发表时间:2012-2-20 罗军舟 金嘉晖 宋爱波 东方 来源:万方数据
关键字:云计算 虚拟化 数据中心 海量数据处理 服务质量 安全
信息化调查找茬投稿收藏评论好文推荐打印社区分享
本文系统地分析和总结云计算的研究现状,划分云计算体系架构为核心服务、服务管理、用户访问接口等3个层次。围绕低成本、高可靠、高可用、规模可伸缩等研究目标,深入全面地介绍了云计算的关键技术及最新研究进展。在云计算基础设施方面,介绍了云计算数据中心设计与管理及资源虚拟化技术:在大规模数据处理方面,分析了海量数据处理平台及其资源管理与调度技术;在云计算服务保障方面,讨论了服务质量保证和安全与隐私保护技术。针对新型的云计算应用和云计算存在的局限性,又探讨并展望了今后的研究方向。最后,介绍了东南大学云计算平台以及云计算研究与应用方面的相关成果。
1引言
近年来,社交网络、电子商务、数字城市、在线视频等新一代大规模互联网应用发展迅猛。这些新兴的应用具有数据存储量大、业务增长速度快等特点。据统计至2010年,社交网站Facebook己存储了15TB的数据,并且每天新增60TB数据;电子商务网站淘宝的B2C业务在2010年增长了4倍,其数据中心存储了14PB数据,并且每天需要处理SOOTB数据。与此同时,传统企业的软硬件维护成本高昂;在企业的IT投入中,仅有20%的投入用于软硬件更新与商业价值的提升,而80%则投入用于系统维护。根据2006年IDC对200家企业的统计,部分企业的信息技术人力成本达到1320美元/每人/每台服务器,而部署一个新的应用系统需要花费5.4周。
为了解决上述问题,2006年Google、Amazon等公司提出了“云计算”的构想。根据美国国家标准与技术研究院(NIST)的定义,云计算是一种利用互联网实现随时随地、按需、便捷地访问共享资源池(如计算设施、存储设备、应用程序等)的计算模式。计算机资源服务化是云计算重要的表现形式,它为用户屏蔽了数据中心管理、大规模数据处理、应用程序部署等问题。通过云计算,用户可以根据其业务负载快速申请或释放资源,并以按需支付的方式对所使用的资源付费,在提高服务质量的同时降低运维成本。
作为信息产业的一大创新,云计算模式一经提出便得到工业界、学术界的广泛关注。其中Amazon等公司的云计算平台提供可快速部署的虚拟服务器,实现了基础设施的按需分配。MapReduce等新型并行编程框架简化了海量数据处理模型。Google公司的App Engine云计算开发平台为应用服务提供商开发和部署云计算服务提供接口。
Salesforce公司的客户关系管理(CRM, customerrelationship management)服务等云计算服务将桌面应用程序迁移到互联网,实现应用程序的泛在访问。同时,各国学者对云计算也展开了大量研究工作。早在2007年,斯坦福大学等多所美国高校便开始和Google, IBM合作,研究云计算关键技术。近年来,随着云计算研究的深入,众多国际会议(如SIGCOMM、OSDI, SIGMOD, CCS等)上陆续发表了云计算相关研究成果.此外,以Eucalyptus为代表的开源云计算平台的出现,加速了云计算服务的研究和普及。
不仅如此,各国政府纷纷将云计算列为国家战略,投入了相当大的财力和物力用于云计算的部署。其中,美国政府利用云计算技术建立联邦政府网站,以降低政府信息化运行成本。英国政府建立国家级云计算平台(G-Cloud),超过2/3的英国企业开始使用云计算服务。在我国,北京、上海、深圳、杭州、无锡等城市开展了云计算服务创新发展试点示范工作;电信、石油石化、交通运输等行业也启动了相应的云计算发展计划,以促进产业信息化。
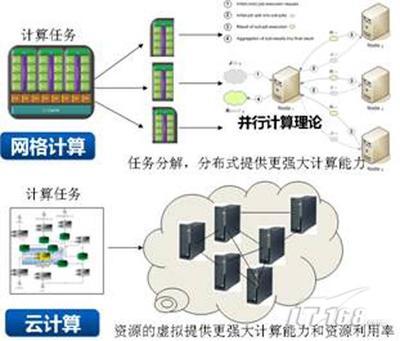
然而,云计算本质上并非一个全新的概念。早在1961年,计算机先驱John McCarthy就预言:“未来的计算资源能像公共设施(如水、电)一样被使用。”为了实现这个目标,在之后的几十年里,学术界和工业界陆续提出了集群计算、效用计算、网格计算、服务计算等技术,而云计算正是从这些技术发展而来。
在这些传统技术中,集群计算将大量独立的计算机通过高速局域网相连,从而提供高性能计算能力。效用计算为用户提供按需租用计算机资源的途径。网格计算整合大量异构计算机的闲置资源(如计算资源和磁盘存储等),组成虚拟组织,以解决大规模计算问题。服务计算作为连接信息技术和商业服务的桥梁,研究如何用信息技术对商业服务建模、操作和管理。
对云计算而言,其借鉴了传统分布式计算的思想。通常情况下,云计算采用计算机集群构成数据中心,并以服务的形式交付给用户,使得用户可以像使用水、电一样按需购买云计算资源。从这个角度看,云计算与网格计算的目标非常相似。但是云计算和网格计算等传统的分布式计算也有着较明显的区别:首先云计算是弹性的,即云计算能根据工作负载大小动态分配资源,而部署于云计算平台上的应用需要适应资源的变化,并能根据变化做出响应;其次,相对于强调异构资源共享的网格计算,云计算更强调大规模资源池的分享,通过分享提高资源复用率,并利用规模经济降低运行成本:最后,云计算需要考虑经济成本,因此硬件设备、软件平台的设计不再一味追求高性能,而要综合考虑成本、可用性、可靠性等因素。
基于上述比较并结合云计算的应用背景,云计算的特点可归纳如下。
1)弹性服务。服务的规模可快速伸缩,以自动适应业务负载的动态变化。用户使用的资源同业务的需求相一致,避免了因为服务器性能过载或冗余而导致的服务质量下降或资源浪费。
2)资源池化。资源以共享资源池的方式统一管理。利用虚拟化技术,将资源分享给不同用户,资源的放置、管理与分配策略对用户透明。
3)按需服务。以服务的形式为用户提供应用程序、数据存储、基础设施等资源,并可以根据用户需求,自动分配资源,而不需要系统管理员干预。
4)服务可计费。监控用户的资源使用量,并根据资源的使用情况对服务计费。
5)泛在接入。用户可以利用各种终端设备(如PC电脑、笔记本电脑、智能手机等)随时随地通过互联网访问云计算服务。
正是因为云计算具有上述5个特性,使得用户只需连上互联网就可以源源不断地使用计算机资源,实现了“互联网即计算机”的构想。
综上所述,云计算是分布式计算、互联网技术、大规模资源管理等技术的融合与发展(如图1所示),其研究和应用是一个系统工程,涵盖了数据中心管理、资源虚拟化、海量数据处理、计算机安全等重要问题。本文通过归纳云计算特点与体系架构,总结和分析云计算各层服务的关键技术及系统实例,针对当前云计算存在的问题,提出未来研究的方向。
图1云计算与相关技术的联系
2云计算体系架构
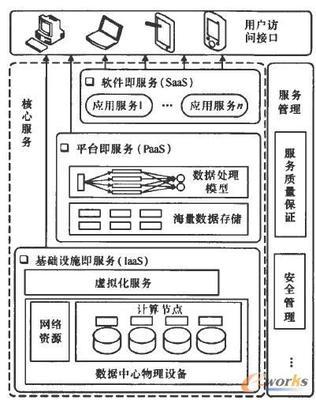
云计算可以按需提供弹性资源,它的表现形式是一系列服务的集合。结合当前云计算的应用与研究,其体系架构可分为核心服务、服务管理、用户访问接口3层,如图2所示。核心服务层将硬件基础设施、软件运行环境、应用程序抽象成服务,这些服务具有可靠性强、可用性高、规模可伸缩等特点,满足多样化的应用需求。服务管理层为核心服务提供支持,进一步确保核心服务的可靠性、可用性与安全性。用户访问接口层实现端到云的访问。
图2云计算体系架构
2.1核心服务层
云计算核心服务通常可以分为3个子层:基础设施即服务层(IaaS, infrastructure as a service )、平台即服务层(PaaS, platform as a service )、软件即服务层(SaaS, software as a service)。表1对3层服务的特点进行了比较。
IaaS提供硬件基础设施部署服务,为用户按需提供实体或虚拟的计算、存储和网络等资源。在使用IaaS层服务的过程中,用户需要向IaaS层服务提供商提供基础设施的配置信息,运行于基础设施的程序代码以及相关的用户数据。由于数据中心是IaaS层的基础,因此数据中心的管理和优化问题近年来成为研究热点。另外,为了优化硬件资源的分配,IaaS层引入了虚拟化技术。借助于Xen、KVM、VMware等虚拟化工具,可以提供可靠性高、可定制性强、规模可扩展的IaaS层服务。
PaaS是云计算应用程序运行环境,提供应用程序部署与管理服务。通过PaaS层的软件工具和开发语言,应用程序开发者只需上传程序代码和数据即可使用服务,而不必关注底层的网络、存储、操作系统的管理问题。由于目前互联网应用平台(如Facebook.Google、淘宝等)的数据量日趋庞大,PaaS层应当充分考虑对海量数据的存储与处理能力,并利用有效的资源管理与调度策略提高处理效率。
SaaS是基于云计算基础平台所开发的应用程序。企业可以通过租用SaaS层服务解决企业信息化问题,如企业通过GMail建立属于该企业的电子邮件服务。该服务托管于Google的数据中心,企业不必考虑服务器的管理、维护问题。对于普通用户来讲,SaaS层服务将桌面应用程序迁移到互联网,可实现应用程序的泛在访问。
表1
2.2服务管理层
服务管理层对核心服务层的可用性、可靠性和安全性提供保障。服务管理包括服务质量(QoS,quality of service)保证和安全管理等。
云计算需要提供高可靠、高可用、低成本的个性化服务。然而云计算平台规模庞大且结构复杂,很难完全满足用户的QoS需求。为此,云计算服务提供商需要和用户进行协商,并制定服务水平协议(SLA,service level agreement ),使得双方对服务质量的需求达成一致。当服务提供商提供的服务未能达到SLA的要求时,用户将得到补偿。
此外,数据的安全性一直是用户较为关心的问题。云计算数据中心采用的资源集中式管理方式使得云计算平台存在单点失效问题。保存在数据中心的关键数据会因为突发事件(如地震、断电)、病毒入侵、黑客攻击而丢失或泄露。根据云计算服务特点,研究云计算环境下的安全与隐私保护技术(如数据隔离、隐私保护、访问控制等)是保证云计算得以广泛应用的关键。
除了QoS保证、安全管理外,服务管理层还包括计费管理、资源监控等管理内容,这些管理措施对云计算的稳定运行同样起到重要作用。
2.3用户访问接口层
用户访问接口实现了云计算服务的泛在访问,通常包括命令行、Web月及务、Web门户等形式。命令行和Web服务的访问模式既可为终端设备提供应用程序开发接口,又便于多种服务的组合。Web门户是访问接口的另一种模式。通过Web门户,云计算将用户的桌面应用迁移到互联网,从而使用户随时随地通过浏览器就可以访问数据和程序,提高工作效率。虽然用户通过访问接口使用便利的云计算服务,但是由于不同云计算服务商提供接口标准不同,导致用户数据不能在不同服务商之间迁移。为此,在Intel , Sun和Cisco等公司的倡导下,云计算互操作论坛(CCIF, cloud computing interop-erability forum)宣告成立,并致力于开发统一的云计算接口(UCI, unified cloud interface),以实现“全球环境下不同企业之间可利用云计算服务无缝协同工作”的目标。
3云计算关键技术
云计算的目标是以低成本的方式提供高可靠、高可用、规模可伸缩的个性化服务。为了达到这个目标,需要数据中心管理、虚拟化、海量数据处理、资源管理与调度、QoS保证、安全与隐私保护等若干关键技术加以支持。本节详细介绍核心服务层与服务管理层涉及的关键技术和典型应用,并从IaaS,PaaS、SaaS 3个方面依次对核心服务层进行分析。
3.1IaaS
IaaS层是云计算的基础。通过建立大规模数据中心,IaaS层为上层云计算服务提供海量硬件资源。同时,在虚拟化技术的支持下,IaaS层可以实现硬件资源的按需配置,并提供个性化的基础设施服务。基于以上两点,IaaS层主要研究2个问题:①如何建设低成本、高效能的数据中心;②如何拓展虚拟化技术,实现弹性、可靠的基础设施服务。
3.1.1 数据中心相关技术
数据中心是云计算的核心,其资源规模与可靠性对上层的云计算服务有着重要影响。Google、Facebook等公司十分重视数据中心的建设。在2009年,Facebook的数据中心拥有30 000个计算节点,截止2010年,计算节点数量更是达到60 000个;Google公司平均每季度投入约6亿美元用于数据中心建设,其中仅2010年第4季度便投入了25亿美元。
云计算:体系架构与关键技术(二)
发表时间:2012-2-21 罗军舟 金嘉晖 宋爱波 东方 来源:万方数据
关键字:云计算 虚拟化 数据中心 海量数据处理 服务质量
信息化调查找茬投稿收藏评论好文推荐打印社区分享
本文系统地分析和总结云计算的研究现状,划分云计算体系架构为核心服务、服务管理、用户访问接口等3个层次。围绕低成本、高可靠、高可用、规模可伸缩等研究目标,深入全面地介绍了云计算的关键技术及最新研究进展。在云计算基础设施方面,介绍了云计算数据中心设计与管理及资源虚拟化技术:在大规模数据处理方面,分析了海量数据处理平台及其资源管理与调度技术;在云计算服务保障方面,讨论了服务质量保证和安全与隐私保护技术。针对新型的云计算应用和云计算存在的局限性,又探讨并展望了今后的研究方向。最后,介绍了东南大学云计算平台以及云计算研究与应用方面的相关成果。
与传统的企业数据中心不同,云计算数据中心具有以下特点:
1)自治性。相较传统的数据中心需要人工维护,云计算数据中心的大规模性要求系统在发生异常时能自动重新配置,并从异常中恢复,而不影响服务的正常使用。
2)规模经济。通过对大规模集群的统一化标准化管理,使单位设备的管理成本大幅降低。
3)规模可扩展。考虑到建设成本及设备更新换代,云计算数据中心往往采用大规模高性价比的设备组成硬件资源,并提供扩展规模的空间。
基于以上特点,云计算数据中心的相关研究工作主要集中在以下2个方面:研究新型的数据中心网络拓扑,以低成本、高带宽、高可靠的方式连接大规模计算节点;研究有效的绿色节能技术,以提高效能比,减少环境污染.
①数据中心网络设计
目前,大型的云计算数据中心由上万个计算节点构成,而且节点数量呈上升趋势。计算节点的大规模性对数据中心网络的容错能力和可扩展性带来挑战。
然而,面对以上挑战,传统的树型结构网络拓扑(如图3所示)存在以下缺陷。首先,可靠性低,若汇聚层或核心层的网络设备发生异常,网络性能会大幅下降。其次,可扩展性差,因为核心层网络设备的端口有限,难以支持大规模网络。再次,网络带宽有限,在汇聚层,汇聚交换机连接边缘层的网络带宽远大于其连接核心层的网络带宽(带宽比例为80:1,甚至240:1),所以对于连接在不同汇聚交换机的计算节点来说,它们的网络通信容易受到阻塞。
为了弥补传统拓扑结构的缺陷,研究者提出了VL2, Portland, DCell, BCube等新型的网络拓扑结构。这些拓扑在传统的树型结构中加入了类似于mesh的构造,使得节点之间连通性与容错能力更高,易于负载均衡。同时,这些新型的拓扑结构利用小型交换机便可构建,使得网络建设成本降低,节点更容易扩展。
图3传统的树型网络拓扑
以Portland为例来说明网络拓扑结构,如图4所示。Portland借鉴了Fat-Tree拓扑的思想,可以由5k2/4个k口交换机连接k3/4个计算节点。Portland由边缘层、汇聚层、核心层构成。其中边缘层和汇聚层可分解为若干Pod,每一个Pod含k台交换机,分属边界层和汇聚层(每层k/2台交换机)。Pod内部以完全二分图的结构相连。边缘层交换机连接计算节点,每个Pod可连接k2/4个计算节点。汇聚层交换机连接核心层交换机,每个Pod连接k2/4台核心层交换机。基于Portland,可以保证任意两点之间有多条通路,计算节点在任何时刻两两之间可无阻塞通信,从而满足云计算数据中心高可靠性、高带宽的需求。同时,Portland可以利用小型交换机连接大规模计算节点,既带来良好的可扩展性,又降低了数据中心的建设成本。
图4 Portland网络拓扑
②数据中心节能技术
云计算数据中心规模庞大,为了保证设备正常工作,需要消耗大量的电能。据估计,一个拥有50 000个计算节点的数据中心每年耗电量超过1亿千瓦时,电费达到930万美元。因此需要研究有效的绿色节能技术,以解决能耗开销问题。实施绿色节能技术,不仅可以降低数据中心的运行开销,而且能减少二氧化碳的排放,有助于环境保护。
当前,数据中心能耗问题得到工业界和学术界广泛关注。Google的分析表明,云计算数据中心的能源开销主要来自计算机设备、不间断电源、供电单元、冷却装置、新风系统、增湿设备及附属设施(如照明、电动门等)。如图5所示,IT设备和冷却装置的能耗比重较大。因此,需要首先针对IT设备能耗和制冷系统进行研究,以优化数据中心的能耗总量或在性能与能耗之间寻求最佳的折衷。针对IT设备能耗优化问题,Nathuji等人提出一种面向数据中心虚拟化的自适应能耗管理系统Virtual Power,该系统通过集成虚拟化平台自身具备的能耗管理策略,以虚拟机为单位为数据中心提供一种在线能耗管理能力。Pallipadi等人根据CPU利用率,控制和调整CPU频率以达到优化IT设备能耗的目的。Rao等人研究多电力市场环境中,如何在保证服务质量前提下优化数据中心能耗总量的问题。针对制冷系统能耗优化问题,Samadiani等人综合考虑空间大小、机架和风扇的摆放以及空气的流动方向等因素,提出一种多层次的数据中心冷却设备设计思路,并对空气流和热交换进行建模和仿真,为数据中心布局提供理论支持。此外,数据中心建成以后,可采用动态制冷策略降低能耗。例如对于处于休眠的服务器,可适当关闭一些制冷设施或改变冷气流的走向,以节约成本。
图5 数据中心的能耗分布
3.1.2虚拟化技术
数据中心为云计算提供了大规模资源。为了实现基础设施服务的按需分配,需要研究虚拟化技术。虚拟化是IaaS层的重要组成部分,也是云计算的最重要特点。虚拟化技术可以提供以下特点。
1)资源分享。通过虚拟机封装用户各自的运行环境,有效实现多用户分享数据中心资源。
2)资源定制。用户利用虚拟化技术,配置私有的服务器,指定所需的CPU数目、内存容量、磁盘空间,实现资源的按需分配。
3)细粒度资源管理。将物理服务器拆分成若干虚拟机,可以提高服务器的资源利用率,减少浪费,而且有助于服务器的负载均衡和节能。
基于以上特点,虚拟化技术成为实现云计算资源池化和按需服务的基础。为了进一步满足云计算弹性服务和数据中心自治性的需求,需要研究虚拟机快速部署和在线迁移技术。
1)虚拟机快速部署技术
传统的虚拟机部署分为4个阶段:创建虚拟机;安装操作系统与应用程序;配置主机属性(如网络、主机名等):启动虚拟机。该方法部署时间较长,达不到云计一算弹性服务的要求。尽管可以通过修改虚拟机配置(如增减CPU数目、磁盘空间、内存容量)改变单台虚拟机性能,但是更多情况下云计算需要快速扩张虚拟机集群的规模。
为了简化虚拟机的部署过程,虚拟机模板技术。被应用于大多数云计算平台。虚拟机模板预装了操作系统与应用软件,并对虚拟设备进行了预配置,可以有效减少虚拟机的部署时间。然而虚拟机模板技术仍不能满足快速部署的需求:
一方面,将模板转换成虚拟机需要复制模板文件,当模板文件较大时,复制的时间开悄不可忽视;
另一方面,因为应用程序没有加载到内存,所以通过虚拟机模板转换的虚拟机需要在启动或加载内存镜像后,方可提供服务。为此,有学者提出了基于fork思想的虚拟机部署方式。该方式受操作系统的fork原语启发,可以利用父虚拟机迅速克隆出大量子虚拟机。与进程级的fork相似,基于虚拟机级的fork.子虚拟机可以继承父虚拟机的内存状态信息,并在创建后即时可用。当部署大规模虚拟机时,子虚拟机可以并行创建,并维护其独立的内存空间,而不依赖于父虚拟机。为了减少文件的复制开销,虚拟机fork采用了“写时复制”(COW, copy-on-write)技术:子虚拟机在执行“写操作”时,将更新后的文件写入本机磁盘:在执行“读操作”时,通过判断该文件是否已被更新,确定本机磁盘或父虚拟机的磁盘读取文件。在虚拟机fork技术的相关研究工作中,Potemkin项目实现了虚拟机fork技术,并可在1s内完成虚拟机的部署或删除,但要求父虚拟机和子虚拟机在相同的物理机上。Lagar-Cavilla等人研究了分布式环境下的并行虚拟机fork技术[26]该技术可以在1s内完成32台虚拟机的部署。虚拟机fork是一种即时(on-demand )部署技术,虽然提高了部署效率,但通过该技术部署的子虚拟机不能持久化保存。
2)虚拟机在线迁移技术
虚拟机在线迁移是指虚拟机在运行状态下从一台物理机移动到另一台物理机。虚拟机在线迁移技术对云计算平台有效管理具有重要意义。
①提高系统可靠性。一方面,当物理机需要维护时,可以将运行于该物理机的虚拟机转移到其他物理机。另一方面,可利用在线迁移技术完成虚拟机运行时备份,当主虚拟机发生异常时,可将服务无缝切换至备份虚拟机。
②有利于负载均衡。当物理机负载过重时,可以通过虚拟机迁移达到负载均衡,优化数据中心性能。
③有利于设计节能方案。通过集中零散的虚拟机,可使部分物理机完全空闲,以便关闭这些物理机(或使物理机休眠),达到节能目的。
