今天看存储过程的时候发现了两个函数Rollup()和Cube(),感觉很陌生,于是网上一通查,当想做笔记的时候,发现笔记本上曾近有这两个函数,,记忆力减退的不是一星半点啊。或许是我之前一直没有好好理解这两个函数,在工作中也很少用到,之前做采集的时候都是使用的ODI工具,很少使用存储过程。而且最经也将oracle放置了好久,今天起开始一天天的拾起来。
Rollup():分组函数可以理解为group by的精简模式,具体分组模式如下:
Rollup(a,b,c): (a,b,c),(a,b),(a),(全表)
Cube():分组函数也是以group by为基础,具体分组模式如下:
cube(a,b,c):(a,b,c),(a,b),(a,c),(b,c),(a),(b),(c),(全表)
下面准备数据比较一下两个函数的不同:
1、准备数据:
2、使用rollup函数查询
select group_id,job,name,sum(salary) from GROUP_TEST group byrollup(group_id,job,name);
3、使用cube函数:
select group_id,job,name,sum(salary) from GROUP_TEST group bycube(group_id,job,name)
4、对比:从最后查询出来的数据条数就差了好多,下面看一下将两个函数从转化成对应的group函数语句:
rollup函数:
select group_id,job,name,sum(salary) from GROUP_TEST group byrollup(group_id,job,name);
等价于:
select group_id,job,name,sum(salary) from GROUP_TEST group bygroup_id,job,name
union all
select group_id,job,null,sum(salary) from GROUP_TEST group bygroup_id,job
union all
select group_id,null,null,sum(salary) from GROUP_TEST group bygroup_id
union all
select null,null,null,sum(sal ary) from GROUP_TEST
cube函数:
select group_id,job,name,sum(salary) from GROUP_TEST group bycube(group_id,job,name) ;
等价于:
select group_id,job,name,sum(salary) from GROUP_TEST group bygroup_id,job,name
union all
select group_id,job,null,sum(salary) from GROUP_TEST group bygroup_id,job
union all
select group_id,null,name,sum(salary) from GROUP_TEST group bygroup_id,name
union all
select group_id,null,null,sum(salary) from GROUP_TEST group bygroup_id
union all
select null,job,name,sum(salary) from GROUP_TEST group byjob,name
union all
select null,job,null,sum(salary) from GROUP_TEST group by job
union all
select null,null,name,sum(salary) from GROUP_TEST group byname
union all
select null,null,null,sum(salary) from GROUP_TEST
5、由此可见两个函数对于汇总统计来说要比普通函数好用的多,另外还有一个配套使用的函数
grouping(**):当**字段为null的时候值为1,当字段**非null的时候值为0;
select grouping(group_id),job,name,sum(salary) from GROUP_TESTgroup by rollup(group_id,job,name);
6、添加一列用来直观的显示所有的汇总字段:
select group_id,job,name,
case when name is null and nvl(group_id,0)=0 andjob is null then '全表聚合'
when name is null andnvl(group_id,0)=0 and job is not null then 'JOB聚合'
when name is nulland grouping(group_id)=0 and job is null then'GROUPID聚合'
when name is not null andnvl(group_id,0)=0 and job isnull then 'Name聚合'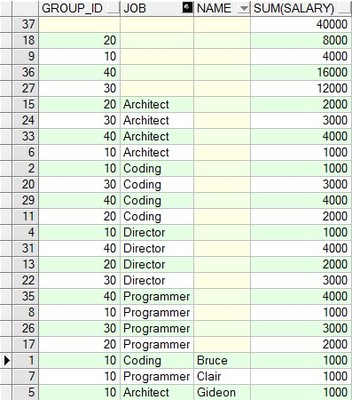
when name is not null andgrouping(group_id)=0 and job isnull then 'GROPName聚合'
when name is not null andgrouping(group_id)=1 and job is notnull then 'JOBName聚合'
when name isnull and grouping(group_id)=0 and job is notnull then 'GROUPJOB聚合'
else
'三列汇总' end ,
sum(salary) from GROUP_TEST group by cube(group_id,job,name);