2012-07-2714:31:16| 分类: 算法 | 标签:|字号大中小 订阅
1.穷举搜索( Exhaustive search for solution)
给定隐马尔科夫模型,也就是在模型参数(,A,B)已知的情况下,我们想找到观察序列的概率。还是考虑天气这个例子,我们有一个用来描述天气及与它密切相关的海藻湿度状态的隐马尔科夫模型(HMM),另外我们还有一个海藻的湿度状态观察序列。假设连续3天海藻湿度的观察结果是(干燥、湿润、湿透)——而这三天每一天都可能是晴天、多云或下雨,对于观察序列以及隐藏的状态,可以将其视为网格:
网格中的每一列都显示了可能的的天气状态,并且每一列中的每个状态都与相邻列中的每一个状态相连。而其状态间的转移都由状态转移矩阵提供一个概率。在每一列下面都是某个时间点上的观察状态,给定任一个隐藏状态所得到的观察状态的概率由混淆矩阵提供。
可以看出,一种计算观察序列概率的方法是找到每一个可能的隐藏状态,并且将这些隐藏状态下的观察序列概率相加。对于上面那个(天气)例子,将有3^3= 27种不同的天气序列可能性,因此,观察序列的概率是:
Pr(dry,damp,soggy | HMM) = Pr(dry,damp,soggy |sunny,sunny,sunny) + Pr(dry,damp,soggy | sunny,sunny ,cloudy) +Pr(dry,damp,soggy | sunny,sunny ,rainy) + . . . . Pr(dry,damp,soggy| rainy,rainy ,rainy)
用这种方式计算观察序列概率极为昂贵,特别对于大的模型或较长的序列,因此我们可以利用这些概率的时间不变性来减少问题的复杂度。
2.使用递归降低问题复杂度
给定一个隐马尔科夫模型(HMM),我们将考虑递归地计算一个观察序列的概率。我们首先定义局部概率(partialprobability),它是到达网格中的某个中间状态时的概率。然后,我们将介绍如何在t=1和t=n(>1)时计算这些局部概率。
假设一个T-长观察序列是:
2a.局部概率(’s)
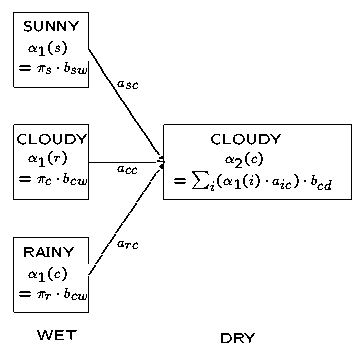
考虑下面这个网格,它显示的是天气状态及对于观察序列干燥,湿润及湿透的一阶状态转移情况:
我们可以将计算到达网格中某个中间状态的概率作为所有到达这个状态的可能路径的概率求和问题。
例如,t=2时位于“多云”状态的局部概率通过如下路径计算得出:
我们定义t时刻位于状态j的局部概率为at(j)——这个局部概率计算如下:
t (j )= Pr( 观察状态 | 隐藏状态j ) x Pr(t时刻所有指向j状态的路径)
对于最后的观察状态,其局部概率包括了通过所有可能的路径到达这些状态的概率——例如,对于上述网格,最终的局部概率通过如下路径计算得出:
由此可见,对于这些最终局部概率求和等价于对于网格中所有可能的路径概率求和,也就求出了给定隐马尔科夫模型(HMM)后的观察序列概率。
第3节给出了一个计算这些概率的动态示例
计算观察序列的概率(Finding the probability of an observed sequence)
2b.计算t=1时的局部概率’s
我们按如下公式计算局部概率:
t (j )= Pr( 观察状态 | 隐藏状态j ) x Pr(t时刻所有指向j状态的路径)
特别当t=1时,没有任何指向当前状态的路径。故t=1时位于当前状态的概率是初始概率,即Pr(state|t=1)=P(state),因此,t=1时的局部概率等于当前状态的初始概率乘以相关的观察概率:
所以初始时刻状态j的局部概率依赖于此状态的初始概率及相应时刻我们所见的观察概率。
2c.计算t>1时的局部概率’s
我们再次回顾局部概率的计算公式如下:
t (j )= Pr( 观察状态 | 隐藏状态j ) x Pr(t时刻所有指向j状态的路径)
我们可以假设(递归地),乘号左边项“Pr( 观察状态 | 隐藏状态j)”已经有了,现在考虑其右边项“Pr(t时刻所有指向j状态的路径)”。
为了计算到达某个状态的所有路径的概率,我们可以计算到达此状态的每条路径的概率并对它们求和,例如:
