对同一个体进行多项观察时,必定涉及多个随机变量X1,X2,…,Xp,它们都是的相关性, 一时难以综合。这时就需要借助主成分分析 (principal componentanalysis)来概括诸多信息的主要方面。我们希望有一个或几个较好的综合指标来概括信息,而且希望综合指标互相独立地各代表某一方面的性质。
任何一个度量指标的好坏除了可靠、真实之外,还必须能充分反映个体间的变异。如果有一项指标,不同个体的取值都大同小异,那么该指标不能用来区分不同的个体。由这一点来看,一项指标在个体间的变异越大越好。因此我们把“变异大”作为“好”的标准来寻求综合指标。
1.主成分的一般定义
设有随机变量X1,X2,…,Xp, 其样本均数记为, ,…, ,样本标准差记为S1,S2,…,Sp。首先作标准化变换
我们有如下的定义:
(1) 若C1=a11x1+a12x2+… +a1pxp,,且使 Var(C1)最大,则称C1为第一主成分;
(2) 若C2=a21x1+a22x2+…+a2pxp,,(a21,a22,…,a2p)垂直于(a11,a12,…,a1p),且使Var(C2)最大,则称C2为第二主成分;
(3) 类似地,可有第三、四、五…主成分,至多有p个。
2.主成分的性质
主成分C1,C2,…,Cp具有如下几个性质:
(1) 主成分间互不相关,即对任意i和j,Ci 和Cj的相关系数
Corr(Ci,Cj)=0i ¹ j
(2) 组合系数(ai1,ai2,…,aip)构成的向量为单位向量,
(3) 各主成分的方差是依次递减的,即
Var(C1)≥Var(C2)≥…≥Var(Cp)
(4) 总方差不增不减,即
Var(C1)+Var(C2)+ …+Var(Cp)
=Var(x1)+Var(x2)+… +Var(xp)
=p
这一性质说明,主成分是原变量的线性组合,是对原变量信息的一种改组,主成分不增加总信息量,也不减少总信息量。
(5) 主成分和原变量的相关系数 Corr(Ci,xj)=aij=aij
(6) 令X1,X2,…,Xp的相关矩阵为R,(ai 1,ai2,…,aip)则是相关矩阵R的第i个特征向量(eigenvector)。而且,特征值li就是第i主成分的方差,即
Var(Ci)= li
其中li为相关矩阵R的第i个特征值(eigenvalue)
l1≥l2≥…≥lp≥0
3.主成分的数目的选取
前已指出,设有p个随机变量,便有p个主成分。由于总方差不增不减,C1,C2等前几个综合变量的方差较大,而Cp,Cp-1等后几个综合变量的方差较小, 严格说来,只有前几个综合变量才称得上主(要)成份,后几个综合变量实为“次”(要)成份。实践中总是保留前几个,忽略后几个。
保留多少个主成分取决于保留部分的累积方差在方差总和中所占百分比(即累计贡献率),它标志着前几个主成分概括信息之多寡。实践中,粗略规定一个百分比便可决定保留几个主成分;如果多留一个主成分,累积方差增加无几,便不再多留。
4.主成分回归
主成分分析本身往往并不是目的,而是达到目的的一种手段。因此,它多用在大型研究项目的某个中间环节。例如,把它用在多重回归中,便产生了主成分回归。另外,它还可以用于聚类、判别分析等。本节主要介绍主成分回归。
在多重回归曾指出,当自变量间高度相关时,某些回归参数的估计值极不稳定,甚至出现有悖常理、难以解释的情形。这时,可先采用主成分分析产生若干主成分,它们必定会将相关性较强的变量综合在同一个主成分中,而不同的主成分又是互相独立的。只要多保留几个主成分,原变量的信息不致过多损失。然后,以这些主成分为自变量进行多重回归就不会再出现共线性的困扰。如果原有p个自变量X1,X2,…,Xp,那么,采用全部p个主成分所作回归完全等价于直接对原变量的回归;采用一部分主成分所作回归虽不完全等价于对原变量的回归,但往往能摆脱某些虚假信息,而出现较合理的结果。
以上思路也适用于判别分析,当自变量高度相关时,直接作判别分析同样有多重共线性问题,可先计算自变量的主成分,然后通过主成分估计判别函数。
