本文介绍的项目,我们基于storm开发了深圳市实时交通路况系统,源码已经在github上开源:
https://github.com/whughchen/RealTimeTraffic
https://github.com/whughchen/realODMatrix欢迎关注 并 fork 加以改进~-----Hadoop分布式计算系统以其强大的计算性能和扩展能力称霸于海量历史数据处理领域,但是它目前还没能对传统的关系型数据系统(RDBMS:如oracle、SQLServer)造成威胁,因为有一个无法逾越的短板:因为它不能实现实时性,不能实现毫秒级响应,一个事物型查询往往需要几十分钟甚至几个小时才出结果。
在HadoopWIKI中也对大数据神器做了客观说明:
Twitter公司的实时分析利器storm的出现,貌似解决了hadoop这一缺陷,它能对过去一个短时间内的海量数据做出分析,得出在过去这一短时间内系统的状态和格局。
笔者有幸在两年前参与过交通分析项目,对分布式实时计算平台Storm还算熟悉,选取其中一个应用“基于Storm深圳市实时路况分析和实时路径推荐系统”做介绍,希望能和对实时流计算感兴趣的同学可以一起探讨。
1.系统功能和亮点
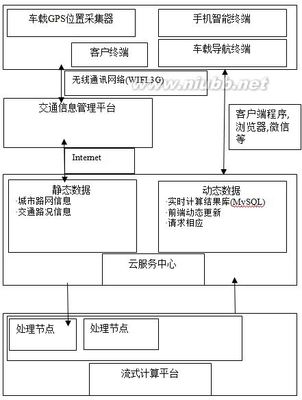
图0: 实时路况分析演示
如本文题目所示,改系统主要实现以下两大功能:
1.能实时计算出深圳市10万多条路段的实时平均速度,进而在地图上用红、黄、绿来代表严重拥堵、轻微拥堵、畅通,实现了交通路况实时播报功能;
2.当系统在响应驾车从一个出发点到达另外一个目的地的最佳导航路径查询时,系统能考虑到当前各个路段的时速,给出一个最短行驶时间的路径而非当前大众的地图厂商给出的最短物理路径,从而实现实时推荐。
与当前主流的百度地图、google地图等主流实时交通分析相比,有以下亮点:
1.数据来源纯净,准确率高。百度地图声称其准确率可达86%,每3分钟更新一次,而本系统更新频率达1分钟每次,经实地勘察准确率比百度高。原因在于百度地图实时路况数据采集于打开了位置服务的手机以及其他移动设备收集位置信息及移动速度信息,通过各种数据加权估算得到某个路段的交通情况,而本系统的数据全部采集于深圳市正在运行的出租车、公家车上的GPS定位仪,没有外来数据源污染我们的数据源。
2.将当前各个路段的平均时速作为考虑权重因子,给出用户一条行驶时间最短的导航路径。而目前的地图导航产品多半用Dijkstra算法来确定一条最短物理路径,而本系统却能考虑到道路的实际拥堵状况。
瞬间觉得该系统高大上了吧,那这个系统后台是如何实现的呢?请使劲往下拖。
2.项目背景
2.1.项目来源
智能交通系统利用大量的多源数据,例如车载GPS数据、深圳通卡刷卡、手机蜂窝位置数据等,实现实时采集、存储、挖掘这些数据背后的信息,从而提高城市交通系统的管理与规划水平。
本项目的数据来源于深圳6万多辆出租车、公交车上安装的GPS定位仪,GPS定位仪每15秒向数据中心发送一条位置信息。每天24小时产生数据量大约3.5亿条,存储空间约300G。如果要采用传统的数据库来处理这些信息肯定是非常困难的,而功能强大的hadoop又无法实现实时分析功能,故本系统最终转而采用实时流处理平台storm。
Storm是twitter公司用于实时处理twitter用户的行为,例如关注、点赞、转发等信息流而开发出的分布式流计算平台,后来将其开源并捐献给了apache基金。
2.2.Storm集群
物理机:6台16核处理器、64GB内存的联想服务器
虚拟化:用openstack将其中5台物理机每台虚拟化为4个4核CPU、16GB内存的虚拟机,从而产生了20个计算节点,目的是为了提高各个节点的资源利用率和集群快速部署;另外一台物理机作为Storm的控制节点nimbus和Stormui 控制台。
集群部署:在一个虚拟机里安装好storm运行环境后,将这个虚拟机的镜像快速复制19份并启动,从而节省了在每个节点都安装一遍storm的人力投入;
软件:storm 0.8, zookeeper 3.4.5,MySQL等.