计算所需要的路径数目随着观察序列的增加而指数级递增,但是t-1时刻’s给出了所有到达此状态的前一路径概率,因此,我们可以通过t-1时刻的局部概率定义t时刻的’s,即:
故我们所计算的这个概率等于相应的观察概率(亦即,t+1时在状态j所观察到的符号的概率)与该时刻到达此状态的概率总和——这来自于上一步每一个局部概率的计算结果与相应的状态转移概率乘积后再相加——的乘积。
注意我们已经有了一个仅利用t时刻局部概率计算t+1时刻局部概率的表达式。
现在我们就可以递归地计算给定隐马尔科夫模型(HMM)后一个观察序列的概率了——即通过t=1时刻的局部概率’s计算t=2时刻的’s,通过t=2时刻的’s计算t=3时刻的’s等等直到t=T。给定隐马尔科夫模型(HMM)的观察序列的概率就等于t=T时刻的局部概率之和。
2d.降低计算复杂度
我们可以比较通过穷举搜索(评估)和通过递归前向算法计算观察序列概率的时间复杂度。
我们有一个长度为T的观察序列O以及一个含有n个隐藏状态的隐马尔科夫模型l=(,A,B)。
穷举搜索将包括计算所有可能的序列:
公式
对我们所观察到的概率求和——注意其复杂度与T成指数级关系。相反的,使用前向算法我们可以利用上一步计算的信息,相应地,其时间复杂度与T成线性关系。
注:穷举搜索的时间复杂度是,前向算法的时间复杂度是,其中T指的是观察序列长度,N指的是隐藏状态数目。
3.总结
我们的目标是计算给定隐马尔科夫模型HMM下的观察序列的概率——Pr(observations |)。
我们首先通过计算局部概率(’s)降低计算整个概率的复杂度,局部概率表示的是t时刻到达某个状态s的概率。
t=1时,可以利用初始概率(来自于P向量)和观察概率Pr(observation|state)(来自于混淆矩阵)计算局部概率;而t>1时的局部概率可以利用t-时的局部概率计算。
因此,这个问题是递归定义的,观察序列的概率就是通过依次计算t=1,2,…,T时的局部概率,并且对于t=T时所有局部概率’s相加得到的。
注意,用这种方式计算观察序列概率的时间复杂度远远小于计算所有序列的概率并对其相加(穷举搜索)的时间复杂度。
我们使用前向算法计算T长观察序列的概率:
其中y的每一个是观察集合之一。局部(中间)概率(’s)是递归计算的,首先通过计算t=1时刻所有状态的局部概率:
然后在每个时间点,t=2,… ,T时,对于每个状态的局部概率,由下式计算局部概率:
也就是当前状态相应的观察概率与所有到达该状态的路径概率之积,其递归地利用了上一个时间点已经计算好的一些值。
最后,给定HMM,,观察序列的概率等于T时刻所有局部概率之和:
再重复说明一下,每一个局部概率(t > 2 时)都由前一时刻的结果计算得出。
对于“天气”那个例子,下面的图表显示了t = 2为状态为多云时局部概率的计算过程。这是相应的观察概率b与前一时刻的局部概率与状态转移概率a相乘后的总和再求积的结果:
总结(Summary)
我们使用前向算法来计算给定隐马尔科夫模型(HMM)后的一个观察序列的概率。它在计算中利用递归避免对网格所有路径进行穷举计算。
给定这种算法,可以直接用来确定对于已知的一个观察序列,在一些隐马尔科夫模型(HMMs)中哪一个HMM最好的描述了它——先用前向算法评估每一个(HMM),再选取其中概率最高的一个。
首先需要说明的是,本节不是这个系列的翻译,而是作为前向算法这一章的补充,希望能从实践的角度来说明前向算法。除了用程序来解读hmm的前向算法外,还希望将原文所举例子的问题拿出来和大家探讨。
文中所举的程序来自于UMDHMM这个C语言版本的HMM工具包,具体见《几种不同程序语言的HMM版本》。先说明一下UMDHMM这个包的基本情况,在linux环境下,进入umdhmm-v1.02目录,“makeall”之后会产生4个可执行文件,分别是:
genseq: 利用一个给定的隐马尔科夫模型产生一个符号序列(Generates asymbol sequence using the specified model sequence using thespecified model)
testfor: 利用前向算法计算log Prob(观察序列| HMM模型)(Computeslog Prob(observation|model) using the Forward algorithm.)
