。
同样地,为了比较反应时间;用碱量对转化率的影响,也先算出同一水平下的数据和IB、ⅡB、ⅢB,Ic、Ⅱc、Ⅲc,再计算其平均值和极差。都填入表4中;
由此分别得出结论:温度越高转化率越好,以90℃为最好,但可以进一步探索温度更好的情况。反应时间以120分转化率最高。用碱量以6%转化率最高。
所以最适水平是A3B2C2。
返回
5.正交试验的方差分析
(一)假设检验
在数理统计中假设检验的思想方法是:提出一个假设,把它与数据进行对照,判断是否舍弃它。其判断步骤如下:
(1)设假设H。正确,可导出一个理论结论,设此结论为R。;
(2)再根据试验得出一个试验结论,与理论结论相对应,设为R1;
(3)比较R。与Rl,若R。与Rl没有大的差异,则没有理由怀疑H。,从而判定为:"不舍弃H。"(采用H。);若R。与R1有较大差异,则可以怀疑H。,此时判定为:"舍弃H。"。
但是,R1/R。比l大多少才能舍弃H。呢?为确定这个量的界限,需要利用数理统计中关于F分布的理论。
若yl服从自由度为φ1的χ2分布,y2服从自由度为φ2的χ2分布,并且yl、y2相互独立,则(y1/φ1)/(y2/φ2)服从自由度为(φ1,φ2)的F分布。F分布是连续分布,分布模数是两个自由度(φ1,φ2)。称φ1为分子自由度,称φ2为分母自由度。在自由度为(φ1,φ2)的F分布中,某点右侧面积为p,也就是F比此值大的概率为p,把这个值写为(p)。若检验的显著性水平(或危险率)给定为α时,则可以把 (α)作为临界值来检验假设。
这里,Se/σ2服从自由度为φe,的χ2分布;当H。成立,σ2=0时,SA/σ2也服从自由度为φA的χ2分布;又SA与Se相互成立,所以(SA/(φAσ2)/Se/(φeσ2))=VA/Ve服从自由度为(φA,φe)的F分布。这就是假定H。正确时的理论结论R。。而试验结论Rl要与理论结论R。相比较。由给定的显著性水平,通常是α=0.05;分子自由度φ1=φA=a-l,分母自由度φ2=φe=a(n-1);查F分布表得出(α)。所以H。:αl=α2=……=αa=0(σA2=0)的检验是:(显著性水平α)
FA=VA/Ve> (α) → 舍弃H。
FA=VA/Ve≤ (α) → 不舍弃H。
通常, (α)一般性地表示成Fα(φA,φB)。
假设因子A对试验结果的影响不显著,那么A的两个水平的效应该表现为相等或相近,即假设H。:α1=α2=0。如果因子A显著,则舍弃假设。
为了判断因子A是否显著,首先要计算比值
显然,这个比值越大,因子A对指标的影响越显著;反之,因子A就不显著。在给定置信度α后,如α=0.05,查F分布表,自由度φA是因子A的,自由度φe是误差的,其临界值Fα(φA,φe),如果
FA>Fα(φA,φe)
就舍弃假设,可以认为因子A是显著的;如果
FA≤Fα(φA,φe)
就没有理由否定假设,而只能认为因子A是不显著的。因为按照F分布表的物理念义,F值小于Fα(φA,φe)的概率是95%,即有95%的机会出现小于Fα(φA,φe)的F值,既然出现了这种情况,就有了95%的把握,所以就没有理由否定假设,只能接受假设,认为因子A不显著。另一方面,F值大于Fα(φA,φe)的概率是5%,也就是只有5%的机会出现大于Fα(φA,φe)的F值,这是小概率事件,如果小概率事件居然发生了,则可认为情况异常,假设不可信,必须否定假设,因子A是显著的。
对其他因子的显著性检验完全类似。
(二)方差分析表
由总平方和与各因素平方和即可求得误差平方和,亦称剩余平方和。是总平方和减各因素平方和所得。如正交表有一空列,则该列的平方和就量误差平方和。但在正交表饱和试验的情况下,即所有各列全部排满时,误差平方和一般用各因素平方和中几个最小的平方和之和来代替,同时,这几个因素不再作进一步的分析。
自由度:φT=试验次数一1
φA,B…=水平数一1
φA×B=φA×φB
φe=φT-φA-φB-……-φD
6.常用正交表(省略)