具体storm集群部署过程可以参考这篇博文:http://blog.sina.com.cn/s/blog_5ca749810101c2dy.html
1:Storm集群组织结构
简略介绍下Storm集群的组织架构:
Storm UI是一个用户可以监控、操作storm任务的控制台,相当于hadoop的jobtracker;
Nimbus:是Storm的控制节点,相当于hadoop的namenode;
Supervisor:是Storm的计算节点,相当于hadoop的namenode。
3.实时计算架构和实现途径
3.1.系统架构
图1:实时交通路况分析系统架构图
实时交通路况的架构可以用这样的图1来简单表示。
其中出租车、公交车上的GPS采集器将数据发送给交通部门的数据中心,数据中心用socket通信将GPS数据发送给服务器,服务器将GPS数据存储一份在云存储器,用于hadoop离线分析,另外一份发给storm平台的spout组件。Storm平台分析完每一条GPS记录后,更新更当前各条道路的平均速度,并将分析结果写Mysql到数据库。前段服务器读取Mysql的数据实现实时展示,并能响应手机等终端的请求,将查询结果通过网页或者微信消息的形式发给用户。
3.2.
2:实时交通路况分析数据流向图
如图2所示,从数据流进入Storm流计算平台到输出到数据库,数据流共经历了4个处理单元:SocketSoupt、MapMatchingBolt、SpeedCalcBolt、DBWritterBolt,其数据流分组的发送方式分别是shufflegrouping, fieldgrouping,field grouping。shufflegrouping的发送方式是随机分发,fieldgrouping的方式是按照消息的key值把这条消息分发到相应的处理单元。下面将一一为你道来各个组件的功能。
图3:实时路况分析数据处理流程图
图3中各组件的功能如下:
S0. 道路编号索引:将深圳市10万多条道路的信息预处理,主要是起点坐标、终点坐标、方向等信息分网格载入内存,以方便Storm程序能快递定位某一条路;
S1. SocketSpout: 接收Socket通讯传来的GPS数据,其中一份存储于HDFS用于历史数据分析,另外一份采用随机的方式将分组发给下一个处理单元MapMatchingBolt;
S2-S4. MapMatchingBolt:读取GPS数据的经纬度根据一定的地图匹配算法将该条GPS信息匹配到某一条道路上,并按照fieldgrouping的方式发送给下一个组件SpeedCalcBolt,地图匹配的算法相当复杂且涉及到专利,此处略去5千字;
S5-S7. SpeedCalcBolt:维护了深圳市十万多条路的平均速度,这里为每一条道路都构建了一个速度值队列,当改队列的速度的时间戳超过一定时间限度时,速度值出队列;
S8. MergeBolt(DBWritterBolt):每分钟计算一次十万多条路每条路的平均速度,输出到数据库MySQL.
3.3.程序主函数
图4:主函数
如图4所示,Storm流计算的四个组件SocketSoupt、MapMatchingBolt、SpeedCalcBolt、DBWritterBolt分别设置了1个、9个、7个、1个执行单元,其数据流分组的发送方式分别是shufflegrouping, fieldgrouping,field grouping,在storm的监控上也看到各个组件的处理延迟也比较小。
3.4.Storm流计算性能监控
图5:Storm UI
图5为Storm流计算监控页面,有点类似于Hadoop的Jobtracker,用于监控在storm平台上的各个实例的计算能力、处理延迟等。从图上可以看出,这个实例大约运行了19秒,处理的消息数是32320条。
3.5.实时路径推荐
如本文第一节中所提,本系统具备实时路径推荐功能,将当前各个路段的平均时速作为考虑权重因子,给出用户一条行驶时间最短的导航路径,而非最短物理路径。
动态时间成本最短路径:通过如下交通路况计算方法得到的实时路况更新道路的通行速度,通过道路的通行速度计算出其时间成本,再将时间成本作为道路的权重进行Dijkstra算法求解最短路径。方法如下:
第一步:输入数据为包含起点和终点的查询、道路路网和交通路况矩阵。其中起点可由GPS数据自动获得,终点由用户输入;
第二步:调用道路权重动态变化的Dijkstra算法计算出空间最短路径;