此外,虚拟机的在线迁移对用户透明,云计算平台可以在不影响服务质量的情况下优化和管理数据中心。在线迁移技术于2005年由Clark等人提出,通过迭代的预复制(pre-copy)策略同步迁移前后的虚拟机的状态。传统的虚拟机迁移是在LAN中进行的,为了在数据中心之间完成虚拟机在线迁移,Hirofuchi等人介绍了一种在WAN环境下的迁移方法。这种方法在保证虚拟机数据一致性的前提下,尽可能少地牺牲虚拟机I/O性能,加快迁移速度。利用虚拟机在线迁移技术,Remus系统设计了虚拟机在线备份方法。当原始虚拟机发生错误时,系统可以立即切换到备份虚拟机,而不会影响到关键任务的执行,提高了系统可靠性。
3.1.3典型的IaaS层平台
本节介绍了3种典型的IaaS平台,包括AmazonEC2, Eucalyptus和东南大学云计算平台。
Amazon弹性计算云(EC2,elastic computingcloud)为公众提供基于Xen虚拟机的基础设施服务。Amazon EC2的虚拟机分为标准型、高内存型、高性能型等多种类型,每一种类型的价格各不相同。用户可以根据自身应用的特点与虚拟机价格,定制虚拟机的硬件配置和操作系统。Amazon EC2的计费系统根据用户的使用情况(一般为使用时间)对用户收费。在弹性服务方面,Amazon EC2可以根据用户自定义的弹性规则,扩张或收缩虚拟机集群规模。目前,Amazon EC2已拥有Ericsson, Active.com, Autodesk等大量用户。
Eucalyptus是加州大学圣巴巴拉分校开发的开源IaaS平台。区别于Amazon EC2等商业IaaS平台,Eucalyptus的设计目标是成为研究和发展云计算的基础平台。为了实现这个目标,Eucalyptus的设计强调开源化、模块化,以便研究者对各功能模块升级、改造和更换。目前,Eucalyptus已实现了和Amazon EC2相兼容的API,并部署于全球各地的研究机构。
东南大学云计算平台面向计算密集型和数据密集型应用,由3 500颗CPU内核和SOOTB高速存储设备构成,提供37万亿次浮点计算能力。其基础设施服务不仅支持Xen, KVM, VMware等虚拟化技术,而且支持物理计算节点的快速部署,可根据科研人员的应用需求,为其按需配置物理的或虚拟的私有计算集群,并自动安装操作系统、应用软件。由于部分高性能计算应用对网络延时敏感,其数据中心利用40Gbit/s QDR InfiniBand作为数据传输网络,提供高带宽低延时的网络服务。目前,东南大学云计算平台承担了AMS-02(见第5节)数据分析处理、电磁仿真、分子动力学模拟等科学计算任务。
3.2 PaaS
PaaS层作为3层核心服务的中间层,既为上层应用提供简单、可靠的分布式编程框架,又需要基于底层的资源信息调度作业、管理数据,屏蔽底层系统的复杂性。随着数据密集型应用的普及和数据规模的日益庞大,PaaS层需要具备存储与处理海量数据的能力。本节先介绍PaaS层的海量数据存储与处理技术,然后讨论基于这些技术的资源管理与调度策略。
3.2.1海量数据存储与处理技术
1)海量数据存储技术
云计算环境中的海量数据存储既要考虑存储系统的I/O性能,又要保证文件系统的可靠性与可用性。
Ghemawat等人为Google设计了GFS( googlefile system。根据Google应用的特点,GFS对其应用环境做了6点假设:①系统架设在容易失效的硬件平台上;②需要存储大量GB级甚至TB级的大文件;③文件读操作以大规模的流式读和小规模的随机读构成;④文件具有一次写多次读的特点;⑤系统需要有效处理并发的追加写操作;⑥高持续I/O带宽比低传输延迟重要。
图6展示了GFS的执行流程。在GFS中,一个大文件被划分成若干固定大小(如64MB)的数据块,并分布在计算节点的本地硬盘,为了保证数据可靠性,每一个数据块都保存有多个副本,所有文件和数据块副本的元数据由元数据管理节点管理。GFS的优势在于:①由于文件的分块粒度大,GFS可以存取PB级的超大文件;②通过文件的分布式存储,GFS可并行读取文件,提供高I/O吞吐率;③鉴于上述假设4,GFS可以简化数据块副本间的数据同步问题;④文件块副本策略保证了文件可靠性。
Bigtable是基于GFS开发的分布式存储系统,它将提高系统的适用性、可扩展性、可用性和存储性能作为设计目标。Bigtable的功能与分布式数据库类似,用以存储结构化或半结构化数据,为Google应用(如搜索引擎、Google Earth等)提供数据存储与查询服务。在数据管理方面,Bigtable将一整张数据表拆分成许多存储于GFS的子表,并由分布式锁服务Chubby负责数据一致性管理。在数据模型方面,Bigtable以行名、列名、时间戳建立索引,表中的数据项由无结构的字节数组表示。这种灵活的数据模型保证Bigtable适用于多种不同应用环境。图7展示了如何在Bigtable中存储网页,其中t1~t5为时间戮。
由于Bigtable需要管理节点集中管理元数据,所以存在性能瓶颈和单点失效问题。为此,DeCandia等人设计了基于P2P结构的Dynamo存储系统,并应用于Amazon的数据存储平台。借助于P2P技术的特点,Dynamo允许使用者根据工作负载动态调整集群规模。另外,在可用性方面,Dynamo采用零跳分布式散列表结构降低操作响应时间;在可靠性方面,Dynamo利用文件副本机制应对节点失效。由于保证副本强一致性会影响系统性能,所以,为了承受每天数千万的并发读写请求,Dynamo中设计了最终一致性模型,弱化副本一致性,保证提高性能。
图6 GFS执行流程
图7 Bigtable的存储方式
云计算:体系架构与关键技术(三)
发表时间:2012-2-21 罗军舟 金嘉晖 宋爱波 东方 来源:万方数据
关键字:云计算 虚拟化 数据中心 海量数据处理 服务质量
信息化调查找茬投稿收藏评论好文推荐打印社区分享
本文系统地分析和总结云计算的研究现状,划分云计算体系架构为核心服务、服务管理、用户访问接口等3个层次。围绕低成本、高可靠、高可用、规模可伸缩等研究目标,深入全面地介绍了云计算的关键技术及最新研究进展。在云计算基础设施方面,介绍了云计算数据中心设计与管理及资源虚拟化技术:在大规模数据处理方面,分析了海量数据处理平台及其资源管理与调度技术;在云计算服务保障方面,讨论了服务质量保证和安全与隐私保护技术。针对新型的云计算应用和云计算存在的局限性,又探讨并展望了今后的研究方向。最后,介绍了东南大学云计算平台以及云计算研究与应用方面的相关成果。
图8 MapReduce的执行过程
2)数据处理技术与编程模型
PaaS平台不仅要实现海量数据的存储,而且要提供面向海量数据的分析处理功能。由于PaaS平台部署于大规模硬件资源上,所以海量数据的分析处理需要抽象处理过程,并要求其编程模型支持规模扩展,屏蔽底层细节并且简单有效。
MapReduce是Google提出的并行程序编程模型,运行于GFS之上。如图8所示,一个MapReduce作业由大量Map和Reduce任务组成,根据两类任务的特点,可以把数据处理过程划分成Map和Reduce 2个阶段:在Map阶段,Map任务读取输入文件块,并行分析处理,处理后的中间结果保存在Map任务执行节点:在Reduce阶段,Reduce任务读取并合并多个Map任务的中间结果。MapReduce可以简化大规模数据处理的难度:首先,MapReduce中的数据同步发生在Reduce读取Map中间结果的阶段,这个过程由编程框架自动控制,从而简化数据同步问题;其次,由于MapReduce会监测任务执行状态,重新执行异常状态任务,所以程序员不需考虑任务失败问题;再次,Map任务和Reduce任务都可以并发执行,通过增加计算节点数量便可加快处理速度:最后,在处理大规模数据时,Map/Reduce任务的数目远多于计算节点的数目有助于计算节点负载均衡。
