发布时间:2022年04月15日 04:49:22分享人:我姓陈我心沉来源:互联网15
Distributed Representations of Sentences andDocuments是Mikolov继word2vec后的另一力作——将文本表示为矢量。将文本表示为矢量,是大量文本处理相关算法(文本分类、聚类等)的必然要求。最简单、最直观的方法是bag-of-words(BOW),即将文本拆解为单词,以单词作为矢量空间的维度,以每个单词在文本中出现的频率作为文本矢量对应维度的值。BOW的缺点是忽略了词语在文本中出现的先后次序,并且没有考虑词语的语义信息。另外一种方法bag-of-n-grams考虑了词序,却增加了维度,加剧了数据稀疏。 在直接考虑语义的情况下,假设已经有了单词矢量的获取方法,且单词能够包含了词语的语义信息,那么一种直接的方法是对一篇文档中包含的单词矢量加权平均,得到的新矢量即为该文档的矢量(Mitchell& Lapata, 2010; Zanzotto et al., 2010; Yessenalina &Cardie, 2011; Grefenstette et al., 2013; Mikolov et al.,2013c). 另一种较复杂的方法是按照句子解析树的词序,将句子组织为矩阵而非矢量,该方法不能应用于文档,只局限于句子,因为方法的核心是句子的解析。(Socheret al., 2011b).PV-DM类似于Mikolov13年论文中提到的CBOW方法。以三层神经网络作为框架,CBOW使用围绕目标单词的其他单词(语境)作为输入,在映射层做加权处理后输出目标单词。在训练过程中,模型以最大化目标单词输出概率为目标,使用随机梯度下降方法达到收敛。该方法的代码在code.google.com/p/word2vec/上可下载。 与CBOW类似,PV-DM仍以最大化目标单词输出概率为目标,使用随机梯度下降方法达到收敛。区别是在输入层增加了paragraphvector,新增的paragraphvector可以简单的被看做增加了一个新的单词作为输入。每当预测一个单词时,就使用该单词所在段落的paragraphvector作为新增输入。该模型总体有两步,加粗字体叙述的是第一步,旨在训练得到单词的表示和模型中的其他参数;第二步是使用得到的模型预测最终的paragraphvectors。在第二步中,单词矢量和其他参数保持不变,仍然使用梯度下降方法,采用随机抽样,使得所有语境(所有语境仅指当前paragraph包含的语境)下出现对应paragraph的平均概率最大。如图一所示:Figure 1. A framework for learning paragraphvector. This frame-work is similar to the framework presented inFigure 1; the only change is the additional paragraph token that ismapped to a vec-tor via matrix D. In this model, the concatenationor average of this vector with a context of three words is used topredict the fourth word. The paragraph vector represents themissing infor-mation from the current context and can act as amemory of the topic of the paragraph. 作者称这个模型为Distributed MemoryModel of Paragraph Vectors (PV-DM),因为新增的paragraph vector可以看做输入单词构成的语境信息的补充(a memory that remembers whatis missing from the current context),也可以看做是对应paragraph的主题。参照Skip-gram根据当前单词预测语境,PV-DBOW根据paragraph预测语境,如图2所示:
Figure 3. Distributed Bag of Wordsversion of paragraph vectors. In this version, the paragraph vectoris trained to predict the words in a small window. 该方法以paragraphvector作为输入,然后从该vector对应的paragraph中随机采样单词序列(语境)作为输出。和skip-gram类似,该方法减少了输入层的参数量。作者认为PV-DM单独使用效果不错,PV-DM和PV-DBOW的结合能够产生更好的效果。- Distributed Representations of Sentences and Documents

爱华网本文地址 » http://www.413yy.cn/a/25101015/267197.html
更多阅读

此稿已于2011年9月28日见报探索扶贫工作的新思路和新方法——访中共中央党校超越之路课题负责人刘德喜教授王馨编者的话:日前某民间组织搞的“中国西部百强县(市)”评比,榜单中竟出现了17个国家级贫困县,如此滑稽之事,把有关扶贫的
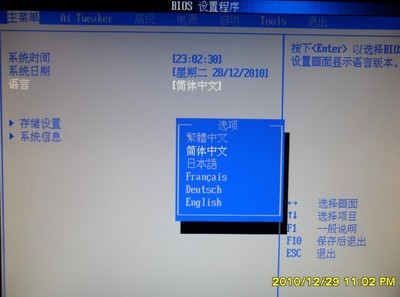
利用BIOS启动联想一键恢复的新思路联想, BIOS联想, BIOS, 思路本帖最后由 luck9806 于 2011-2-19 13:37 编辑朋友新买了台联想电脑,安装了双系统,后来将工厂备份重新写入安装后的系统,结果想不到,此恢复系统可以将WINXP与WIN7同时进

县级供电企业是电力企业的基层单位,服务的供电区域广,服务的客户类型多,担负的供电任务重,其员工的思想政治教育工作不容忽视,针对当前供电企业发展特点及思想政治教育工作中存在的问题,浅谈员工思想政治教育的新思路。 随着

现代餐饮管理的新思路就是运用市场经济的理论,结合餐饮行业的实际,为餐饮企业在市场激烈竞争中如何获得成功而设计的一些思路。现代餐饮管理的重点是市场营销、人员管理和财务管理。 市场营销 市场营销就是要以市场为起点,以顾

现代餐饮管理的新思路就是运用市场经济的理论,结合餐饮行业的实际,为餐饮企业在市场激烈竞争中如何获得成功而设计的一些思路。现代餐饮管理的重点是市场营销、人员管理和财务管理。 市场营销 市场营销就是要以市场为