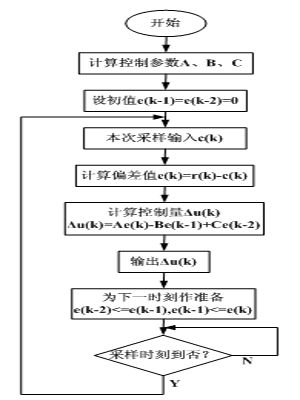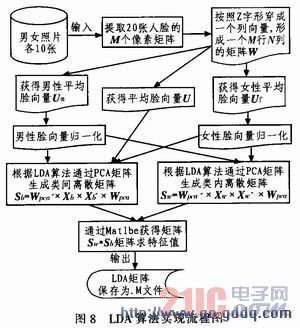
LDA整体流程
先定义一些字母的含义:
LDA以文档集合D作为输入(会有切词,去停用词,取词干等常见的预处理,略去不表),希望训练出的两个结果向量(设聚成k个Topic,VOC中共包含m个词):
LDA的核心公式如下:
p(w|d) = p(w|t)*p(t|d)
直观的看这个公式,就是以Topic作为中间层,可以通过当前的θd和φt给出了文档d中出现单词w的概率。其中p(t|d)利用θd计算得到,p(w|t)利用φt计算得到。
实际上,利用当前的θd和φt,我们可以为一个文档中的一个单词计算它对应任意一个Topic时的p(w|d),然后根据这些结果来更新这个词应该对应的topic。然后,如果这个更新改变了这个单词所对应的Topic,就会反过来影响θd和φt。
LDA学习过程
LDA算法开始时,先随机地给θd和φt赋值(对所有的d和t)。然后上述过程不断重复,最终收敛到的结果就是LDA的输出。再详细说一下这个迭代的学习过程:
1)针对一个特定的文档ds中的第i单词wi,如果令该单词对应的topic为tj,可以把上述公式改写为:
pj(wi|ds)= p(wi|tj)*p(tj|ds)
先不管这个值怎么计算(可以先理解成直接从θds和φtj中取对应的项。实际没这么简单,但对理解整个LDA流程没什么影响,后文再说)。
2)现在我们可以枚举T中的topic,得到所有的pj(wi|ds),其中j取值1~k。然后可以根据这些概率值结果为ds中的第i个单词wi选择一个topic。最简单的想法是取令pj(wi|ds)最大的tj(注意,这个式子里只有j是变量),即
argmax[j]pj(wi|ds)
当然这只是一种方法(好像还不怎么常用),实际上这里怎么选择t在学术界有很多方法,我还没有好好去研究。
3)然后,如果ds中的第i个单词wi在这里选择了一个与原先不同的topic,就会对θd和φt有影响了(根据前面提到过的这两个向量的计算公式可以很容易知道)。它们的影响又会反过来影响对上面提到的p(w|d)的计算。对D中所有的d中的所有w进行一次p(w|d)的计算并重新选择topic看作一次迭代。这样进行n次循环迭代之后,就会收敛到LDA所需要的结果了。