主成分分析 ( Principal Component Analysis , PCA )是一种掌握事物主要矛盾的统计分析方法,它可以从多元事物中解析出主要影响因素,揭示事物的本质,简化复杂的问题。计算主成分的目的是将高维数据投影到较低维空间。给定n 个变量的 m 个观察值,形成一个 n ′ m 的数据矩阵, n通常比较大。对于一个由多个变量描述的复杂事物,人们难以认识,那么是否可以抓住事物主要方面进行重点分析呢?如果事物的主要方面刚好体现在几个主要变量上,我们只需要将这几个变量分离出来,进行详细分析。但是,在一般情况下,并不能直接找出这样的关键变量。这时我们可以用原有变量的线性组合来表示事物的主要方面,PCA 就是这样一种分析方法。
PCA的目标是寻找 r ( r<n)个新变量,使它们反映事物的主要特征,压缩原有数据矩阵的规模。每个新变量是原有变量的线性组合,体现原有变量的综合效果,具有一定的实际含义。这r 个新变量称为“主成分”,它们可以在很大程度上反映原来 n个变量的影响,并且这些新变量是互不相关的,也是正交的。通过主成分分析,压缩数据空间,将多元数据的特征在低维空间里直观地表示出来。例如,将多个时间点、多个实验条件下的基因表达谱数据(N 维)表示为 3 维空间中的一个点,即将数据的维数从 降到 。
在进行基因表达数据分析时,一个重要问题是确定每个实验数据是否是独立的,如果每次实验数据之间不是独立的,则会影响基因表达数据分析结果的准确性。对于利用基因芯片所检测到的基因表达数据,如果用PCA方法进行分析,可以将各个基因作为变量,也可以将实验条件作为变量。当将基因作为变量时,通过分析确定一组“主要基因元素”,它们能够很好地说明基因的特征,解释实验现象;当将实验条件作为变量时,通过分析确定一组“主要实验因素”,它们能够很好地刻画实验条件的特征,解释基因的行为。下面着重考虑以实验条件作为变量的PCA 分析方法。假设将数据的维数从 R N 降到 R 3 ,具体的 PCA 分析步骤如下:
(1) 第一步计算矩阵 X 的样本的协方差矩阵 S :
(2) 第二步计算协方差矩阵S的本征向量 e1,e2,…,eN的本征值, i = 1,2,…,N 。本征值按大到小排序: ;
(3)第三步投影数据到本征矢张成的空间之中,这些本征矢相应的本征值为。现在数据可以在三维空间中展示为云状的点集。
对于PCA ,确定新变量的个数 r 是一个两难的问题。我们的目标是减小 r ,如果 r小,则数据的维数低,便于分析,同时也降低了噪声,但可能丢失一些有用的信息。究竟如何确定 r呢?这需要进一步分析每个主元素对信息的贡献。
令 代表第 i 个特征值,定义第 i 个主元素的贡献率为:

(8-45)
前 r 个主成分的累计贡献率为:
(8-46)
贡献率表示所定义的主成分在整个数据分析中承担的主要意义占多大的比重,当取前 r个主成分来代替原来全部变量时,累计贡献率的大小反应了这种取代的可靠性,累计贡献率越大,可靠性越大;反之,则可靠性越小。一般要求累计贡献率达到70% 以上。
经过PCA分析,一个多变量的复杂问题被简化为低维空间的简单问题。可以利用这种简化方法进行作图,形象地表示和分析复杂问题。在分析基因表达数据时,可以针对基因作图,也可以针对实验条件作图。前者称为Q 分析,后者称为 R 分析。
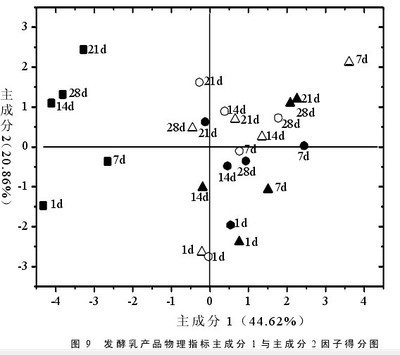
表8.1 是对酵母 6000 多个基因在 7 个时间点表达数据的 PCA分析结果,每列数据代表主元素的系数。从表中可以看出,前两个主元素反应了 90% 以上( 76.9%+13.5%)的变化,而前三个主元素反应了 95% 以上的变化,因此取前两个主元素即可。 图 8.6 是对 7 个特征值的图示。
图8.7 是前三个主元素系数变化图。第 1 个主元素代表各个基因表达加权平均,除第 1 个时间点外,其它所有系数都为正值( 见图8.7(a) )。如果某个基因对应此主元素的值为较大的正数,则基因表达上调,如果此主元素的值为较大的负数,则基因表达下调。第 2个主元素表示在时间序贯中基因表达的变化,除第 1 个时间点外,其它系数逐个增大( 见图 8.7(b))。如果某个基因的表达量随时间不断增加,则此主元素的值为正;如果表达量随时间不断减小,则此主元素的值为负。第 3个主元素系数变化曲线为抛物线形( 见图 8.7(c) )。