由于内容比较多,直接上源码了,注释比较详细。下面的内容直接复制,基本就可以进行分析了。配图稍后再传。
library(Rwordseg)#载入分词包
library(tm)#载入文本挖掘包
#第一部分:分词
#把要分析的文件,存为文本文件(txt后缀),放到某个目录
#1、装载自定义词库(这里的自定义词库,是根据分析文件中的某些特殊用词,自己编写的一个词库文件,其实也是一个文本文件,每行一个词。为什么要装自定义词库勒,是为了准确进行分词。某些单词如果不设置为自定义词,那么分词的时候可能会分解成其他的词汇。比如"中国电信",如果不设置为自定义词,那么就会被分解为"中国电信";如果设置为自定义词,那么就会识别为一个词。
installDict(file.choose(),"mydict")#装载
listDict()#查看词典
#2、分词
segmentCN(file.choose(),returnType="tm")#这种模式分词后,会在分词文件的同一个目录生成一个"源文件名+.segment"的文本文件,就是分词的结果。Rwordseg的特点是分词很快。
#必须要注意,用Rwordseg分词后的文本文件,其编码格式是"UTF-8无BOM编码格式",这种编码用TM包读入后,全是乱码。解决办法是用windows自带的记事本打开,然后另存,另存的时候选择编码格式为"ANSI"。此处乃深刻教训,试了很长世间才发现是这里的问题,俺用notepad++调整编码也没有成功。
#第二部分:建立语料库
#这部分是读入分词后的文件,然后用TM包进行整理,清洗,变换成用于分析的"语料库"。
#1、读入分词后的文本
mydoc<-readLines(file.choose())
#2、建立语料库(这里读取文本到变量,根据文本变量来建立语料库)
mydoc.vec<-VectorSource(mydoc)
mydoc.corpus<-Corpus(mydoc.vec)
#3、删除停用词(就是删除一些介词、叹词之类的词语,这些词语本身没多大分析意义,但出现的频率却很高,比如"的、地、得、啊、嗯、呢、了、还、于是、那么、然后"等等。前提是必须要有一个停用词库,网上搜索即可下载,也是一个txt的文本文件,每行一个词。网上有两种版本,一种是500多个词的,一种是1000多个词的)
data_stw=read.table(file=file.choose(),colClasses="character")#读取停用词,挨个转换到一个列表中
stopwords_CN=c(NULL)
for(i in1:dim(data_stw)[1]){
stopwords_CN=c(stopwords_CN,data_stw[i,1])
}
mydoc.corpus<-tm_map(mydoc.corpus,removeWords,stopwords_CN)#删除停用词
#4、进一步清洗数据
mydoc.corpus<-tm_map(mydoc.corpus,removeNumbers)#删除数字
mydoc.corpus<-tm_map(mydoc.corpus,stripWhitespace)#删除空白
#第三部分:进行内容分析
#到这里要分析的数据已经准备好了,可以进行各种分析了,下面以聚类分析为例。
#1、建立TDM矩阵(TDM就是"词语×文档"的矩阵)
control=list(removePunctuation=T,minDocFreq=5,wordLengths= c(1, Inf),weighting = weightTfIdf)#设置一些建立矩阵的参数,用变量control来存储参数,控制如何抽取文档
#removePunctuation表示去除标点
#minDocFreq=5表示只有在文档中至少出现5次的词才会出现在TDM的行中
#tm包默认TDM中只保留至少3个字的词(对英文来说比较合适,中文就不适用了吧……),wordLengths= c(1, Inf)表示字的长度至少从1开始。
#默认的加权方式是TF,即词频,这里采用Tf-Idf,该方法用于评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度:
mydoc.tdm=TermDocumentMatrix(mydoc.corpus,control)#建立矩阵
#在一份给定的文件里,词频 (term frequency,TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
#逆向文件频率 (inverse documentfrequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
#某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于保留文档中较为特别的词语,过滤常用词。
#2、降维(词太多了,不好聚类,所以需要降维,就是减少词的数量,把不重要的词剔除)
length(mydoc.tdm$dimnames$Terms)#查看原来有多少词
tdm_removed<-removeSparseTerms(mydoc.tdm,0.9)#降维,去除了低于99%的稀疏条词,这里的参数可以自行调整,反复测试,直到词语数量满足你的研究需要
length(tdm_removed$dimnames$Terms)#查看降维后剩下多少词,数量不对的话,可以重新执行上一句
#3、查找高频词
findFreqTerms(mydoc.tdm,3)#列出高频词
#4、找到与某个单词相关系数为?的单词
findAssocs(mydoc.tdm,"人力资源",0.5)#列出与"人力资源"相关系数大于等于0.5的词
#5、文本聚类
#dissimilarty函数在最新的tm包中已经去掉,改为proxy中的dist函数
mydata<-as.data.frame(inspect(tdm_removed))#转换分析数据为数据框结构
mydata.scale<-scale(mydata)#
d<-dist(mydata.scale,method="euclidean")#计算矩阵距离,需要注意,原来的函数tm包中的这个功能的函数是dissimilarty,在最新的tm包中已经去掉,改为proxy中的dist函数
fit<-hclust(d,method="ward.D")#聚类分析
plot(fit)#用一张图展示聚类的结果
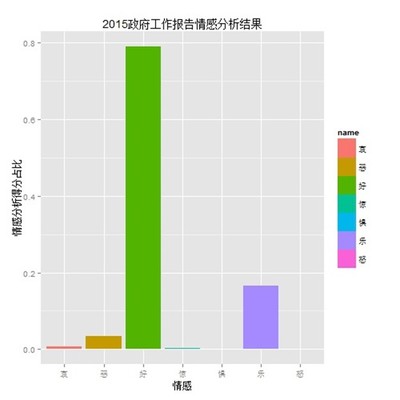
下图是对2014年政府工作报告的分析聚类结果图: