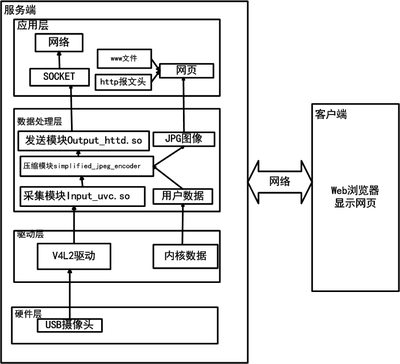
输入文件:hdfs://server1:9000/user/admin/in/yellow.txt
1.splits
formatMinSplitSize:1;
minSplitSize=conf("mapred.min.split.size"):1;
minSize=Math.max(formatMinSplitSize, minSplitSize)=1;
maxSize=conf("mapred.max.split.size"):Long.MAX_VALUE;
fileLength=201000000;
blkLocations=[{0,67108864,server3,server2},
{67108864,67108864,server2,server3},
{134217728,66782272,server2,server3}];
blockSize=67108864;
splitSize=Math.max(minSize, Math.min(maxSize,blockSize)): 67108864;
SPLIT_SLOP=1.1;
splits生成代码:
longbytesRemaining= length;
while(((double)bytesRemaining)/splitSize >SPLIT_SLOP){
intblkIndex =getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(newFileSplit(path,length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts()));
bytesRemaining -= splitSize;
}
if(bytesRemaining != 0){
splits.add(newFileSplit(path,length-bytesRemaining, bytesRemaining,
blkLocations[blkLocations.length-1].getHosts()));
}
splits内容:
FileSplit={file=hdfs://server1:9000/user/admin/in/yellow.txt,hosts=[server3, server2],length=67108864,start=0}
FileSplit={file=hdfs://server1:9000/user/admin/in/yellow.txt,hosts=[server3, server2],length=67108864,start= 67108864}
FileSplit={file=hdfs://server1:9000/user/admin/in/yellow.txt,hosts=[server3, server2],length= 66782272,start=134217728}
splits写入文件:hdfs://server1:9000/tmp/hadoop-admin/mapred/staging/admin/.staging/job_201404200127_0001/job.split
splits文件头:
out.write(SPLIT_FILE_HEADER);// "SPL".getBytes("UTF-8")=[83, 80,76]
out.writeInt(splitVersion);//1
2.SplitMetaInfo
SplitMetaInfo生成代码:
SplitMetaInfo[] info = newSplitMetaInfo[array.length];
if(array.length!= 0){
SerializationFactory factory = newSerializationFactory(conf);
inti =0;
longoffset =out.size();
for(Tsplit: array) {
intprevCount =out.size();
Text.writeString(out,split.getClass().getName());
Serializer<T>serializer=
factory.getSerializer((Class<T>)split.getClass());
serializer.open(out);
serializer.serialize(split);
intcurrCount =out.size();
String[] locations = split.getLocations();
finalintmax_loc =conf.getInt(MAX_SPLIT_LOCATIONS,10);
if(locations.length> max_loc) {
LOG.warn("Maxblock location exceeded for split: "
+ split+ " splitsize:" +locations.length+
"maxsize: " + max_loc);
locations = Arrays.copyOf(locations, max_loc);
}
info[i++] =
newJobSplit.SplitMetaInfo(
locations, offset,
split.getLength());
offset += currCount - prevCount;
}
}
returninfo;
SplitMetaInfo内容:
JobSplit$SplitMetaInfo={data-size : 67108864,start-offset: 7,locations:[server3, server2]
}
JobSplit$SplitMetaInfo={data-size : 67108864,start-offset: 116,locations:[server3, server2]
}
JobSplit$SplitMetaInfo={data-size : 66782272,start-offset: 225,locations:[server3, server2]
}
SplitMetaInfo写入文件:hdfs://server1:9000/tmp/hadoop-admin/mapred/staging/admin/.staging/job_201404200127_0001/job.splitmetainfo
对比splits和SplitMetaInfo内容:
SplitMetaInfo的data-size即FileSplit的length,
SplitMetaInfo的locations即FileSplit的hosts,
SplitMetaInfo的start-offset意思是splits中某条FileSplit记录的起始地址。
SplitMetaInfo文件头:
out.write(JobSplit.META_SPLIT_FILE_HEADER);// "META-SPL".getBytes("UTF-8")
WritableUtils.writeVInt(out,splitMetaInfoVersion); //同splitVersion
WritableUtils.writeVInt(out,allSplitMetaInfo.length);//
3.splits使用
在Task中,待补充
4.SplitMetaInfo使用
在JobTracker进程中,读取SplitMetaInfo,转化为TaskSplitMetaInfo:
TaskSplitMetaInfo[0]={inputDataLength=67108864,locations=[server3,server2], splitIndex=JobSplit$TaskSplitIndex{splitLocation="hdfs://server1:9000/tmp/hadoop-admin/mapred/staging/admin/.staging/job_201404200521_0001/job.split", startOffset=7}
}
TaskSplitMetaInfo[1]={inputDataLength=67108864,locations=[server3,server2], splitIndex=JobSplit$TaskSplitIndex{splitLocation="hdfs://server1:9000/tmp/hadoop-admin/mapred/staging/admin/.staging/job_201404200521_0001/job.split", startOffset=116}
}
TaskSplitMetaInfo[2]={inputDataLength=66782272, locations=[server3,server2], splitIndex=JobSplit$TaskSplitIndex{splitLocation="hdfs://server1:9000/tmp/hadoop-admin/mapred/staging/admin/.staging/job_201404200521_0001/job.split", startOffset=225}
}
然后生成TaskInprogress:
maps=newTaskInProgress[numMapTasks];
for(inti=0; i< numMapTasks;++i) {
inputLength+=splits[i].getInputDataLength();
maps[i]= newTaskInProgress(jobId,jobFile,
splits[i],
jobtracker,conf,this,i, numSlotsPerMap);
}
其中jobFile:hdfs://server1:9000/tmp/hadoop-admin/mapred/staging/admin/.staging/job_201404200521_0001/job.xml
splits[i]为TaskSplitMetaInfo