时间序列分析
一、时间序列数据
1.数据类型:截面数据与时间序列数据
人们对统计数据往往可以根据其特点从两个方面来切入,以简化分析过程。一个是研究所谓横截面(crosssection)数据,也就是对大体上同时,或者和时间无关的不同对象的观测值组成的数据。
另一个称为时间序列(time series),也就是由对象在不同时间的观测值形成的数据。
前面讨论的模型多是和横截面数据有关。这里将讨论时间序列的分析。我们将不讨论更加复杂的包含这两方面的数据。
2.时间序列和回归
时间序列分析也是一种回归。
回归分析的目的是建立因变量和自变量之间关系的模型;并且可以用自变量来对因变量进行预测。通常线性回归分析因变量的观测值假定是互相独立并且有同样分布。
而时间序列的最大特点是观测值并不独立。时间序列的一个目的是用变量过去的观测值来预测同一变量的未来值。也就是说,时间序列的因变量为变量未来的可能值,而用来预测的自变量中就包含该变量的一系列历史观测值。
当然时间序列的自变量也可能包含随着时间度量的独立变量。
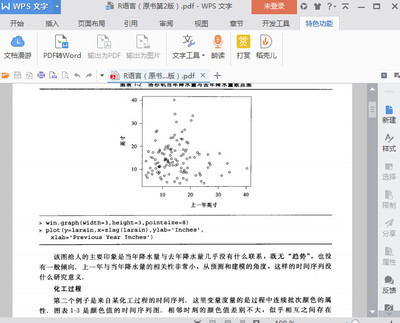
例如教材中的tssales.sav数据,就是一个时间序列的数据例子。这是某企业从1990年1月到2002年12月的销售数据(tssales.sav)。我们希望能够从这个数据找出一些规律,并且建立可以对未来的销售额进行预测的时间序列模型。
利用点图则可以得到对该数据更加直观的印象:
从这个点图可以看出。总的趋势是增长的,但增长并不是单调上升的;有涨有落。大体上看,这种升降不是杂乱无章的,和季节或月份的周期有关系。当然,除了增长的趋势和季节影响之外,还有些无规律的随机因素的作用。
二、时间序列的组成部分
从该例可以看出,该时间序列可以有三部分组成:趋势(trend)、季节(seasonal)成分和无法用趋势和季节模式解释的随机干扰(disturbance)。
例中数据的销售就就可以用这三个成分叠加而成的模型来描述。
一般的时间序列还可能有循环或波动(Cyclic, orfluctuations)成分;循环模式和有规律的季节模式不同,周期长短不一定固定。比如经济危机周期,金融危机周期等等。
一个时间序列可能有趋势、季节、循环这三个成分中的某些或全部再加上随机成分。因此,
如果要想对一个时间序列本身进行较深入的研究,把序列的这些成分分解出来、或者把它们过虑掉则会有很大的帮助。
如果要进行预测,则最好把模型中的与这些成分有关的参数估计出来。
就例中的时间序列的分解,通过SPSS软件,可以很轻而易举地得到该序列的趋势、季节和误差成分。
下图表示了去掉季节成分,只有趋势和误差成分的序列。
下图用两条曲线分别描绘了趋势成分和季节成分。
下图用两条曲线分别描绘了趋势成分和误差成分。
第二节指数平滑
一、指数平滑的基本原理
如果我们不仅仅满足于分解现有的时间序列,而且想要对未来进行预测,就需要建立模型。首先,这里介绍比较简单的指数平滑(exponentialsmoothing)。
指数平滑只能用于纯粹时间序列的情况,而不能用于含有独立变量时间序列的因果关系的研究。
指数平滑的原理为:当利用过去观测值的加权平均来预测未来的观测值时(这个过程称为平滑),离得越近的观测值要给以更多的权。
而“指数”意味着:按照已有观测值“老”的程度,其上的权数按指数速度递减。
二、指数平滑的基本方法
以简单的没有趋势和没有季节成分的纯粹时间序列为例,指数平滑在数学上这实际上是一个几何级数。这时,如果用Yt表示在t时间的平滑后的数据(或预测值),而用X1,X2, …, Xt表示原始的时间序列。那么指数平滑模型为:
自然,这种在简单情况下导出的公式(如上面的公式)无法应对具有各种成分的复杂情况。
根据数据,可以得到这些模型参数的估计以及对未来的预测。在和我们例子有关的指数平滑模型中,需要估计12个季节指标和三个参数(包含前面公式权重中的,和趋势有关的,以及和季节指标有关的)。
在简单的选项之后,SPSS通过指数平滑产生了对2003年一年的预测。下图为原始的时间序列和预测的时间序列(光滑后的),其中包括对2003年12个月的预测。图下面为误差。
第三节Box—Jenkins方法:ARIMA模型
一、ARIMA模型介绍
1.ARIMA模型结构
如果要对比较复杂的纯粹时间序列进行细致的分析,指数平滑往往是无法满足要求的。
而若想对有独立变量的时间序列进行预测,指数平滑更是无能为力。
于是需要更加强有力的模型。这就是下面要介绍的Box-JenkinsARIMA模型。
数学上,指数平滑仅仅是ARIMA模型的特例。
比指数平滑要有用和精细得多的模型是Box-Jenkins引入的ARIMA模型。或称为整合自回归移动平均模型(ARIMA为Autoregressive Integrated MovingAverage一些关键字母的缩写)。该模型的基础是自回归和移动平均模型或ARMA(Autoregressive and MovingAverage) 模型。
它由两个特殊模型发展而成,一个特例是自回归模型或AR(Autoregressive) 模型。假定时间序列用X1, X2, …, Xt表示,则一个纯粹的AR(p)模型意味着变量的一个观测值由其以前的p个观测值的线性组合加上随机误差项at(该误差为独立无关的)而得:
这看上去象自己对自己回归一样,所以称为自回归模型;它牵涉到过去p个观测值(相关的观测值间隔最多为p个)。
ARMA模型的另一个特例为移动平均模型或MA(Moving Average) 模型,一个纯粹的MA(q)模型意味着变量的一个观测值由目前的和先前的q个随机误差的线性的组合:
显然ARMA(p,0)模型就是AR(p)模型,而ARMA(0,q)模型就是MA(q)模型。这个一般模型有p+q个参数要估计,看起来很繁琐,但利用计算机软件则是常规运算;并不复杂。
2.ARIMA模型的平稳性和可逆性
要想ARMA(p,q)模型有意义则要求时间序列满足平稳性(stationarity)和可逆性(invertibility)的条件,
这意味着序列均值不随着时间增加或减少,序列的方差不随时间变化,另外序列本身相关的模式不改变等。
一个实际的时间序列是否满足这些条件是无法在数学上验证的,
这没有关系,但可以从下面要介绍的时间序列的自相关函数和偏相关函数图中可以识别出来。
一般人们所关注的的有趋势和季节/循环成分的时间序列都不是平稳的。这时就需要对时间序列进行差分(difference)来消除这些使序列不平稳的成分,而使其变成平稳的时间序列,并估计ARMA模型,估计之后再转变该模型,使之适应于差分之前的序列(这个过程和差分相反,所以称为整合的(integrated)ARMA模型),得到的模型于是称为ARIMA模型。
3.ARIMA模型:差分
差分是什么意思呢?差分可以是每一个观测值减去其前面的一个观测值,即Xt-Xt-1。这样,如果时间序列有一个斜率不变的趋势,经过这样的差分之后,该趋势就会被消除了。
