公司1 | 公司2 | 公司100 | ||||||||||
因素1 | …… | 因素6 | 盈余管理程度 | 因素1 | …… | 因素6 | 盈余管理程度 | 因素1 | …… | 因素6 | 盈余管理程度 | |
1999 | ||||||||||||
2000 | ||||||||||||
…… | ||||||||||||
2010  | ||||||||||||
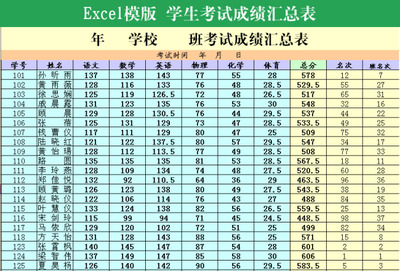
如上图所示的数据即为面板数据。显然面板数据是三维的,而时间序列数据和截面数据都是二维的,把面板数据当成时间序列数据或者截面数据来处理都是不合适的。
处理面板数据的软件较多,一般使用Eviews6.0、Stata等。个人推荐使用Stata,因为Stata比较适合处理面板数据,且个性化强。以下以Stata11.0为例来讲解怎么样处理面板数据。
由于面板数据的存储结构与我们通常使用的存储结构不太一样,所在统计分析前,最好在excel中整理一下数据,形成如下图所示的数据
年份 | 公司名称 | 因素1 | 因素2 | …… | 因素6 | 盈余管理程度 |
1999 | 公司1 | |||||
2000 | 公司1 | |||||
…… | 公司1 | |||||
2010 | 公司1 | |||||
1999 | 公司2 | |||||
2000 | 公司2 | |||||
…… | 公司2 | |||||
2010 | 公司2 |
变量定义及输入数据
启动Stata11.0,Stata界面有4个组成部分,Review(在左上角)、Variables(左下角)、输出窗口(在右上角)、Command(右下角)。首先定义变量,可以输入命令,也可以通过点击Data----Createnew Variable or changevariable。
特别注意,这里要定义的变量除了因素1、因素2、……因素6、盈余管理影响程度等,还要定义年份和公司名称两个变量,这两个变量的数据类型(Type)最好设置为int(整型),公司名称不要使用中文名称或者字母等,用数字代替。定义好变量之后可以输入数据了。数据可以直接导入(File-Import),也可以手工录入或者复制粘贴(Data-DataEdit(Browse)),手工录入数据和在excel中的操作一样。
以上面说的为例,定义变量 year、 company、factor1、 factor2、 factor3、 factor4、 factor5、 factor6、 DA。
变量company和year分别为截面变量和时间变量。显然,通过这两个变量我们可以非常清楚地确定panel data的数据存储格式。因此,在使用STATA估计模型之前,我们必须告诉它截面变量和时间变量分别是什么,所用的命令为tsset,命令为:
tsset company year |
输出窗口将输出相应结果。
由于面板数据本身兼具截面数据和时间序列二者的特性,所以对时间序列进行操作的运算同样可以应用到面板数据身上。这一点在处理某些数据时显得非常方便。如,对于上述数据,我们想产生一个新的变量Lag_factor1 ,也就是factor1 的一阶滞后,那么我们可以采用如下命令:
gen Lag_factor1=L.factor1 |
统计描述:
在正式进行模型的估计之前,我们必须对样本的基本分布特性有一个总体的了解。对于面板数据而言,我们至少要知道我们的数据中有多少个截面(个体),每个截面上有多少个观察期间,整个数据结构是平行的还是非平行的。进一步地,我们还要知道主要变量的样本均值、标准差、最大值、最小值等情况。这些都可以通过以下三个命令来完成:xtdes命令用于初步了解数据的大体分布状况,我们可以知道数据中含有多少个截面,最大和最小的时间跨度是多少。在某些要求使用平行面板数据的情况下,我们可以采用该命令来诊断处理后的数据是否为平行数据。Xtsum用来查询对组内、组间、整体计算各个变量的基本统计量(如均值、方差等)。为了方便,以下的举例都只用factor1,factor2两个自变量。
xtdes DA factor1 facto2 |
xtsum DA factor1 facto2 |
模型回归。
常用的处理面板数据的模型有混合OLS模型、固定效应模型、随机效应模型。各个模型的区别请上网查查。下面说说各个模型的命令:
混合OLS模型输入命令:
regress DA factor1 facto2 |
固定效应模型输入命令:
xtreg DA factor1 factor , fe |
随机效应模型输入命令:
xtreg DA factor1 factor , re |
模型的选择及检验
固定效应模型要检验个体效应的显著性,这可以通过固定效应模型回归结果的最后一行的F统计量看出,F越大越好,可以得出固定效应模型优于混合OLS模型的结论。随机效应模型要检验随机效应是否显著,要输入命令:
xttest0 |
如果检验得到的p值为0,则随机效应显著,随机效应模型也优于固定效应模型。至于固定效应模型与随机效应模型选哪一个,则要通过hausman检验来得出。
Hausman检验
Hausman检验的原假设是固定效应模型优于随机效应模型,如果hausman检验的p值为0,则接受原假设,使用固定效应模型。相关命令:
qui xtreg DA factor1 factor2 ,fe est store fe qui xtreg DA factor1 factor2 ,re est store re hausman fe |
检验序列相关
固定效应模型使用xtserial命令,随机效应模型使用xttest1命令:
qui xtreg DA factor1 factor2 ,re xttest1…………对于随机效应模型 xtserial DA factor1 factor2 |
如果没有xtserial命令即输入上面的命令后弹出no command,则输入finditxtserial.ado可以自动搜索到进行安装。
检验截面相关性及截面异方差性
由于面板数据都是针对国家或公司的,因此截面间往往会存在相关性,我们可以利用xttest2命令来检验固定效应模型中截面间的相关性是否显著。
qui xtreg DA factor1 factor2 ,fe xttest2 |
检验截面异方差性输入命令
Xttest3 希望上面的内容对大家有所帮助。 |