示例代码下载:http://files.cnblogs.com/bottlebox/HmmPos.zip
一、viterbi算法原理及适用情况
当事件之间具有关联性时,可以通过统计两个以上相关事件同时出现的概率,来确定事件的可能状态。
以中文的词性标注为例。
中文中,每个词会有多种词性(比如"希望"即是名字又是动词),给出一个句子后,我们需要给这个句子的每个词确定一个唯一的词性,实际上也就是在若干词性组合中选择一个合适的组合。
动词、名词等词类的搭配是具有规律性的,比如动词+名词的形式是大量存在的,当我们看到句子"存在希望",如果确定了"存在"是动词,那么由于动名词组合的概率较大,我们就会认定"希望"是名词。
viterbi算法的原理就是基于此。我们需要计算所有的名词+动词,名词+名词,动词+形容词。。。。。等各种种词性搭配的出现概率,然后从中选出最大概率的组合。
二、操作步骤
1、需要准备一个语料库,包含已经正确标注了词性的大量语句。
2、对语料库的内容进行统计。需要得到以下数据。
(1)所有可能的词性。
(2)所有出现的词语。
(3)每个词语以不同词性出现的次数。
(4)记录句首词为不同词性的次数。
(5)记录句子中任一两种词性相邻的次数(如遇到:"看电影"这个句子,则有[动词][名词]的值加一。
3、针对前面统计的结果,进行分析计算。需计算以下数据。
(1)计算每类词性作为句首出现的比例(比如:动词为句首,占所有不同词性为句首中的比例),
记录到fstart[TYPE_NUM]。
(2)计算后词固定为词性[n]时,前词为词性[x]占总情况的比例(如:后词固定为[动词]时,前词[名词]出现的次数占所有[x][动词]的比例),
记录到fshift[TYPE_NUM][TYPE_NUM];
(3)计算每一个词作为不同类词性出现的次数,占所有该类词出现总数的比例(如:"中国"作为名词出现的次数占所有名词的比例),
记录到ffashe[TYPE_NUM][60000]
4、输入句子进行词性标注
输入的句子中每个词有多个词性。我们需要选出合适的一个组合。
比如输入句子"希望"+"的"+"田野",
分别有词性个数p1,p2,p3,p4,则可能的词性组合数为:S=p1*p2*p3*p4,我们需要从S个不同组合中选出最优的一个组合。
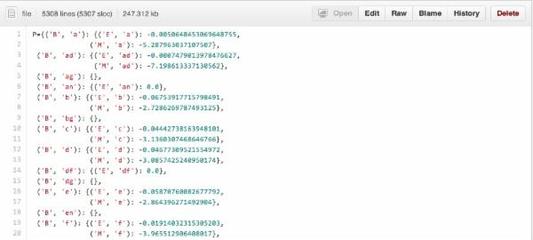
如下图:
问题:
1、当输入词数较多时,一般取概率的自然对数值log(P(B1|A)),否则很容易出现后面的值因为过小全变为0而无法比较的情况。
2、概率的计算。
对二3.(2)的概率计算如果改成固定前词,则最后的正确率要小3%左右,从图中也可看出算法的比较是固定的后词。如果改为以所有的连接数为总体,则正确率要小1%左右,但感觉这样更合理些,因为当某类词数量较小时(比如只有一两个),就会导致其实际存在的连接概率很大。实测中,"希望的田野"中的田野开始被标注为na类型,na在语料库中只出现一次(应该是不存在的词性,是误标),其前词是助词,这就导致m_fshift[助词][na]值偏大(达到0.7),所以导致标注错误。
对二3.(3)的概率计算,如果改成统计每个词以某一词性出现次数占该词出现总数的比例,则最后的正确率要小2%左右。如果一个词A可为动词和名词,其为动词的次数大于为名词的次数,而另一方面A为(名词次数/所有名词出现次数)大于A为(动词次数/所有动词出现次数),从全局来考虑A作为名词估计全局正确率更大些。