当然差分也可以是每一个观测值减去其前面任意间隔的一个观测值;比如存在周期固定为s的季节成分,
那么相隔s的差分为Xt-Xt-s就可以把这种以s为周期的季节成分消除。
对于复杂情况,可能要进行多次差分,才能够使得变换后的时间序列平稳。
二、ARIMA模型的识别和估计
上面引进了一些必要的术语和概念。下面就如何识别模型进行说明。
要想拟合ARIMA模型,必须先把它利用差分变成ARMA(p,q)模型,并确定是否平稳,然后确定参数p,q。
现在利用一个例子来说明如何识别一个AR(p)模型和参数p。
由此MA(q)及ARMA(p,q)模型模型可用类似的方法来识别。
根据ARMA(p,q)模型的定义,它的参数p,q和自相关函数(acf,autocorrelationsfunction)及偏自相关函数(pacf,partial autocorrelationsfunction)有关。
自相关函数描述观测值和前面的观测值的相关系数;
而偏自相关函数为在给定中间观测值的条件下观测值和前面某间隔的观测值的相关系数。
这里当然不打算讨论这两个概念的细节。引进这两个概念主要是为了能够了解如何通过研究关于这两个函数的acf和pacf图来识别模型。
三、用ARIMA模型拟合带有独立变量的时间序列。
用ARIMA模型拟合带有独立变量的时间序列
从各种角度来看拟合带独立变量平方的ARIMA(2,1,2)(0,1,1)7模型给出更好的结果。
虽然从上面的acf和pacf图看不出(一般也不应该看出)独立变量对序列的自相关性的影响,但是根据另外的一些判别准则,独立变量的影响是显著的,而且加入独立变量使得模型更加有效。
用ARIMA模型拟合带有独立变量的时间序列
要注意,一些独立变量的效果也可能是满足某些时间序列模型的,也可能会和季节、趋势等效应混杂起来不易分辩。这时,模型选择可能就比较困难。也可能不同模型会有类似的效果。
一个时间序列在各种相关的因素影响下的模型选择并不是一件简单明了的事情。实际上没有任何统计模型是绝对正确的,它们的区别在于,在某种意义上,一些模型的某些性质可能要优于另外一些。
http://www.bbker.com/D10517.html
时间序列预测技术
预测:是对尚未发生或目前还不明确的事物进行预先的估计和推测,是在现时对事物将要发生的结果进行探讨和研究,简单地说就是指从已知事件测定未知事件。
为什么要预测呢,因为预测可以帮助了解事物发展的未来状况后,人们可以在目前为它的到来做好准备,通过预测可以了解目前的决策所可能带来的后果,并通过对后果的分析来确定目前的决策,力争使目前的决策获得最佳的未来结果。
我们进行预测的总的原则是:认识事物的发展变化规律,利用规律的必然性,是进行科学预测所应遵循的总的原则。
这个总原则实际上就是事物发展的
1-“惯性”原则——事物变化发展的延续性;
2-“类推”原则——事物发展的类似性;
3-“相关”原则——事物的变化发展是相互联系的;
4-“概率”原则——事物发展的推断预测结果能以较大概率出现,则结果成立、可用;
时间序列预测主要包括三种基本方法:
1-内生时间序列预测技术;2-外生时间序列预测技术;3-主观时间序列预测技术;
当然今天我们主要讨论内生时间序列预测技术——也就是只关注时间序列的下的预测问题!
从数据分析的角度来考虑,我们需要研究:
1.序列是否在固定水平上下变动?
2.此水平是否也在变动?
3.是否有某种上升或下降的趋势呢?
4.是否存在有季节性的模式?
5.是否季节性的模式也在变更呢?
6.是否存在周期性规律和模式?
