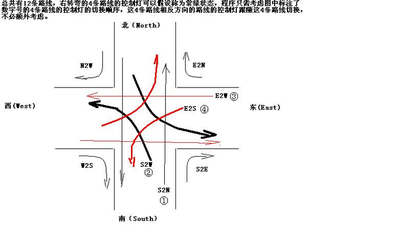
本次,开始分解季节性时间序列。
一个季节性时间序列中会包含三部分,趋势部分、季节性部分和无规则部分。分解时间序列就是要把时间序列分解成这三部分,然后进行估计。
对于可以使用相加模型进行描述的时间序列中的趋势部分和季节性部分,我们可以使用R中的“decompose()” 函数来估计。这个函数可以估计出时间序列中趋势的、季节性的和不规则的部分,而此时间序列须是可以用相加模型描述的。
“decompose()” 这个函数返回的结果是一个列表对象, 里面包含了估计出的季节性部分,趋势部分和不规则部分,他们分别对应的列表对象元素名为“seasonal” 、 “trend” 、 和“random”。
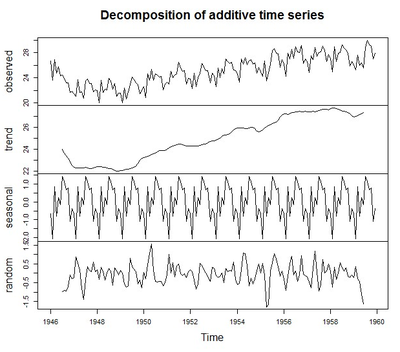
示例:纽约每月出生人口数量是在夏季有峰值、 冬季有低谷的时间序列。> births<-scan("http://robjhyndman.com/tsdldata/data/nybirths.dat")Read 168 items> birthstimeseries <- ts(births,frequency=12, start=c(1946,1))> ts.plot(birthstimeseries)
> birthcomponents <-decompose(birthstimeseries)> plot(birthcomponents)而当你需要剔除某个趋势时(我们就去掉季节因素),我们可以运用减法去掉该因素,下图就是去掉季节性因素后的修正序列。>birthstimeseriesseasonallyadjusted<-birthstimeseries-birthcomponents$seasonal>plot(birthstimeseriesseasonallyadjusted)留下记录,供日后复习应用。