虽然MapReduce具有诸多优点,但仍具有局限性:①MapReduce灵活性低,很多问题难以抽象成Map和Reduce操作;② MapReduce在实现迭代算法时效率较低:③ MapReduce在执行多数据集的交运算时效率不高。为此,Sawzall语言和Pig语言封装了MapReduce,可以自动完成数据查询操作到MapReduce的映射;Ekanayake等人设计了Twister平台,使MapReduce有效支持迭代操作:Yang等人设计了Map-Reduce-Merge框架,通过加入Merge阶段实现多数据集的交操作。在此基础上,Wang等人将Map-Reduce-Merge框架应用于构建OLAP数据立方体:文献将MapRedcue应用到并行求解大规模组合优化问题(如并行遗传算法)。
由于许多问题难以抽象成MapReduce模型,为了使并行编程框架灵活普适,Isard等人设计Dryad框架。Dryad采用了基于有向无环图(DAGdirected acyclic graph)的并行模型(如图9所示)。在Dryad中,每一个数据处理作业都由DAG表示,图中的每一个节点表示需要执行的子任务,节点之间的边表示2个子任务之间的通信。Dryad可以直观地表示出作业内的数据流。基于DAG优化技术,Dryad可以更加简单高效地处理复杂流程。同MapReduce相似,Dryad为程序开发者屏蔽T底层的复杂性,并可在计算节点规模扩展时提高处理性能。在此基础上,Yu等人设计了DryadLINQ数据查询语言,该语言和.NET平台无缝结合,并利用Dryad模型对Azure平台上的数据进行查询处理。
图9 Dryad的任务模型
3.2.2资源管理与调度技术
海量数据处理平台的大规模性给资源管理与调度带来挑战。研究有效的资源管理与调度技术可以提高MapReduce, Dryad等PaaS层海量数据处理平台的性能。
1)副本管理技术
副本机制是PaaS层保证数据可靠性的基础,有效的副本策略不但可以降低数据丢失的风险,而且能优化作业完成时间。目前,Hadoop(见3.2.3节)采用了机架敏感的副本放置策略。该策略默认文件系统部署于传统网络拓扑的数据中心。以放置3个文件副本为例,由于同一机架的计算节点间网络带宽高,所以机架敏感的副本放置策略将2个文件副本置于同一机架,另一个置于不同机架。这样的策略既考虑了计算节点和机架失效的情况,也减少了因为数据一致性维护带来的网络传输开销。除此之外,文件副本放置还与应用有关,Eltabakh等人提出了一种灵活的数据放置策略CoHadoop,用户可以根据应用需求自定义文件块的存放位置,使需要协同处理的数据分布在相同的节点上,从而在一定程度上减少了节点之间的数据传输开销。但是,目前PaaS层的副本调度大多局限于单数据中心,从容灾备份和负载均衡角度,需要考虑面向多数据中心的副本管理策略。郑湃等人提出了三阶段数据布局策略,分别针对跨数据中心数据传输、数据依赖关系和全局负载均衡3个目标对数据布局方案进行求解和优化。虽然该研究对多数据中心间的数据管理起到优化作用,但是未深入讨论副本管理策略。因此,需在多数据中心环境下研究副本放置、副本选择及一致性维护和更新机制。
2)任务调度算法
PaaS层的海量数据处理以数据密集型作业为主,其执行性能受到I/O带宽的影响。但是,网络带宽是计算集群(计算集群既包括数据中心中物理计算节点集群,也包括虚拟机构建的集群)中的急缺的资源:①云计算数据中心考虑成本因素,很少采用高带宽的网络设备;②IaaS层部署的虚拟机集群共享有限的网络带宽;③海量数据的读写操作占用了大量带宽资源。因此PaaS层海量数据处理平台的任务调度需要考虑网络带宽因素。
为了减少任务执行过程中的网络传输开销,可以将任务调度到输入数据所在的计算节点,因此,需要研究面向数据本地性(data-locality)的任务调度算法。Hadoop以“尽力而为”的策略保证数据本地性。虽然该算法易于实现,但是没有做到全局优化,在实际环境中不能保证较高的数据本地性。为了达到全局优化,Fischer等人为MapReduce任务调度建立数学模型,并提出了HTA(Hadoop taskassignment)问题。该问题为一个变形的二部图匹配(如图10所示),目标是将任务分配到计算节点,并使各计算节点负载均衡,其中si,tj分别表示计算节点和任务,实边表示si有tj的输入数据,虚边表示si没有tj的输入数据,wt和wr分别表示调度开销。该研究利用3-SAI,问题证明了HTA问题是NP完全的,并设计了MaxCover-BalAssign算法解决该问题。虽然MaxCover-BalAssign算法的理论上限接近最优解,但是时间复杂度过高,难以应用在大规模环境中。为此,Jin等人设计了BAR调度算法,基于“先均匀分配再均衡负载”的思想,BAR算法在快速求解大规模HTA问题同时,得到优于MaxCover-BalAssign算法的调度结果。
图10 HTA问题模型
除了保证数据本地性,PaaS层的作业调度器还需要考虑作业之间的公平调度。PaaS层的工作负载中既包括子任务少、执行时间短、对响应时间敏感的即时作业(如数据查询作业),也包括子任务多、执行时间长的长期作业(如数据分析作业)。研究公平调度算法可以及时为即时作业分配资源,使其快速响应。因为数据本地性和作业公平性不能同时满足,所以Zaharia等人在Max-Min公平调度算法的基础上设计了延迟调度(delay scheduling)算法该算法通过推迟调度一部分作业并使这些作业等待合适的计算节点,以达到较高的数据本地性。但是在等待开销较大的情况下,延迟策略会影响作业完成时间。为了折衷数据本地性和作业公平性,Isard等设计了基于最小代价流的调度模型fuel,并应用于Microsoft的Azure平台。如图11所示,wij表示作业i的子任务j,wij和C, R, X, U的边分别表示任务被调度到计算节点、机架、数据中心和不被调度,每条边带有权值,并需要根据集群状态实时更新权值。当系统状态发生改变时(如有计算节点空闲、有新任务加入),调度器对调度图求解最小代价流,并做出调度决策。虽然该方法可以得到全局优化的调度结果,但是求解最小代价流会带来计算开销,当图的规模很大时,计算开销将严重影响系统性能。
图11 Quiacy的调度模型
3)任务容错机制
为了使PaaS平台可以在任务发生异常时自动从异常状态恢复,需要研究任务容错机制。MapReduce的容错机制在检测到异常任务时,会启动该任务的备份任务。备份任务和原任务同时进行,当其中一个任务顺利完成时,调度器立即结束另一个任务。Hadoop的任务调度器实现了备份任务调度策略。但是现有的Hadoop调度器检测异常任务的算法存在较大缺陷:如果一个任务的进度落后于同类型任务进度的20%. Hadoop则把该任务当做异常任务,然而,当集群异构时,任务之间的执行进度差异较大,因而在异构集群中很容易产生大量的备份任务。为此,Zaharia等人研究了异构环境下异常任务的发现机制,并设计了LATE(longest approximate time to end)调度器。通过估算Map任务的完成时间,LATE为估计完成时间最晚的任务产生备份。虽然LATE可以有效避免产生过多的备份任务,但是该方法假设Map任务处理速度是稳定的,所以在Map任务执行速度变化的情况下(如先快后慢),LATE便不能达到理想的性能。
