英雄各有高见。这里我就不对Hadoop的优势缺点等等一一介绍了,相信大家都有自己的见解。下面,我就如何分析Hadoop代码,谈一谈我个人的一些见解。
1) 先运行hadoop的例子。这个可以以wordCount开始,这是我们了解hadoop的一个很有效的手段。
2) 分析wordCount.java代码。网上比比皆是。
3) 开始看代码,怎么看?
在src总有test文件夹,你将它拿到Eclipse中,然后将一些必须的jar包配置到工程路径中。然后,我在该工程中写一个WordCount,然后运行。你就可以使用debugger跟踪程序的进程了。这个确实很赞。这样你来分析Map/Reduce事半功倍。
4)我把一个最为重要的函数贴到这里,供有些不愿做上面工作的朋友们分析一下。这个比你们看论文讲解的要生动得多。
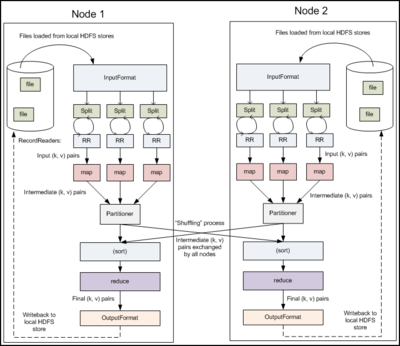
该函数是LocalJobRunner.Job类的run方法,该类继承了Thread类,并在构造函数中启动了线程。
这个函数基本上把MapReduce主要的过程介绍了一遍,需要研究Map/Reduce的朋友可以先从Local的
MapReduce任务看起,然后再去看集群的MapReduce的过程。
public void run(){
JobID jobId = profile.getJobID();
JobContext jContext = new JobContext(conf, jobId);
OutputCommitter outputCommitter =job.getOutputCommitter();
try {
// split input into minimum number of splits
RawSplit[] rawSplits;
if (job.getUseNewMapper()) {
org.apache.hadoop.mapreduce.InputFormat<?,?>input =
ReflectionUtils.newInstance(jContext.getInputFormatClass(),
jContext.getJobConf());
List<org.apache.hadoop.mapreduce.InputSplit>splits = input.getSplits(jContext);
rawSplits = new RawSplit[splits.size()];
DataOutputBuffer buffer = new DataOutputBuffer();
SerializationFactory factory = newSerializationFactory(conf);
Serializer serializer =
factory.getSerializer(splits.get(0).getClass());
serializer.open(buffer);
for (int i = 0; i < splits.size(); i++){
buffer.reset();
serializer.serialize(splits.get(i));
RawSplit rawSplit = new RawSplit();
rawSplit.setClassName(splits.get(i).getClass().getName());
rawSplit.setDataLength(splits.get(i).getLength());
rawSplit.setBytes(buffer.getData(), 0,buffer.getLength());
rawSplit.setLocations(splits.get(i).getLocations());
rawSplits[i] = rawSplit;
}
} else {
InputSplit[] splits = job.getInputFormat().getSplits(job,1);
rawSplits = new RawSplit[splits.length];
DataOutputBuffer buffer = new DataOutputBuffer();
for (int i = 0; i < splits.length; i++){
buffer.reset();
splits[i].write(buffer);
RawSplit rawSplit = new RawSplit();
rawSplit.setClassName(splits[i].getClass().getName());
rawSplit.setDataLength(splits[i].getLength());
rawSplit.setBytes(buffer.getData(), 0,buffer.getLength());
rawSplit.setLocations(splits[i].getLocations());
rawSplits[i] = rawSplit;
}
}
int numReduceTasks = job.getNumReduceTasks();
if (numReduceTasks > 1 || numReduceTasks< 0) {
// we only allow 0 or 1 reducer in local mode
numReduceTasks = 1;
job.setNumReduceTasks(1);
}
outputCommitter.setupJob(jContext);
status.setSetupProgress(1.0f);
for (int i = 0; i < rawSplits.length; i++){
if (!this.isInterrupted()) {
TaskAttemptID mapId = new TaskAttemptID(new TaskID(jobId, true,i),0);
mapIds.add(mapId);
MapTask map = newMapTask(file.toString(),
mapId, i,
rawSplits[i].getClassName(),
rawSplits[i].getBytes());
JobConf localConf = new JobConf(job);
map.setJobFile(localFile.toString());
map.localizeConfiguration(localConf);
map.setConf(localConf);
map_tasks += 1;
myMetrics.launchMap(mapId);
map.run(localConf, this);
myMetrics.completeMap(mapId);
map_tasks -= 1;
updateCounters(map);
} else {
throw new InterruptedException();
}
}
TaskAttemptID reduceId =
new TaskAttemptID(new TaskID(jobId, false, 0), 0);
try {
if (numReduceTasks > 0) {
// move map output to reduceinput
for (int i = 0; i < mapIds.size(); i++){
if (!this.isInterrupted()) {
TaskAttemptID mapId = mapIds.get(i);
Path mapOut =this.mapoutputFile.getOutputFile(mapId);
Path reduceIn =this.mapoutputFile.getInputFileForWrite(
mapId.getTaskID(),reduceId,
localFs.getLength(mapOut));
if (!localFs.mkdirs(reduceIn.getParent())) {
throw new IOException("Mkdirs failed to create "
+ reduceIn.getParent().toString());
}
if (!localFs.rename(mapOut, reduceIn))
throw new IOException("Couldn't rename " +mapOut);
} else {
throw new InterruptedException();
}
}
if (!this.isInterrupted()) {
ReduceTask reduce = newReduceTask(file.toString(),
reduceId, 0, mapIds.size());
JobConf localConf = new JobConf(job);
reduce.setJobFile(localFile.toString());
reduce.localizeConfiguration(localConf);
reduce.setConf(localConf);
reduce_tasks += 1;
myMetrics.launchReduce(reduce.getTaskID());
reduce.run(localConf, this);
myMetrics.completeReduce(reduce.getTaskID());
reduce_tasks -= 1;
updateCounters(reduce);
} else {
throw new InterruptedException();
}
}
} finally {
for (TaskAttemptID mapId: mapIds) {
this.mapoutputFile.removeAll(mapId);
}
if (numReduceTasks == 1) {
this.mapoutputFile.removeAll(reduceId);
}
}
// delete the temporary directory in outputdirectory
outputCommitter.cleanupJob(jContext);
status.setCleanupProgress(1.0f);
if (killed) {
this.status.setRunState(JobStatus.KILLED);
} else {
this.status.setRunState(JobStatus.SUCCEEDED);
}
JobEndNotifier.localRunnerNotification(job,status);
} catch (Throwable t) {
try {
outputCommitter.cleanupJob(jContext);
} catch (IOException ioe) {
LOG.info("Error cleaning up job:" + id);
}
status.setCleanupProgress(1.0f);
if (killed) {
this.status.setRunState(JobStatus.KILLED);
} else {
this.status.setRunState(JobStatus.FAILED);
}
LOG.warn(id, t);
JobEndNotifier.localRunnerNotification(job,status);
} finally {
try {
fs.delete(file.getParent(), true); // deletesubmit dir
localFs.delete(localFile,true);// delete local copy
} catch (IOException e) {
LOG.warn("Error cleaning up "+id+": "+e);
}
}
}
谢谢您的阅读。