考虑到很多读者并不清楚该项目的应用场合,因此我依照以前的步骤来组织这篇文章。首先是提出问题,讲述我在怎么一种情况下需要对 HTML 进行语法解析;其次是分析问题,如何考虑到使用 HTML Parser 来达到我所需要的目的;最后就是解决问题。
提出问题
在实际开发一个内容管理项目时,由于内容是基于 HTML 的格式进行存储以及编写,并提供了一个基于浏览器的所见即所得的 HTML 编辑器。用户经常会直接从其他网站上复制一些带格式的内容后直接发布,首页会显示这些内容的概要信息,概要信息直接切割内容,从中读取前几个字。这种做法引发的问题是,截断的内容包含不完整的格式信息,因为切割的长度是固定的,比如我取前 400 个字用于做概要显示,这时候经常把内容中的一些表格切断,这些包含不完整格式信息的内容带来的问题就是它将破坏整个页面的布局,我们碰到最常见的问题就是页面被撑大,从输出的页面源码中可以看出就是因为这些不完整的表格标签导致。
回页首
分析问题
解决我们前面提出的问题的办法唯有使内容的切割更加智能化,可以自动的处理例如表格被切断这个影响格式的罪魁祸首。之前的做法是在切割后的内容中搜索没有被正常结束的表格标签,这解决了大部分内容无法正常显示的问题,但是这仅仅处理了最简单的情况,一旦出现嵌套表格被切割的情况也就无能为力,如果我们再自己来处理嵌套表格的情况,那考虑的问题就非常的多,因为为了使页面的排版美观,网页设计师大量的使用表格来进行处理,事实上这也是编写 HTML 的唯一办法。因此你可能要对各种各样的表格嵌套方式进行单独的处理,想象一下你编写一个万行的代码来完成一个看似简单的问题,你的领导肯定跟你急了 ^_^,问题还在于你这一万行的代码并不一定可以解决问题。因此在这个问题的处理上我们要尽量采取一些成熟稳定的 API,HTML Parser 就是一个用于解析 HTML 文本的开源项目,它可以准确高效的对 HTML 文本中的格式、数据进行处理,有将近二十位来自世界各地的工程师在为这个项目工作。
HTML Parser 项目主要可以用在以下两个方面:
1 .信息提取
文本信息抽取,例如对 HTML 进行有效信息搜索
链接提取,用于自动给页面的链接文本加上链接的标签
资源提取,例如对一些图片、声音的资源的处理
链接检查,用于检查 HTML 中的链接是否有效
页面内容的监控
2 .信息转换
链接重写,用于修改页面中的所有超链接
网页内容拷贝,用于将网页内容保存到本地
内容检验,可以用来过滤网页上一些令人不愉快的字词
HTML 信息清洗,把本来乱七八糟的 HTML 信息格式化
转成 XML 格式数据
HTML Parser 并没有对以上提到的一些应用进行专门的处理,但是它完全可以胜任上面提及的功能,在实际应用中如果遇见上面提及的问题可以使用该项目来处理。
回页首
解决问题
接下来我主要针对我们在前面提过那个网页截断的问题进行处理。我的做法是强行对 HTML 内容进行截断,然后把截断后的内容传递给 HTML Parser,由它来补全缺漏的标签。这样做可能有些内容显示不全,但是至少不会破坏页面的排版。通过这样一个简单的例子可以了解 HTML Parser 的基本结构以及使用流程。
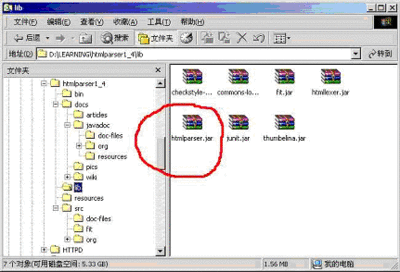
首先从 SourceForge 网站上下载 HTML Parser 的压缩包(下载网址参照文章最后的资料参考部分),下图是解压后的目录结构,其中画红线的是我们所需要的 jar 包文件。把这个文件加到项目的类路径中,其他类可以不管!