3.2.3典型的PaaS平台
本节介绍了3种典型的PaaS平台:Google AppEngine, Hadoop和Microsoft Azure。这些平台都基于海量数据处理技术搭建,且各具代表性。图12比较了上述PaaS平台所采用的关键技术。
Google App Engine是基于Google数据中心的开发、托管Web应用程序的平台。通过该平台,程序开发者可以构建规模可扩展的Web应用程序,而不用考虑底硬件基础设施的管理。App Engine由GFS管理数据、MapReduce处理数据,并用Sawzall为编程语言提供接口。
图12典型PaaS平台的比较
Hadoop是开源的分布式处理平台,其HDFS, Hadoop MapReduce和Pig模块实现TGFS, MapReduce和Sawzall等数据处理技术。与Google的分布式处理平台相似,Hadoop在可扩展性、可靠性、可用性方面做了优化,使其适用于大规模的云环境。目前,Hadoop由Apache基金会维护,Yahoo!, Facebook、淘宝等公司利用Hadoop构建数据处理平台,以满足海量数据分析处理需求。
Microsoft Azure以Dryad作为数据处理引擎,允许用户在Microsoft的数据中心上构建、管理、扩展应用程序。目前,Azure支持按需付费,并免费提供750h的计算时长和1GB数据库空间,其服务范围已经遍布41个国家和地区。
3.3 SaaS
SaaS层面向的是云计算终端用户,提供基于互联网的软件应用服务。随着Web服务、HTMLS ,Ajax, Mashup等技术的成熟与标准化,SaaS应用近年来发展迅速。
典型的SaaS应用包括Google Apps, SalesforceCRM等。
Google Apps包括Google Docs, GMail等一系列SaaS应用。Google将传统的桌面应用程序(如文字处理软件、电子邮件服务等)迁移到互联网,并托管这些应用程序。用户通过Web浏览器便可随时随地访问Google Apps,而不需要下载、安装或维护任何硬件或软件。Google Apps为每个应用提供了编程接口,使各应用之间可以随意组合。Google Apps的用户既可以是个人用户也可以是服务提供商。比如企业可向Google申请域名为@example.com的邮件服务,满足企业内部收发电子邮件的需求。在此期间,企业只需对资源使用量付费,而不必考虑购置、维护邮件服务器、邮件管理系统的开销。
Salesforce CRM部署于Force.com云计算平台,为企业提供客户关系管理服务,包括销售云、服务云、数据云等部分。通过租用CRM的服务,企业可以拥有完整的企业管理系统,用以管理内部员工、生产销售、客户业务等。利用CRM预定义的服务组件,企业可以根据自身业务的特点定制工作流程。基于数据隔离模型,CRM可以隔离不同企业的数据,为每个企业分别提供一份应用程序的副本。CRM可根据企业的业务量为企业弹性分配资源。除此之外,CRM为移动智能终端开发了应用程序,支持各种类型的客户端设备访问该服务,实现泛在接入。
3.4服务管理层
为了使云计算核心服务高效、安全地运行,需要服务管理技术加以支持。服务管理技术包括QoS保证机制、安全与隐私保护技术、资源监控技术、服务计费模型等。其中,QoS保证机制和安全与隐私保护技术是保证云计算可靠性、可用性、安全性的基础。为此,本节着重介绍QoS保证机制和安全与隐私保护技术的研究现状。
3.4.1 QoS保证机制
云计算不仅要为用户提供满足应用功能需求的资源和服务,同时还需要提供优质的QoS(如可用性、可靠性、可扩展、性能等),以保证应用顺利高效地执行。这是云计算得以被广泛采纳的基础。图13给出了云计算中QoS保证机制,首先,用户从自身应用的业务逻辑层面提出相应的QoS需求;为了能够在使用相应服务的过程中始终满足用户的需求,云计算服务提供商需要对QoS水平进行匹配并且与用户协商制定服务水平协议;最后,根据SLA内容进行资源分配以达到QoS保证的目的。针对以上3个步骤,本节依次介绍IaaS、PaaS和SaaS中的QoS保证机制。
图13 QoS保证机制
1) IaaS层的QoS保证机制
IaaS层可看作是一个资源池,其中包括可定制的计算、网络、存储等资源,并根据用户需求按需提供相应的服务能力。文献指出,IaaS层所关心QoS参数主要可分为两类:一类是云计算服务提供者所提供的系统最小服务质量,如服务器可用性及网络性能等:另一类服务提供者承诺的服务响应时间。
为了能够在服务运行过程中有效保证其性能,IaaS层用户需要针对QoS参数同云计算服务提供商签订相应的SLA。根据应用类型不同可分为两类:确定性SLA (deterministic SLA)以及可能性SLA(probabilistic SLA)。其中确定性SLA主要针对关键性核心服务,这类服务通常需要十分严格的性能保证(如银行核心业务等),因此需要100%确保其相应的QoS需求。对于可能性SLA,其通常采用可用性百分比表示(如保证硬件每月99.95%的时间正常运行),这类服务通常并不需要十分严格的QoS保证,主要适用于中小型商业模式及企业级应用。在签订完SLA后,若服务提供商未按照SLA进行QoS保障时,则对服务提供商启动惩罚机制(如赔款),以补偿对用户造成的损失。
在实际系统方面,近年来出现了若干通过SLA技术实现IaaS层QoS保证机制的商用云计算系统或平台,主要包括Amazon EC2 , GoGrid、Rackspace等,其QoS参数如表2所示。
2) PaaS/SaaS层的QoS保证机制
在云计算环境中,PaaS层主要负责提供云计算应用程序(服务)的运行环境及资源管理。SaaS提供以服务为形式的应用程序。与IaaS层的QoS保证机制相似,PaaS层和SaaS层的QoS保证也需要经历3个阶段,典型的QoS参数如表3所示。PaaS层和SaaS层QoS保证的难点在第3阶段(资源分配阶段)。由于在云计算环境中,应用服务提供商同底层硬件服务提供商之间可以是松耦合的,所以PaaS层和SaaS层在第3阶段需要综合考虑IaaS层的费用、IaaS层承诺的QoS, PaaS/SaaS层服务对用户承诺的QoS等。
云计算:体系架构与关键技术(四)
发表时间:2012-2-22 罗军舟 金嘉晖 宋爱波 东方 来源:万方数据
关键字:云计算 虚拟化 数据中心 海量数据处理 服务质量
信息化调查找茬投稿收藏评论好文推荐打印社区分享
本文系统地分析和总结云计算的研究现状,划分云计算体系架构为核心服务、服务管理、用户访问接口等3个层次。围绕低成本、高可靠、高可用、规模可伸缩等研究目标,深入全面地介绍了云计算的关键技术及最新研究进展。在云计算基础设施方面,介绍了云计算数据中心设计与管理及资源虚拟化技术:在大规模数据处理方面,分析了海量数据处理平台及其资源管理与调度技术;在云计算服务保障方面,讨论了服务质量保证和安全与隐私保护技术。针对新型的云计算应用和云计算存在的局限性,又探讨并展望了今后的研究方向。最后,介绍了东南大学云计算平台以及云计