testvit: 对于给定的观察符号序列及HMM,利用Viterbi算法生成最可能的隐藏状态序列(Generates the most like state sequence for a givensymbol sequence, given the HMM, using Viterbi)
esthmm:对于给定的观察符号序列,利用BaumWelch算法学习隐马尔科夫模型HMM(Estimates the HMM from agiven symbol sequence using BaumWelch)。
这些可执行文件需要读入有固定格式的HMM文件及观察符号序列文件,格式要求及举例如下:
HMM 文件格式:
——————————————————————–
M= number of symbols
N= number of states
A:
a11 a12 … a1N
a21 a22 … a2N
. . . .
. . . .
. . . .
aN1 aN2 … aNN
B:
b11 b12 … b1M
b21 b22 … b2M
. . . .
. . . .
. . . .
bN1 bN2 … bNM
pi:
pi1 pi2 … piN
——————————————————————–
HMM文件举例:
——————————————————————–
M= 2
N= 3
A:
0.333 0.333 0.333
0.333 0.333 0.333
0.333 0.333 0.333
B:
0.5 0.5
0.75 0.25
0.25 0.75
pi:
在HMM这个翻译系列的原文中,作者举了一个前向算法的交互例子,这也是这个系列中比较出彩的地方,但是,在具体运行这个例子的时候,却发现其似乎有点问题。
先说一下如何使用这个交互例子,运行时需要浏览器支持java,我用的是firefox。首先在Set按钮前面的对话框里上观察序列,如“Dry,Damp,Soggy” 或“Dry DampSoggy”,观察符号间用逗号或空格隔开;然后再点击Set按钮,这样就初始化了观察矩阵;如果想得到一个总的结果,即Pr(观察序列|隐马尔科夫模型),就点旁边的Run按钮;如果想一步一步观察计算过程,即每个节点的局部概率,就单击旁边的Step按钮。
原文交互例子(即天气这个例子)中所定义的已知隐马尔科夫模型如下:
1、隐藏状态 (天气):Sunny,Cloudy,Rainy;
2、观察状态(海藻湿度):Dry,Dryish,Damp,Soggy;
3、初始状态概率: Sunny(0.63), Cloudy(0.17), Rainy(0.20);
4、状态转移矩阵:
weather today
Sunny Cloudy Rainy
weather Sunny 0.500 0.375 0.125
yesterday Cloudy 0.250 0.125 0.625
Rainy 0.250 0.375 0.375
5、混淆矩阵:
observed states
Dry Dryish Damp Soggy
Sunny 0.60 0.20 0.15 0.05
hidden Cloudy 0.25 0.25 0.25 0.25
states Rainy 0.05 0.10 0.35 0.50
为了UMDHMM也能运行这个例子,我们将上述天气例子中的隐马尔科夫模型转化为如下的UMDHMM可读的HMM文件weather.hmm:
——————————————————————–
M= 4
N= 3
A:
0.500 0.375 0.125
0.250 0.125 0.625
0.250 0.375 0.375
B:
0.60 0.20 0.15 0.05
0.25 0.25 0.25 0.25
0.05 0.10 0.35 0.50
pi:
0.63 0.17 0.20
——————————————————————–
在运行例子之前,如果读者也想观察每一步的运算结果,可以将umdhmm-v1.02目录下forward.c中的voidForward(…)函数替换如下:
——————————————————————–
void Forward(HMM *phmm, int T, int *O, double **alpha, double*pprob)
{
int i, j;
int t;
double sum;
for (i = 1; i <= phmm->N;i++)
{
alpha[1][i] = phmm->pi[i]*phmm->B[i][O[1]];
printf( “a[1][%d] = pi[%d] * b[%d][%d] = %f * %f = %f/n”,i, i,i, O[i], phmm->pi[i],phmm->B[i][O[1]], alpha[1][i] );
}
for (t = 1; t < T; t++)