时间序列有一明显的特性就是记忆性(memory),记忆性系指时间数列中的任一观测值的表现皆受到过去观测值影响。
时间序列主要考虑的因素是:
■长期趋势(Long-termtrend)
1.时间序列可能相当稳定或随时间呈现某种趋势。
2.时间序列趋势一般为线性的(linear),二次方程式的 (quadratic)或指数函数(exponentialfunction)。
■季节性变动(Seasonal variation)
1.按时间变动,呈现重复性行为的序列。
2.季节性变动通常和日期或气候有关。
3.季节性变动通常和年周期有关。
■周期性变动(Cyclical variation)
1.相对于季节性变动,时间序列可能经历“周期性变动”。
2.周期性变动通常是因为经济变动。
■随机影响(Random effects)
预测技术主要包括两大类:
■指数平滑方法(Exponentialsmoothing models):
描述时间序列数据的变化规律和行为,不去试图解释和理解这种变化的原因。例如:您可能发现在过去的一年里,三月和九月都会出现销售的高峰,您可能希望继续保持这样,尽管您不知道为什么。
■ARIMA模型:
描述时间序列数据的变化规律和行为,它允许模型中包含趋势变动、季节变动、循环变动和随机波动等综合因素影响。具有较高的预测精度,可以把握过去数据变动模式,有助于解释预测变动规律,回答为什么这样。
下面看看如何采用SPSS软件进行时间序列的预测!
这里我用PASW Statistics18软件,大家可能觉得没见过这个软件,其实就是SPSS18.0,不过现在SPSS已经把产品名称改称为PASW了!
平稳时间序列模型的建立
引言:对平稳时间序列建立模型一般要经过以下几步:1.模型识别:根据系统性质,以及所提供的时序据 的概貌,提出一个相适的类型的模型、模型的定阶等。2.模型参数估计:就是根据实际的观测数据具体地 确定该数学模型所包含的项数以及各项系数的 数值。3.模型的诊断检验:包括模型的适应性检验等。 4.模型的应用:如预测。 本章主要介绍前三部分的内容。
第五章 平稳时间序列模型的建立
第一节 平稳时间序列模型的识别 第二节 模型的定阶 第三节 ARMA ARMA模型参数估计 第四节 模型的诊断检验第五节建模的其它方法第五节 平稳时间序列模型实例
第一节 平稳时间序列模型的识别
一、模型识别前的说明 二、模型识别方法
上一页 下一页 返回本节首页
一、模型识别前的说明
(一)关于非平稳序列 本章所介绍的是对零均值平稳序列 零均值平稳序列建立ARMA零均值平稳序列模型,因此,在对实际的序列进行模型识别之前,应首先检验序列是否平稳,若序列非平稳,应先通过适当变换将其化为平稳序列,然后再进行模型识别。
上一页 下一页 返回本节首页
序列的非平稳包括均值非平稳和方差非 平稳。 均值非平稳序列平稳化的方法:差分变换。方差非平稳序列平稳化的方法:对数变换、平方根变换等。 序列平稳性的检验方法和手段主要有:序列趋势图、自相关图、单位根检验、非参数检验方法等等。
单位根检验
定义
–通过检验特征根是在单位圆内还是单位圆 上(外),来检验序列的平稳性
方法
– DF检验 – ADF检验 – PP检验
DF检验
假设条件
– 原假设:序列非平稳 – 备择假设:序列平稳
对1978年-2002年中国农村居民家庭人 均纯收入对数序列{ln xt }和生活消费支出 对数序列{ln yt }进行检验
例1 时序图
例1 输入序列的DF检验
例1 输出序列的DF检验
ADF检验
DF检验只适用于AR(1)过程的平稳性检 验。为了使检验能适用于AR(p)过程的平稳性检验,人们对检验进行了一定的修正,得到增广检验(AugmentedDickey-Fuller),简记为ADF检验
ADF检验的原理
若AR(p)序列有单位根存在,则自回归 系数之和恰好等于1
对1978年-2002年中国农村居民家庭人 均纯收入对数差分后序列{∇ ln xt }和生活 消费支出对数差分后序列{∇ ln yt} 进行检 验
(二)关于非零均值的平稳序列