为此,本节介绍PaaS层和SaaS层的资源分配策略。为了便于讨论,本节中PaaS层和SaaS层统称为应用服务层。弹性服务是云计算的特性之一,为了保证服务的可用性,应用服务层需要根据业务负载动态申请或释放IaaS层的资源,Calheiros等基于排队论设计了负载预测模型,通过比较硬件设施工作负载、用户请求负载及QoS目标,调整虚拟机的数量。由于同类IaaS层服务可能由多个服务提供商提供,应用服务提供商需要根据QoS协定选择合适的IaaS层服务。为此,Xiao等人设计了基于信誉的QOS部署机制,该机制综合考虑IaaS层服务层提供商的信誉、应用服务同用户的SLA以及QoS的部署开销,选择合适的IaaS层服务。除此之外,由于Amazon EC2的Spot Instance服务可以以竞价方式提供廉价的虚拟机,Andrzejak等人为应用服务层设计了的竞价模型,使其在满足用户QoS需求的前提下降低硬件设施开销。
表2 IaaS层的QoS参数定义
表3 PaaS/SaaS层的QoS参数定义
3.4.2安全与隐私保护
虽然通过QoS保证机制可以提高云计算的可靠性和可用性,但是目前实现高安全性的云计算环境仍面临诸多挑战。一方面,云平台上的应用程序(或服务)同底层硬件环境间是松祸合的,没有固定不变的安全边界,大大增加了数据安全与隐私保护的难度。另一方面,云计算环境中的数据量十分巨大(通常都是TB甚至PB级),传统安全机制在可扩展性及性能方面难以有效满足需求。随着云计算的安全问题日益突出,近年来研究者针对云计算的模型和应用,讨论了云计算安全隐患,研究了云计算环境下的数据安全与隐私保护技术。本节结合云计算核心服务的层次模型,介绍云计算环境下的数据安全与隐私保护技术的研究现状。
1) IaaS层的安全
虚拟化是云计算IaaS层普遍采用的技术。该技术不仅可以实现资源可定制,而且能有效隔离用户的资源。Santhanam等人讨论了分布式环境下基于虚拟机技术实现的“沙盒”模型,以隔离用户执行环境。然而虚拟化平台并不是完美的,仍然存在安全漏洞。基于AmazonEC2上的实验,Ristenpart等人发现Xen虚拟化平台存在被旁路攻击的危险。他们在云计算中心放置若干台虚拟机,当检测到有一台虚拟机和目标虚拟机放置在同一台主机上时,便可通过操纵自己放置的虚拟机对目标虚拟机的进行旁路攻击,得到目标虚拟机的更多信息。为了避免基于Cache缓存的旁路攻击,Raj等人提出了Cache层次敏感的内核分配方法和基于页染色的Cache划分2种资源管理方法,以实现性能与安全隔离。
2) PaaS层的安全
PaaS层的海量数据存储和处理需要防止隐私泄露问题。Roy等人提出了一种基于MapReduce平台的隐私保护系统Airavat,集成强访问控制和区分隐私,为处理关键数据提供安全和隐私保护。在加密数据的文本搜索方面,传统的方法需要对关键词进行完全匹配,但是云计算数据量非常大,在用户频繁访问的情况下,精确匹配返回的结果会非常少,使得系统的可用性大幅降低,Li等人提出了基于模糊关键词的搜索方法,在精确匹配失败后,还将采取与关键词近似语义的关键词集的匹配,达到在隐私保护的前提下为用户检索更多匹配文件的效果。
3) SaaS层的安全
SaaS层提供了基于互联网的应用程序服务,并会保存敏感数据(如企业商业信息)。因为云服务器由许多用户共享,且云服务器和用户不在同一个信任域里,所以需要对敏感数据建立访问控制机制。由于传统的加密控制方式需要花费很大的计算开销,而且密钥发布和细粒度的访问控制都不适合大规模的数据管理,Yu等人讨论了基于文件属性的访问控制策略,在不泄露数据内容的前提下将与访问控制相关的复杂计算工作交给不可信的云服务器完成,从而达到访问控制的目的。
从以上研究可以看出,云计算面临的核心安全问题是用户不再对数据和环境拥有完全的控制权。为了解决该问题,云计算的部署模式被分为公有云、私有云和混合云。
公有云是以按需付费方式向公众提供的云计算服务(如Amazon EC2, Salesforce CRM等)。虽然公有云提供了便利的服务方式,但是由于用户数据保存在服务提供商,存在用户隐私泄露、数据安全得不到保证等问题。
私有云是一个企业或组织内部构建的云计算系统。部署私有云需要企业新建私有的数据中心或改造原有数据中心。由于服务提供商和用户同属于一个信任域,所以数据隐私可以得到保护。受其数据中心规模的限制,私有云在服务弹性方面与公有云相比较差。
混合云结合了公有云和私有云的特点:用户的关键数据存放在私有云,以保护数据隐私;当私有云工作负载过重时,可临时购买公有云资源,以保证服务质量。部署混合云需要公有云和私有云具有统一的接口标准,以保证服务无缝迁移。
此外,工业界对云计算的安全问题非常重视,并为云计算服务和平台开发了若干安全机制其中Sun公司发布开源的云计算安全工具可为Amazon EC2提供安全保护。微软公司发布基于云计算平台Azure的安全方案,以解决虚拟化及底层硬件环境中的安全性问题。另外,Yahoo!为Hadoop集成了Kerberos验证,Kerberos验证有助于数据隔离,使对敏感数据的访问与操作更为安全。
4云计算的机遇与挑战
云计算的研究领域广泛,并且与实际生产应用紧密结合。纵观己有的研究成果,还可从以下2个角度对云计算做深入研究:①拓展云计算的外沿,将云计算与相关应用领域相结合,本节以移动互联网和科学计算为例,分析新的云计算应用模式及尚需解决的问题;②挖掘云计算的内涵,讨论云计算模型的局限性,本节以端到云的海量数据传输和大规模程序调试诊断为例,阐释云计算的面临的挑战。
1)云计算和移动互联网的结合
云计算和移动互联网的联系紧密,移动互联网的发展丰富了云计算的外沿。由于移动设备的在硬件配置和接入方式上具有特殊性,所以有许多问题值得研究。首先,移动设备的资源是有限的。访问基于Web门户的云计算服务往往需要在浏览器端解释执行脚本程序(如JavaScript, Ajax等),因此会消耗移动设备的计算资源和能源。虽然为移动设备定制客户端可以减少移动设备的资源消耗,但是移动设备运行平台种类多,更新快,导致定制客户端的成本相对较高。因此需要为云计算设计交互性强、计算量小、普适性强的访问接口。其次是网络接入问题。对于许多SaaS层服务来说,用户对响应时间敏感。但是,移动网络的时延比固定网络高,而且容易丢失连接,导致SaaS层服务可用性降低。因此,需要针对移动终端的网络特性对SaaS层服务进行优化。
2)云计算与科学计算的结合
科学计算领域希望以经济的方式求解科学问题,云计算可以为科学计算提供低成本的计算能力和存储能力。但是,在云计算平台上进行科学计算面临着效率低的问题。虽然一些服务提供商推出了面向科学计算的IaaS层服务,但是其性能和传统的高性能计算机相比仍有差距。研究面向科学计算的云计算平台首先要从IaaS层入手。IaaS层的I/O性能成为影响执行时间的重要因素:①网络时延问题,MPI并行程序对网络时延比较敏感,传统高性能计算集群采用InfiniBand网络降低传输时延,但是目前虚拟机对InfiniBand的支持不够,不能满足低时延需求;② I/O带宽问题,虚拟机之间需要竞争磁盘和网络I/O带宽,对于数据密集型科学计算应用,I/O带宽的减少会延长执行时间。其次要在PaaS层研究面向科学计算的编程模型。虽然Moretti等提出了面向数据密集型科学计算的All-Pairs编程模型,但是该模型的原型系统只运行于小规模集群,并不能保证其可扩展性。最后,对于复杂的科学工作流,要研究如何根据执行状态与任务需求动态申请和释放云计算资源,优化执行成本。