{
for (j = 1; j <= phmm->N;j++)
{
sum = 0.0;
for (i = 1; i <= phmm->N;i++)
{
sum += alpha[t][i]* (phmm->A[i][j]);
printf( “a[%d][%d] * A[%d][%d] = %f * %f = %f/n”, t, i, i,j, alpha[t][i], phmm->A[i][j], alpha[t][i]*(phmm->A[i][j]));
printf( “sum = %f/n”, sum );
}
alpha[t+1][j] =sum*(phmm->B[j][O[t+1]]);
printf( “a[%d][%d] = sum * b[%d][%d]] = %f * %f = %f/n”,t+1,j, j, O[t+1], sum, phmm->B[j][O[t+1]], alpha[t+1][j]);
}
}
*pprob = 0.0;
for (i = 1; i <= phmm->N;i++)
{
*pprob += alpha[T][i];
printf( “alpha[%d][%d] = %f/n”, T, i, alpha[T][i] );
printf( “pprob = %f/n”, *pprob );
}
}
——————————————————————–
替换完毕之后,重新“make clean”,“makeall”,这样新的testfor可执行程序就可以输出前向算法每一步的计算结果。
现在我们就用testfor来运行原文中默认给出的观察序列“Dry,Damp,Soggy”,其所对应的UMDHMM可读的观察序列文件test1.seq:
——————————————————————–
T=3
1 3 4
——————————————————————–
好了,一切准备工作就绪,现在就输入如下命令:
testfor weather.hmm test1.seq > result1
result1就包含了所有的结果细节:
——————————————————————–
Forward without scaling
a[1][1] = pi[1] * b[1][1] = 0.630000 * 0.600000 = 0.378000
a[1][2] = pi[2] * b[2][3] = 0.170000 * 0.250000 = 0.042500
a[1][3] = pi[3] * b[3][4] = 0.200000 * 0.050000 = 0.010000
…
pprob = 0.026901
log prob(O| model) = -3.615577E+00
prob(O| model) = 0.026901
…
——————————————————————–
黑体部分是最终的观察序列的概率结果,即本例中的Pr(观察序列|HMM) = 0.026901。
但是,在原文中点Run按钮后,结果却是:Probability of this model =0.027386915。
这其中的差别到底在哪里?我们来仔细观察一下中间运行过程:
在初始化亦t=1时刻的局部概率计算两个是一致的,没有问题。但是,t=2时,在隐藏状态“Sunny”的局部概率是不一致的。英文原文给出的例子的运行结果是:
Alpha = (((0.37800002*0.5) + (0.0425*0.375) +(0.010000001*0.125)) * 0.15) = 0.03092813
而UMDHMM给出的结果是:
——————————————————————–
a[1][1] * A[1][1] = 0.378000 * 0.500000 = 0.189000
sum = 0.189000
a[1][2] * A[2][1] = 0.042500 * 0.250000 = 0.010625
sum = 0.199625
a[1][3] * A[3][1] = 0.010000 * 0.250000 = 0.002500
sum = 0.202125
a[2][1] = sum * b[1][3]] = 0.202125 * 0.150000 = 0.030319
——————————————————————–
区别就在于状态转移概率的选择上,原文选择的是状态转移矩阵中的第一行,而UMDHMM选择的则是状态转移矩阵中的第一列。如果从原文给出的状态转移矩阵来看,第一行代表的是从前一时刻的状态“Sunny”分别到当前时刻的状态“Sunny”,“Cloudy”,“Rainy”的概率;而第一列代表的是从前一时刻的状态“Sunny”,“Cloudy”,“Rainy”分别到当前时刻状态“Sunny”的概率。这样看来似乎原文的计算过程有误,读者不妨多试几个例子看看,前向算法这一章就到此为止了。