/** * 获取 HTML 的预览信息,其中 content 是对象的一个属性,也就是待处理的 HTML 内容 * @return */ public String getPreviewContent(){ // 截取前 N 个字符 String ct = StringUtils.left(content,MAX_COUNT); // 对一些未完成的标签先补齐,避免出现例如 <tab 这样的标签 if(ct!=null&&content!=null) { int idx2 = ct.lastIndexOf('>'); int idx1 = ct.lastIndexOf('<'); if((idx2==-1 && idx1>=0) || idx1 > idx2) { String ct2 = content.substring(ct.length()); int idx3 = ct2.indexOf('>'); if(idx3!=-1 && idx3<(MAX_COUNT2-MAX_COUNT)) { ct += content.substring(ct.length(),ct.length()+idx3+1); } } } // 对于一些页面嵌入了 ActiveX 对象进行预处理 if(ct!=null&&content!=null) { int idx2 = ct.toLowerCase().lastIndexOf("</object>"); int idx1 = ct.toLowerCase().lastIndexOf("<object"); if((idx2==-1 && idx1>=0) || idx1 > idx2) { String ct2 = content.substring(ct.length()).toLowerCase(); int idx3 = ct2.indexOf("</object>"); if(idx3!=-1) ct += content.substring(ct.length(),ct.length()+idx3+9); else ct = ct.substring(0,idx1); } } if(ct!=null&&content!=null) { Parser parser = Parser.createParser(new String(ct.getBytes(),ISO8859_1)); // 中文信息必须转码后方可传入 Node [] tables = parser.extractAllNodesThatAre (TableTag.class); if(tables!=null&&tables.lengtd>0) { TableTag tableTag = (TableTag)tables[0]; ct = ct.substring(0,tableTag.getStartPosition()) + new String(tableTag.toHtml().getBytes(ISO8859_1)); // 处理后的数据转回 GBK 的编码 } } return ct; }
上面这段代码就是用于显示 HTML 概要信息的方法,其中粗体部分是使用 HTML Parser 进行处理的过程。类 Parser 是 HTML Parser 的入口,我们可以将 HTML 文本信息传入给它,或者可以直接传递一个 URL 地址,如下:
Parser parser = new Parser("http://www.javayou.com");
初始化一个 Parser 实例后,紧接着就是对所传入的 HTML 内容进行解析,大家注意红色粗体的那行代码,从方法名我们很容易理解,该方法就是将 HTML 内容中存在的所有的表格给解析出来放到一个数组去,该方法所需的参数就是节点的类型,我们这里用的是表格的标签,几乎 HTML 的标签中都有对应的一个对应的类,比如 FormTag、InputTag、AppletTag 等等,这些标签类都在 org.htmlparser.tags 包中。根据我们要处理不同的标签传入不同的类,这种做法使我们可以很方便的处理其他类型的标签。返回的数组中每个元素都是你传入类的一个实例,通过这个实例可以访问到当前这个标签的起始未知、结束标签的未知以及包含在标签中的文本信息,同时也可以访问其父标签以及所有的子标签等等,同时我们可以通过 toHtml 方法来对标签中包含的 HTML 信息进行清洗,HTML Parser 会自动帮我们把一些没有关闭的标签加上,这样所生成的字符串中就包含着完整的格式控制信息,在页面上显示这样的信息也不会破坏版面布局,达到了我预期的效果。
为了使大家更直观的看到执行效果,我们再来一个小例子并附上执行的结果:
public static void main(String[] args) throws Exception { // 不完整格式的 HTML 信息 String html = "我们是害虫 <table>1234567890<table>lk 你好中国"; Parser parser = Parser.createParser(new String(html.getBytes(),"8859_1")); Node [] tables = parser.extractAllNodesThatAre (TableTag.class); for (int i = 0; i < tables.length; i++) { TableTag tableTag = (TableTag)tables[i]; // 打印出结束标签所在的未知 System.out.println("END POS:"+tableTag.getEndTag().getEndPosition()); // 补齐未结束的标签并打印 System.out.println(new String(tableTag.toHtml().getBytes("8859_1"))); } }
这段代码旨在找出一段不完整 HTML 信息中的所有表格标签,然后打印出经过格式化后的 HTML 信息,下图是在 Eclipse 环境下的执行结果。
为了更好的在实际的业务中应用 HTML Parser 项目,HTML Parser 还提供了几个例子用于处理前面我们提到的功能实现。这些例子在解压目录下的 bin 都有批处理命令可以执行,执行时给命令传入 URL 地址或者是 html 文件的路径即可。
HTML Parser 项目仅仅是提供给我们一个简单而强健的 API 用于分析 HTML 文本信息,更多的应用模式还有待于我们自己去发掘,希望本文能将你引入 HTML Parser 的大门。
参考资料
HTML Parser 项目首页 ????
http://htmlparser.sourceforge.net/
下载地址 ????
http://sourceforge.net/projects/htmlparser
关于作者
刘冬,一直使用 J2EE 从事移动业务方面的开发。现在可以通过 Java 自由人网站 来跟我联系,网址是:
http://www.javayou.com;另外我的邮件地址是
winter.lau@163.com。
为本文评分
平均分 (21个评分)
1 星 1 星
2 星 2 星
3 星 3 星
4 星 4 星
5 星 5 星
评论
添加评论:
请 登录 或 注册 后发表评论。
注意:评论中不支持 HTML 语法
有新评论时提醒我剩余 1000 字符
快来添加第一条评论
回页首