非零均值的平稳序列有两种处理方法: 设xt为一非零均值的平稳序列,且有E(xt)=µ 方法一:用样本均值 x作为序列均值µ的估计,方法一 建模前先对序列作如下处理: 令 wt = xt − x 然后对零均值平稳序列wt建模。
方法二 在模型识别阶段对序列均值是否为零不予考虑,而在参数估计阶段,将序列均值作为一个参数加以估计。以一般的ARMA(p,q)为例说明如下:
设平稳序列 x t的均值为 µ , 其适应性模型为 ARMA ( p , q ), 即 : ( x t − µ ) − ϕ 1 ( xt −1 − µ ) − L − ϕ p ( x t − p − µ ) = a t − θ 1 a t −1 − θ 2 a t −2 − L − θ q a t − q
xt −ϕ1xt−1 −L−ϕp xt−p =θ0 +at −θ1at−1 −θ2at−2 −L−θqat−q
此时,所要估计的未知参数有p+q+1个。
将上式展开得:
式中:
θ 0 = (1 − ϕ 1 − ϕ 2 − L − ϕ p ) µ θ0 即有 : µ = 1 − ϕ1 − ϕ 2 − L − ϕp
在实际估计模型时,可将θ0看作一个常数估计, 若θ0显著不为0,则µ≠0,此时θ0 、 µ有如上关系。若θ0显著为0,则可认为µ=0,在最终模型中将此常数 项去掉即可。 一般而言,后一种方法拟合的效果较好。
(三)关于平稳序列均值是否为零的检 验。 方法一 为检验µ =E(xt)=µ=0
可将样本均值 和均值的标准差 S x 进行比较, 若样本均值落在 的范围内,则可认为 0 ± 2S x 是零均值过程。 S x的一般公式和几种特殊情况下的计算公 式参见课本P90~91.
x
二、模型识别方法
(一)平稳序列模型识别要领 零均值平稳序列模型识别的主要根据是 序列的自相关函数(ACF)和偏自相关函 (ACF)数(PACF)的特征。 (PACF) 若序列xt的偏自相关函数φ kk 在k>p以后 φ 截尾,即k>p 时,kk =0,而且它的自相 关函数ρ k拖尾,则可判断此序列是AR(p) 序列。
若序列xt的自相关函数ρk 在k>q以后截尾,即 ρ k>q 时, k = 0,而且它的偏自相关函数 φkk拖尾,则可判断此序列是MA(q)序列。若序列xt的自相关函数、偏相关函数都呈拖尾形态,则可断言此序列是ARMA序列。若序列的自相关函数和偏自相关函数不但都不截尾,而且至少有一个下降趋势势缓慢或呈周期性衰减,则可认为它也不是拖尾的,此时序列是非平稳序列,应先将其转化为平稳序列后再进行模型识别。
(二)样本自相关函数(SACF)和偏自 相关函数(SPACF)截尾性的判断。
ρ 前面模型识别方法中有关自相关函数 k 、 偏自相关函数φkk 截尾性的判断仅是理 ˆ 论上的,实际上的样本自相关函数 ρk ˆφkk 仅是理论上的一 和样本偏自相关函数 个估计值,由于样本的随机性,免不了 有误差。因此需要根据SACF和SPACF对ACF和PACF的截尾性作一判断。
1. 样本自相关函数截尾性的判断方法 理论上证明:若序列xt为MA(q)序列, ˆ ρk 渐则k>q后,序列的样本自相关函数近服从正态分布,即:
2. 样本偏自相关函数截尾性的判断方法 可以证明:若序列xt为AR(p)序列,则 ˆ k>p后,序列的样本偏自相关函数φkk 服从渐近正态分布,即近似的有:
(三)关于ARMA序列阶数的确定
ARMA序列的阶数,直接通过自相关图较 难确定,较常用的方法有Pandit-Wu方法(后将介绍)或延伸自相关函数(EACF)法。
(延伸自相关函数可参见P217附录I)
第二节 模型的定阶
模型的定阶又称模型的过拟合检验,分 两种情况,一是评价模型是否包含过多的参数。二是评价模型是否参数不足,需要拟合额外的参数。模型定阶的准则主要有残差方差图定阶法、F检验定阶法、AIC和SBC定阶准则等等。
第二节 模型的定阶
一、残差方差图定阶法
二、F检验定阶法 三、最佳准则函数定法
上一页 下一页 返回本节首页
一、残差方差图定阶法(见P94)
