磁盘阵列RAID(diskarray)可以有效的提高存储系统的可靠性和性能,同时也存在显著的缺点,那就是由于多个设备(磁盘)同时使用,导致了可靠性降低(从概率的角度来讲:N个设备的可靠性是一个设备的1/N)。
磁盘阵列RAID(Redundant array of inexpensivedisk)就是为了解决这个问题而产生的,RAID通过给磁盘阵列增加冗余磁盘提高了磁盘阵列的可靠性。所谓冗余磁盘,即该磁盘不用于存放实际数据,而用来存放一些冗余信息,而这些冗余信息可用来在必要的时候进行有效数据恢复,从而增加磁盘阵列的可靠性,翻译成中文应该叫廉价磁盘冗余阵列。
在磁盘阵列RAID6出现之前,磁盘阵列RAID已经有了从RAID0~RAID5六个版本。那么我们已经有了这么多的磁盘阵列RAID方式,提供了相当级别的可靠性保护,为什么我们还需要RAID6?在这里,我们这里先比较研究一下几种比较有代表性的磁盘阵列RAID方式:
磁盘冗余家族概览
目前应用最广泛,支持设备最多的RAID方式主要是RAID0,RAID1和RAID5
(1)无冗余(RAID0):RAID0实际上不能算做真正的磁盘阵列RAID技术,它只是实现了磁盘阵列存放数据的带状分布。虽然提高了大规模数据访问的性能,但是RAID0并没有冗余容错的功能,因为它本身并无冗余,所以可以说这里的RAID0是个误称
(2)镜像(RAID1):磁盘阵列RAID1同样实现了数据的带状分布,与RAID0所不同的是,在数据写入一个磁盘的时候,同时在另一个磁盘做相应的镜象。因此,RAID1虽然有数据容错功能,但是其对磁盘的利用率实在比较底,仅为50%。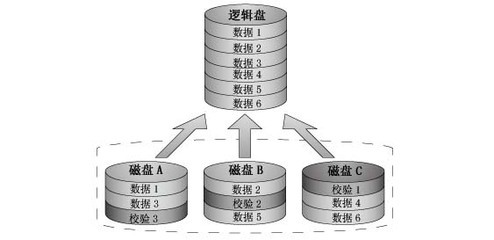
数据分布示意图(以4块磁盘组成的阵列为例):
注释:其中d1,d2等表示存放的数据,d1’, d2’分别表示了数据d1和d2的备份。
(3)奇偶校验(RAID5):相对于RAID1比较,RAID5也是仅仅实现了单个磁盘的冗余纠错功能,但是却大大提高了磁盘的有效利用率。以RAID5(4D+P)为例子来讲,使用4块磁盘存放数据位,使用1块磁盘存放校验位。其基本原理是这样的:根据条带化的数据4D(使用四位数据)生成一位的校验信息,存放在第五块磁盘中。
生成P校验位的公式一般是这样的:
P = D1 ⊕ D2 ⊕ D3 ⊕ D4
P为校验位,D1~D4分别代表四个数据位,⊕表示异或操作。
可以看到,当D1,D2,D3,D4中其余的一个数据丢失的时候,可以利用其余的三个数据位和校验位P进行恢复,具体的恢复公式如下:
例如,当D1丢失的时候,D1 = D2 ⊕ D3 ⊕ D4 ⊕ P
同时可以看到,当两快磁盘出现故障的时候,磁盘阵列RAID5无法恢复。
数据分示意布图(以4D+1P为例):
其中,P1为数据位d0,d1,d2,d3的校验信息,P2为数据位d4,d5,d6,d7的校验信息等等。可以看到,校验信息并非存放在一块固定的磁盘上的,而是存放在不同的磁盘的,这样可以平衡各个磁盘的读写次数,从而平衡各个磁盘的使用频率(因为校验位的读写要相对频繁一点)。
磁盘阵列RAID6:突破磁盘冗余局限
RAID5已经提供了一定程度的可靠性,然而也牺牲了一定的读取速度。特别是在磁盘阵列RAID重构作业中,大量的数据读写操作增加硬盘的负担,旧的硬盘更容易发生故障。RAID5的局限性还表现在RAID5仅能在一块硬盘发生故障的情况下修复数据,如果2块硬盘同时发生故障,RAID5则无能为力。
以前,两块盘同时坏的情况是小概率事件,几乎不可能发生。但是近来随着光纤(FC)盘和SATA盘的容量和密度不断增加,使得RAID5的重建时间也不断增加。两块硬盘同时损坏的概率也大幅增加,在企业级存储上,这种风险必须得到重视。所以RAID6应需诞生了。
RAID6同RAID5最大的区别就是在RAID5的基础上除了具有P校验位以外,还加入了第2个校验位Q位。以RAID6(6D+1P+1Q)为例子,这个系统需要8块硬盘,其中6块用于存放数据,1块用于存放P校验位,1块用于存放Q校验位。当然,我得又一次强调,并非某个具体的独立的盘全部用来存放P校验信息,另外一个Q校验信息。而是对于某个位组(6个数据位+P位+Q位)来说,采用某种原则,6块盘上存放数据位,1块盘存放P位,1块盘用来存放Q位。
其数学原理如下:
校验位的生成:
P = D1 ⊕ D2 ⊕ D3 ⊕ D4 ⊕ D5 ⊕ D6
Q = GF(D1) ⊕ GF(D2) ⊕ GF(D3) ⊕ GF(D4) ⊕ GF(D5) ⊕ GF(D6)
D1~D6:条带化的数据
P:P校验位
Q:Q校验位
⊕:异或操作
GF(D1):对D1位进行Galois Field变换。
当一块磁盘出现数据错误或者丢失的时候,恢复方法同磁盘阵列RAID5,无须使用Q校验位。当两块磁盘上的数据出现错误或者丢失的时候,恢复方法为:利用上边给出的P,Q的生成公式,联立方程组,无论受损的数据是否包括P或者Q,总是能够解出损失的两位的数据。数据分布示意图(以6D+P+Q位例):
同样可以看到,每个位组(6D+1P+1Q)的P,Q位是位于不同的磁盘上的。
RAID6与RAID5数据安全性比较:RAID6是在RAID5的改进,RAID6不仅能在一个磁盘离线的情况下将数据恢复(使用和RAID5一样的异或校验),而且由于用了两个盘作为纠错盘,所以能应付两个磁盘同时离线的情况。由于目前磁盘的容量越来越大等因素,在大型的关键数据库中(如商业银行大型的数据库等)出现两个磁盘同时出错的概率也在上升,这也使得RAID6技术越来越被看好。笔者针对同样是8个磁盘,数据利用率同样是75%,但分别用RAID5和RAID6进行构建的磁盘阵列情况进行比较。一个用两个独立的磁盘阵列RAID5(3D+1P)构建;另一个用RAID6(6D+1P+1Q)构建,应用伯努利(Bernoulli)概率分布分析如下(假设单个磁盘在10年内出现故障的概率是p):两个独立的RAID5(3D+1P)构建的系统数据安全的概率分析:在三种情况下,该系统的数据是安全的:
1. 8个磁盘都没有损坏的情况,概率是(1-p)^8
2. 8个磁盘只有一个损坏的情况,概率是C81*p*(1-p)^7
3. 两个独立RAID5(3D+1P)系统中,各损坏一个磁盘的情况,概率是(C41*p*(1-p)^3)^2
所以,两个独立的RAID5(3D+1P)构建的系统数据安全的总概率是一个磁盘阵列RAID6(6D+1P+1Q)构建的系统数据安全的概率分析:
1. 8个磁盘都没有损坏的情况,概率是 [与上个系统相同]
2. 8个磁盘只有一个损坏的情况,概率是[与上个系统相同]
3. 8个磁盘中有两个损坏的情况,概率是C82*p^2*(1-p)^6
所以,一个RAID6(6D+1P+1Q)构建的系统数据安全的总概率是实际一点,假设单个磁盘在10年内出现故障的概率是1%,则用RAID5构建的系统,十年内不出故障的安全概率为99.881629%;对比用RAID6构建的系统,十年内不出故障的安全概率为99.994607%。可见,RAID6的数据安全级别是相当高的。当然RAID5的安全性也相当好了。从上面数据看起来,两者相差不大。
但是对于出现故障的概率RAID5是0.118371%,RAID6是0.005393%.这样看来,提高还是很大的。随着磁盘的容量越来越大导致数据出错概率的增大。两者的差距还会进一步加大,RAID6的优势就更明显了。而当磁盘容量增至20多TB的时候,RAID6的安全性比RAID5已经高出1000倍左右。总结篇对RAID6做一下总结如下:在使用大数据块的情况下,RAID6的随机读取性能很好;因为不但要在每硬盘上写入校验数据而且要在专门的校验硬盘上写入数据,RAID6的随机写入性能很差。RAID6的持续写入性能一般,在使用小数据块时表现很好。总体而言,RAID6拥有更快速的读取性能,更高的容错能力。
但同时,RAID6也存在写入速度很慢的缺点,RAID控制器在设计上更加复杂,成本更高。RAID6是一项很有吸引力的技术,它允许一个阵列中的两块磁盘同时出现故障而不会丢失数据。现在的磁盘可靠性已经很高,尤其是高端的光纤通道磁盘,那么有必要对两块磁盘同时出现故障的情况进行设防吗?答案是肯定的,目前的磁盘容量已经很大,如果一块磁盘出现故障,那么整个磁盘阵列RAID组中的磁盘都需要进行数据重构,磁盘容量越大需要的时间越长,在数据重构的时间内如果再发生磁盘故障,那么所有的数据都将丢失。
因此RAID6技术将可靠性提高了1000倍以上。可以看到,磁盘阵列RAID更加注重的是数据的安全性,而且由于成本之高,所以并不适合所有的企业,对于一般安全性的数据而言,RAID5还是比较合适的,只有高安全性数据,才需要RAID6技术。