3)端到云的海量数据传输
云计算将海量数据在数据中心进行集中存放,对数据密集型计算应用提供强有力的支持。目前许多数据密集型计算应用需要在端到云之间进行大数据量的传输,如AMS-02实验每年将产生约170TB的数据量,需要将这些数据传输到云数据中心存储和处理,并将处理后的数据分发到各地研究中心进行下一步的分析。若每年完成170TB的数据传输,至少需要40Mbids的网络带宽,但是这样高的带宽需求很难在当前的互联网中得到满足。另外,按照Amazon云存储服务的定价,若每年传输上述数据量,则需花费约数万美元,其中并不包括支付给互联网服务提供商的费用。由此可见,端到云的海量数据传输将耗费大量的时间和经济开销。由于网络性价比的增长速度远远落后于云计算技术的发展速度,目前传输主要通过邮寄方式将存储数据的磁盘直接放入云数据中心,这种方法仍然需要相当的经济开销,并且运输过程容易导致磁盘损坏。为了支持更加高效快捷的端到云的海量数据传输,需要从基础设施层入手研究下一代网络体系结构,改变网络的组织方式和运行模式,提高网络吞吐量。
4)大规模应用的部署与调试
云计算采用虚拟化技术在物理设备和具体应用之间加入了一层抽象,这要求原有基于底层物理系统的应用必须根据虚拟化做相应的调整才能部署到云计算环境中,从而降低了系统的透明性和应用对底层系统的可控性。另外,云计算利用虚拟技术能够根据应用需求的变化弹性地调整系统规模,降低运行成本。因此,对于分布式应用,开发者必须考虑如何根据负载情况动态分配和回收资源。但该过程很容易产生错误,如资源泄漏、死锁等。上述情况给大规模应用在云计算环境中的部署带来了巨大挑战。为解决这一问题,需要研究适应云计算环境的调试与诊断开发工具以及新的应用开发模型。
5东南大学云计算平台
近年来,东南大学在云计算领域进行了许多有效的尝试,也获得了较为丰硕的研究与应用成果。东南大学云计算平台的一个典型应用是AMS-02(alpha magnetic spectrometer 02)海量数据处理。
AMS-02实验是由诺贝尔物理学奖获得者丁肇中教授领导的由美、俄、德、法、中等巧个国家和地区共800多名科学家参加的大型国际合作项目,其目的是为寻找由反物质所组成的宇宙和暗物质的来源以及测量宇宙线的来源。AMS-02探测器于2011年5月16日搭乘美国奋进号航天飞机升空至国际空间站,将在国际空间站上运行10~18年,其间大量的原始数据将传送到分别设立在瑞士CERN和中国东南大学的地面数据处理中心SOC(scientific operation center),由地面数据处理中心对其进行传输、存储、处理、计算和分析。
东南大学在针对AMS-02海量数据处理的前期理论工作主要集中于网格环境下的自适应任务调度、分布式资源发现以及副本管理等方面。然而随着AM S-02探测器的升空和运行,AMS-02实验对实际处理平台提出了更高的要求:首先,AMS-02实验相关的数据文件规模急剧增加,需要更大规模、更加高效的数据处理平台的支持;其次,该平台需要提供数据访问服务,以满足世界各地的科学家分析海量科学数据的需求。
为了满足AMS-02海量数据处理应用的需求,东南大学构建了相应的云计算平台。如图14所示,该平台提供了IaaS, PaaS和SaaS层的服务,IaaS层的基础设施由3 500颗CPU内核和容量为SOOTB的磁盘阵列构成,提供虚拟机和物理机的按需分配(见3.1.3节)。在PaaS层,数据分析处理平台和应用开发环境为大规模数据分析处理应用提供编程接口。在SaaS层,以服务的形式部署云计算应用程序,便于用户访问与使用。
对于AMS-02海量数据处理应用,东南大学云计算平台提供了如下支持。
首先,云计算平台可根据AMS-02实验的需求,为其分配独占的计算集群,并自动配置运行环境(如操作系统、科学计算函数库等)。利用资源隔离技术,既保证AMS-02应用不会受到其他应用的影响,又为AMS-02海量数据处理应用中执行程序的更新和调试带来便利。
图14东南大学云计算平台的架构
其次,世界各国物理学家可通过访问部署于SaaS层的AMS-02应用服务,得到所需的原始科学数据和处理分析结果,以充分实现数据共享和协同工作。
最后,随着AMS-02实验的不断进行,待处理的数据量及数据处理的难度会大幅增加。此时相应的云计算应用开发环境将为AMS-02数据分析处理程序提供编程接口,在提供大规模计算和数据存储能力的同时,简化了海量数据处理的难度。
除了AMS-02实验之外,东南大学云计算平台针对不同学科院系的应用需求,还分别部署了电磁仿真、分子动力学模拟等科学计算应用。由于这些科学计算应用对计算平台的性能要求较高,因此为了优化云计算平台的运行性能,同时也进行了大量理论研究工作。
针对海量数据处理应用中数据副本的选择问题,在综合考虑副本开销及数据可用性因素的基础上提出一种基于QoS偏好感知的副本选择策略,通过实现灵活可靠的副本管理机制以提高应用的数据访问效率。
针对大规模数据密集型任务的调度问题,提出了一个低开销的全局优化调度算法BAR。BAR能够根据集群的网络与工作负载动态调整数据本地性,采用网络流思想,并结合负载均衡策略,以获得最小化的作业完成时间,为AMS-02等相关数据密集型任务的高效调度与执行提供了保证。
除了针对科学计算应用之外,东南大学在现有云计算平台的基础上,针对云计算环境中的若干共性问题也进行了相应的研究。
在IaaS层,部署了开源云计算系统OpenQRM基于该系统,研究虚拟机的放置、部署与迁移机制,完善其资源监控策略,使云计算平台可以快速感知资源工作负载的变化,从而提供弹性服务。此外,基于经济模型,探讨了云计算数据中心的资源管理、能耗及服务定价之间的关系。
在PaaS层,深入分析了Hadoop平台上的资源管理与调度机制,对多数据中心间的副本管理策略进行了研究。在此基础上,利用云计算在海量数据存储与处理方面的优势,将云计算应用于OLAP聚集计算和大规模组合优化问题的求解。
在SaaS层,针对移动社会网络中位置信任安全问题,开发设计了基于云计算的位置信任验证服务系统。该系统分为智能手机客户端和云计算平台端两部分。其中,在智能手机客户端,系统提取用户位置属性,并使用蓝牙无线传播技术进行位置信任凭证收集:在云计算平台上,基于凭证收集和验证算法,系统利用云计算弹性服务的特点来满足大规模用户的验证需求。
基于以上研究成果,东南大学今后还将在云计算数据中心的网络优化、云计算服务的安全隐私保护等方面开展深入研究,并进一步构建面向科学计算与应用的云计算平台。
6结束语
云计算作为一种新兴的信息技术发展迅速。通过总结最近几年在该领域的应用与研究成果,将云计算体系架构划分为3个层次。综述了体系架构中主要关键技术的研究现状,包括数据中心设计与管理、虚拟化、海量数据存储与处理、资源管理与调度、服务质量保证和安全与隐私保护等。同时,介绍了东南大学的云计算平台及相关研究成果。总体来说,云计算的研究正处于发展阶段,从拓展云计算应用模式,解决内在的局限性等角度出发,围绕可用性、可靠性、规模弹性、成本能耗等因素,仍有大量关键问题需要深入研究。