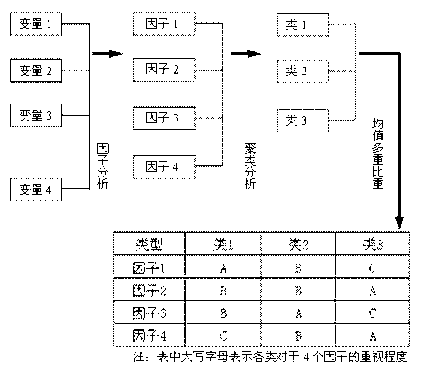
多元回归分析
在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。可以建立因变量y与各自变量xj(j=1,2,3,…,n)之间的多元线性回归模型:
其中:b0是回归常数;bk(k=1,2,3,…,n)是回归参数;e是随机误差。
多元回归在病虫预报中的应用实例:
某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。分级别数值列成表2-1。
预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1
x1 | x2 | x3 | x4 | y | ||||||
年 | 蛾量 | 级别 | 卵量 | 级别 | 降水量 | 级别 | 雨日 | 级别 | 幼虫密度 | 级别 |
1960 | 1022 | 4 | 112 | 1 | 4.3 | 1 | 2 | 1 | 10 | 1 |
1961 | 300 | 1 | 440 | 3 | 0.1 | 1 | 1 | 1 | 4 | 1 |
1962 | 699 | 3 | 67 | 1 | 7.5 | 1 | 1 | 1 | 9 | 1 |
1963 | 1876 | 4 | 675 | 4 | 17.1 | 4 | 7 | 4 | 55 | 4 |
1965 | 43 | 1 | 80 | 1 | 1.9 | 1 | 2 | 1 | 1 | 1 |
1966 | 422 | 2 | 20 | 1 | 0 | 1 | 0 | 1 | 3 | 1 |
1967 | 806 | 3 | 510 | 3 | 11.8 | 2 | 3 | 2 | 28 | 3 |
1976 | 115 | 1 | 240 | 2 | 0.6 | 1 | 2 | 1 | 7 | 1 |
1971 | 718 | 3 | 1460 | 4 | 18.4 | 4 | 4 | 2 | 45 | 4 |
1972 | 803 | 3 | 630 | 4 | 13.4 | 3 | 3 | 2 | 26 | 3 |
1973 | 572 | 2 | 280 | 2 | 13.2 | 2 | 4 | 2 | 16 | 2 |
1974 | 264 | 1 | 330 | 3 | 42.2 | 4 | 3 | 2 | 19 | 2 |
1975 | 198 | 1 | 165 | 2 | 71.8 | 4 | 5 | 3 | 23 | 3 |
1976 | 461 | 2 | 140 | 1 | 7.5 | 1 | 5 | 3 | 28 | 3 |
1977 | 769 | 3 | 640 | 4 | 44.7 | 4 | 3 | 2 | 44 | 4 |
1978 | 255 | 1 | 65 | 1 | 0 | 1 | 0 | 1 | 11 | 2 |
数据保存在“DATA6-5.SAV”文件中。
1)准备分析数据
在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”和“幼虫密度”变量,并输入数据。再创建蛾量、卵量、降水量、雨日和幼虫密度的分级变量“x1”、“x2”、“x3”、“x4”和“y”,它们对应的分级数值可以在SPSS数据编辑窗口中通过计算产生。编辑后的数据显示如图2-1。
图2-1
或者打开已存在的数据文件“DATA6-5.SAV”。
2)启动线性回归过程
单击SPSS主菜单的“Analyze”下的“Regression”中“Linear”项,将打开如图2-2所示的线性回归过程窗口。
图2-2 线性回归对话窗口
3) 设置分析变量
设置因变量:用鼠标选中左边变量列表中的“幼虫密度[y]”变量,然后点击“Dependent”栏左边的向右拉按钮,该变量就移到“Dependent”因变量显示栏里。
设置自变量:将左边变量列表中的“蛾量[x1]”、“卵量[x2]”、“降水量[x3]”、“雨日[x4]”变量,选移到“Independent(S)”自变量显示栏里。
设置控制变量:本例子中不使用控制变量,所以不选择任何变量。
选择标签变量: 选择“年份”为标签变量。
选择加权变量:本例子没有加权变量,因此不作任何设置。
4)回归方式
本例子中的4个预报因子变量是经过相关系数法选取出来的,在回归分析时不做筛选。因此在“Method”框中选中“Enter”选项,建立全回归模型。
5)设置输出统计量
单击“Statistics”按钮,将打开如图2-3所示的对话框。该对话框用于设置相关参数。其中各项的意义分别为:
图2-3 “Statistics”对话框
①“RegressionCoefficients”回归系数选项:
“Estimates”输出回归 系数和相关统计量。
“Confidence interval”回归系数的95%置信区间。
“Covariancematrix”回归系数的方差-协方差矩阵。
本例子选择“Estimates”输出回归系数和相关统计量。
②“Residuals”残差选项:
“Durbin-Watson”Durbin-Watson检验。
“Casewisediagnostic”输出满足选择条件的观测量的相关信息。选择该项,下面两项处于可选状态:
“Outliers outside standarddeviations”选择标准化残差的绝对值大于输入值的观测量;
“All cases”选择所有观测量。
本例子都不选。
③其它输入选项
“Model fit”输出相关系数、相关系数平方、调整系数、估计标准误、ANOVA表。
“R squaredchange”输出由于加入和剔除变量而引起的复相关系数平方的变化。
“Descriptives”输出变量矩阵、标准差和相关系数单侧显著性水平矩阵。
“Part and partialcorrelation”相关系数和偏相关系数。
“Collinearitydiagnostics”显示单个变量和共线性分析的公差。
本例子选择“Model fit”项。
6)绘图选项
在主对话框单击“Plots”按钮,将打开如图2-4所示的对话框窗口。该对话框用于设置要绘制的图形的参数。图中的“X”和“Y”框用于选择X轴和Y轴相应的变量。
图2-4“Plots”绘图对话框窗口
左上框中各项的意义分别为:
“Standardized ResidualPlots”设置各变量的标准化残差图形输出。其中共包含两个选项:
“Histogram”用直方图显示标准化残差。
“Normal probabilityplots”比较标准化残差与正态残差的分布示意图。
“Produce all partialplot”偏残差图。对每一个自变量生成其残差对因变量残差的散点图。
事务所业务:
1.为学生毕业论文、公司、高校课题提供spss、LISREL、Amos等数据分析服务。
2.为公司、高校和科研机构提供价格优惠的调查问卷数据录入服务。
3.为课题提供量化统计指导和咨询。
联系方式:
QQ:3098529344
电话:18375425162
公司地址:山东省青岛市平度市白沙河街道办事处256号