1.基本思想 如果拟合的模型阶数与真正阶数不符合,则模型 的残差平方和SSE必然偏大,残差方差将比真正模型的残差方差大。如果是不足拟合,那么逐渐增加模型阶数,模型的残差方差会渐减少,直到残差方差达到最小。如果是过度拟合,此时逐渐少模型阶数,模型残差方差分逐渐下降,直到残差方差达到最小。
上一页 下一页 返回本节首页
2.残差方差的估计公式
ˆ2 σa = 模型的剩余平方和 实际观察值的个数 − 模型的参数个数
注:式中“实际观察值个数”是指拟合模型时实际使用的观察值项数,即经过平稳化后的有效样本容量。设原序列有n个样本,若建立的模型中有含有自回归AR部分,且阶数为p,则实际观察值个数为n-p个。若没有AR部分,则实际观察值个数即为n个。模型的参数个数指模型中所含的参数个数,如:若是不带常数项的ARMA(p,q)模型,参数个数为p+q个,若带有常数项,则参数个数为p+q+1个。
用Eviews建立ARMA模型后,可直接得 到剩余平方和SSE(Sum squared resid)输出结果中也可直接得到残差标准差: S.E.of regression,此项的平方即为残差方差。因此,对不同的模型残差方差进行比较,直接比较此项既可。
例:以zl14.wf1 磨轮剖面数据为例, 分别建立适应性模型,输出结果见图示, 从中选择最佳模型,
三个模型残差方差比较
乘余平方和 1473.726 1539.468 1522.27 原序列长度 250 250 250 p 0 1 2 2 2 参数个数2 248 247 自由度 246 残差方差 5.990756 6.207532 6.1630364 残差标准差 2.45 2.492.48
二、F检验定阶法
1.基本思想(以一般情形和ARMA(p,q)模型为例)先对数据拟合ARMA(p,q)模型(假设不含常数项),设其残差平方和为Q0,再对数据拟合较低阶的模型ARMA(pm,q-s),设其残差平方和为Q1。
在原假设成立的条件下有:
(Q1 − Q0 ) m+s F= ~ F ( m + s, ( n − p ) − p − q ) Q0 (n − p ) − p− q
于是计算统计量F,在给定的显著性水平下α。 若F>F α,则拒绝原假设,说明两模型差异是显著的,此时模型阶数存在升高的可能性。若F
举例:见课本P98及Eviews操作。
三、最佳准则函数定法
最佳准则函数法,即确定出一个准则 函数,该函数既要考虑某一模型拟合时对原始数据的接近程度,同时又要考虑模型中所含待定参数的个数。建模时,使准则函数达到极小的是最佳 使准则函数达到极小使准则函数达到极小的是最佳 模型。 模型。
(一)赤池的AIC准则和BIC准则 1.AIC 准则(Akaike iformation criterion)AIC准则是1973年由赤池(Akaike)提 出,此准则是对FPE准则(用来判别AR模型的阶数是否合适)的推广,用来识别ARMA模型的阶数。
AIC准则函数为:
AIC ( M ) = −2 ln(极大似然函数) + 2M n n 2 ˆ ln L = − ln σ a − (1 + ln 2π) 2 2
式中,M为模型中参数的个数。 AIC的简化式为:
简化式由将对数似然函数展开,并将其中的常数项2π 去掉得到。
Eviews输出的Akaike info criterion与上 述形式略有差别(参见Eviews help),其定义为:
− 2 ln(极大似然函数) 2 M AIC ( M ) = + n n
其中:n是实际观察值的个数。 例见操作。
2.BIC准则 柴田(Shibata)1976年证明AIC有过 分估计自回归参数的倾向,于是Akaike又提出了AIC方法的贝
http://wapwenku.baidu.com/view/cb48de284b73f242336c5f33?ssid=0&from=0&bd_page_type=1&uid=frontui_1291164251_5222&pu=sl@1,pw@4500,sz@176_208,pd@1,fz@1,lp@8,tpl@wml,&st=3




