1.函数Serialize()的原理
该函数的应用形式如下:
void CMyTestDoc::Serialize(CArchive& ar){
if(ar.IsStoring()){
ar<<m_Name<<m_Num;
}
else{
ar>>m_Name>>_Num;
}
}
函数Serialize()的参数ar是档案类CArchive的对象的引用,其包含一个CFile类型的文件指针。CArchive对象为读写
CFile对象中的可串行化数据提供了类型安全缓冲机制。CArchive对象只能读数据或写数据,而不能同时读写数据。当保存数据到对象ar时,该对象先将数据放至缓冲区中,直到缓冲区满,该对象才将数据写入文件指针指向的CFile对象中。当从对象ar读数据时,该对象从文件中读取内容到缓冲区,然后再从缓冲区读入到可串行化的对象中。该安全缓冲机制先集中在缓冲区中操作,减少了访问磁盘的次数,提高了不起应用程序的性能。
ar保存了打开文件的信息以及读或写等信息。当向文件中写数据时,执行ar.IsStoring(),操作符"<<"把数据存到ar定制的文件。当从文件读数据时,操作符">>"从文件中读出数据,并初始化相关成员变量。
(ar是由应用程序框架完成初始化的.)
2.函数Serialize()的调用
当读取文件或保存文件时,都要发生文档对象的序列化操作,即调用函数Serialize().
(1)读取操作
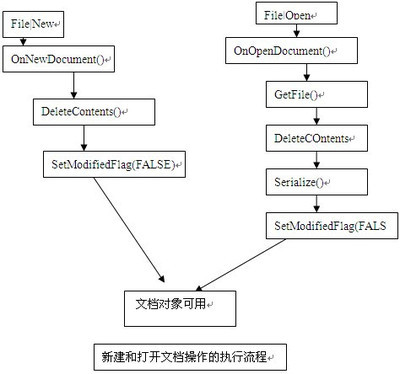
<1>单击应用程序菜单“File|New”,应用程序调用函数OnNewDocument()建立新文档。OnNewDocument()调用虚函数DeleteContents()清空文档类数据成员,然后再调用SetModifiedFlag(FALSE)将文档修改标志清除。
<2>单击应用程序菜单"File|Open",应用程序调用函数OnOpenDocument()打开已有文档。函数OnOpenDocument()调用GetFile()获取给定文件的CFile指针,再调用DeleteContents()函数清空文档类数据成员,然后把CFile指针构造CArchive对象交给Serialize函数完成读文件重建文档对象的工作,再调用SetModifiedFlag(FALSE)将文档修改标志清除。其执行流程如图:
(2)保存操作。
单击应用程序菜单“File|Save”或者“File|Save As”时,应用程序调用函数OnSaveDocument()保存指定指定文件名的文档。函数OnSaveDocument()询问文件名,调用函数GetFile()获得给文件的CFile指针,再调用函数DeleteContents()清空文档类数据成员,接着把CFile指针构造CArchive对象交给Serialize函数完成读文件重建文档对象的工作,最后调用SetModifiedFlag(FALSE)将文档修改标志清除。其执行流程如图:
(3)可序列化的数据类型
(4)可序列化函数的局限性
一般情况下,序列化函数可以完成文档数据的序列化操作,但是该函数也存在一定的局限性。
<1>序列化函数Serialize()只能顺序读写文件,而不能随机操作。并且该函数只能一次性读写全部文件,而不能读取文件的部分内容。针对该限制,开发人员可以通过获取CFile指针,再调用CFile::Open(),CFile::Read(),CFile::Write()等函数,来支持随机或部分读写文件。
<2>序列化函数Serialize只能操作二进制文件,不能处理文本文件,即利用该函数保存的文件不能像文本文件那样个具有可读性。类CSdioFile可产生可读性文件,在应用程序框架中可利用类CStdioFile解决二进制文件不可读问题。
<3>序列化函数Serialize()不支持数据文件操作,也不能共享操作文件。开发人员可以通过重载虚函数OnOpenDocument(),OnNewDocument()和OnSaveDocument(), 并在这些虚函数内按数据库访问接口编写读写数据代码来访问数据库文件,而把对数据库的操作和并发控制等任务交给数据库管理系统处理。
(4)自定义可序列化类
某类只有派生自CObject且重定义了Serialize()函数才能实现序列化,MFC定义了两个宏支持序列化,它们是DECLARE_SERIAL和IMPLEMENT_SERIAL.自定义一个可序列化类的具体步骤如下:
<1>将类的基类定义为CObject或其派生类
自定义的派生于CObject的类,可以访问CObject类的基本序列化协议和功能。其代码如下:
class CStudent::public CObject{
public:
CStudent();
virtual ~CStudent();
};
<2>覆盖该类的Serialize成员函数
序列化函数被定义在类CObject中,其操作序列化描述对象当前状态所必需的数据。成员函数Serialize的参数是一个CArchive对象的引用,用来读写对象数据。
CArchive对象的成员函数IsStoring()用来表示序列化是存储还是读取。其具体代码如下:
类CStudent
//Student.h
class CStudent:public CObject{
public:
CString m_Name;
int m_Num;
...
void Serialize(CArchive& ar);
};
//Student.cpp
void CStudent::Serialize(CArchive& ar){
//调用基类的Serialize()确保对象的继承部分被序列化
CObject::Serialize(ar);
if(ar.IsStoring())
ar<<m_Name<<m_Num;
else
ar>>m_Name>>m_Num;
<3>在类声明中,添加DECLARE_SERIAL宏
在类的声明中,添加DECARE_SERIAL宏,以类名为唯一参数,其代码如下:
class CStudent:public CObject{
DECLARE_SERIAL(CStudent)
...
}
<4>定义不带参数的构造函数
在类的声明中定义一个默认构造函数(不带任何参数的构造函数)。一般情况下,添加类时会自动生成。当从数据文件读入数据时,应用程序框架需要一个默认构造函数对象。
(如果开发人员没有在使用宏的类中定义默认的构造函数,编译器会在宏IMPLEMENT_SERIAL所在的行警告没有定义默认构造函数。)
<5>在类的实现文件中,添加IMPLEMENT_SERIAL宏
在类的实现文件(.cpp文件)中,添加IMPLEMENT_SERIAL宏,它需要3个参数,分别是需要序列化的类名。其基类名及版本号。用于类的数据成员或文档数据在程序不同版本中可能不同,那么序列化内容也不同。如果保存的数据与读取对象的版本数据不同,序列化操作会出现严重错误。因此,应用程序应该使用版本号,它代表了数据的组成和类的结构。基实现代码如下:
IMPLEMENT_SERIAL(CStudent,CObject,1) //让此类有序列化能力