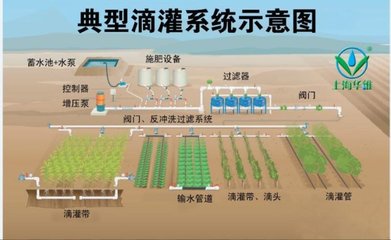
最近读了 jiawei han , micheline kamber 所著的数据挖掘概念与技一书,以下为总结:
第一. 概述
一.挖掘来源:
1. 关系数据库
2. 数据仓库
3. 事务数据库

说明:包含唯一事务标识号和组成该事务的项的列表(如,商店购买的产品)。
事务id | 商品id 的列表 |
T100 | I1, i3 , i8, i16 |
T200 | I2, i8 |
… | … |
由上表看,是个嵌套关系,大部分关系数据库不支持嵌套关系结构,事务数据库通常存放在类似上表结构的表格中,或以外键的形式存于关系表中,可以发现这是关联规则挖掘的恰当数据源。
4. 高级数据库
对象-关系数据库 时间序列数据库空间数据库 文本数据库 多媒体数据库
异构数据库 多媒体数据库 万维网
二.数据挖掘主要功能
1.特征化和区分
类似olap ,对数据初步整理汇总。
2.关联规则
3.分类和预测
4.聚类分析
5.离群点分析
6.演变分析
三.涉及学科
数据库技术 统计学 机器学习 信息科学 可视化
第二部分。 数据预处理(十分重要)
说明:数据预处理在挖掘中占有举足轻重的地位,没有好的数据就没有好的挖掘。
一.描述性数据汇总
1. 度量数据的中心趋势
均值中列数(最大与最小值的平均)中位数(按次序排中间的数) 众数(出现概率最多的数)
2. 度量数据的离散程度
极差 四分位数 离群点 盒图
方差 标准差 直方图 分位数图 散点图
总之:描述性数据汇总提供了数据总体行为的有价值的洞察。通过帮助识别噪声和离群点,他们对于数据清理十分有用。
二.数据清理
1. 缺失值
忽略 人工填写使用均值 使用同一类的均值
使用最可能的均值(利用回归 决策树等方法来估计值)
2. 噪声数据
分箱回归 聚类
三.数据集成和变换
光滑 聚集 数据泛化 规范化 属性构造
四.数据规约
数据立方体聚集 属性自己选择 维规约 数值规约
五.数据离散化和概念分层
1. 数值数据离散化和概念分层
分箱 直方图 基于熵基于x2 分析的期间合并 聚类分析 根据3-4-5法
2. 分类数据的概念分层
第三部分。数据仓库
一.多维数据模型
星型 雪花型 事实星座型
二.Olap 操作
上卷 下钻 切片 切块
第四部分。关联规则
支持度 置信度 (这两个概念是关联规则的核心)
关联规则的挖掘:1。找到频繁项集(由支持度控制)
2. 穷举频繁项集的所有关联规则,选择置信度大的作为规则。
强关联规则并不一定是有趣的,因此需要多种指标来共同分析:比如 全置信度,余弦,提升度,χ²等。
基于约束的挖掘可以显著提高挖掘效率,节省时间和空间开销
第五部分。分类和预测
有指导和无指导学习
决策树算法:了解通过信息增益选择最优属性剪枝 sliq 和 sprint算法考虑了io操作,可以处理几百万条以上的数据。(事实上对于处理大规模的数据的算法都需要考虑磁盘io,因为内存容量不可能满足)
第六部分。聚类分析
相异度:聚类算法的基础。
标度变量:
欧几里得距离:
曼哈顿距离:
民科夫斯基距离:
二元变量
D(I,j)=r+s/q+r+s
分母为总数,分子为不同值的个数。
分类变量:
D(I,j)= p-m/p
P为总数,m为相同属性的个数。
序数变量 比例标度变量混合类型变量 向量对象等的相异度 (没有看懂
聚类方法:
划分方法 层次方法基于密度的方法 基于网格的方法基于模型的方法 聚类高维数据 基于约束的聚类