前面的几天一直都在复习着被实习落下的C++基础知识。今天在复习着上次创建的窗口程序时,出现了一个错误,百思不得其解。因为是同样的代码,上次的都能顺利的通过编译,这次自己新建了一个工程结果就有一个错误出现,是在调用Create()函数时,传参数出现问题如下图所示:
错误提示为:“const char*”与函数申明的参数类型不兼容。于是就查看了Create()函数的第二个参数类型,其函数原型如下:
virtual BOOL Create(
LPCTSTR lpszClassName,
LPCTSTRlpszWindowName,//第二个参数类型为LPCTSTR
DWORD dwStyle = WS_OVERLAPPEDWINDOW,
const RECT& rect =rectDefault,
CWnd* pParentWnd =NULL,// != NULL for popups
LPCTSTR lpszMenuName = NULL,
DWORD dwExStyle = 0,
CCreateContext* pContext = NULL);
然后我就一路Go To Definition下去,发现LPCTSTR的定义:
typedef __nullterminated CONST WCHAR *LPCWSTR,*PCWSTR;
发现其最终是一个指向WCHAR的指针,至此毫无办法,只知道是数据类型上的错误。可以说是完全从上次编译过的程序复制过来的。后面我就把其编译过的错误放上百度:
error C2664: 'CFrameWnd::Create' : cannot convertparameter 2 from 'const char [9]' to 'LPCTSTR';
一搜就在CSDN上面看到一一篇文章:(博文地址:http://blog.csdn.net/zxj2018/article/details/6765236)
VC错误之_cannot convert parameter 2 from 'const char [12]' to'LPCWSTR'
是一篇英文,不过一看就开始有眉目了:
Question
I'm trying to compile a piece of code suchas:
MessageBox("Hello world!");
... when I compile the project, the compiler yields:
error C2664: 'CWnd::MessageBoxW' : cannot convert parameter 1 from'const char [12]' to 'LPCTSTR'
What am I doing wrong?
Problem
This error message means that you are trying topass a multi-byte string (const char [12]) to a function whichexpects a unicode string (LPCTSTR). The LPCTSTR type extends toconst TCHAR*, where TCHAR is char when you compile for multi-byteand wchar_t for unicode. Since the compiler doesn't accept the chararray, we can safely assume that the actual type of TCHAR, in thiscompilation, is wchar_t.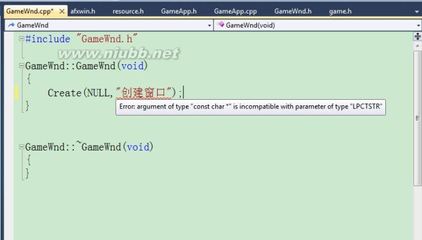
Resolution
You willhave to do one of two things:
<1> Change yourproject configuration to use multibyte strings. Press ALT+F7 toopen the properties, and navigate to Configuration Properties >General. Switch Character Set to "Use Multi-Byte CharacterSet".
<2> Indicate thatthe string literal, in this case "Hello world!" is of a specificencoding. This can be done through either prefixing it with L, suchas L"Hello world!", or surrounding it with the generic _T("Helloworld!") macro. The latter will expand to the L prefix if you arecompiling for unicode (see #1), and nothing (indicating multi-byte)otherwise.
Variations
Another error message, indicating the sameproblem, would be:
cannot convert parameter 1 from 'const char [12]' to'LPCWSTR'
Where LPCWSTR maps to a wchar_t pointer, regardless of your buildconfiguration. This problem can be resolved primarily by usingsolution #2, but in some cases also #1. A lot of the Microsoftprovided libraries, such as the Platform SDK, have got twovariations of each function which takes strings as parameters. Incase of a unicode build, the actual functions are postfixed W, suchas the MessageBoxW seen above. In case of multi-byte, the functionwould be MessageBoxA (ASCII). Which of these functions is actuallyused when you compile your application, depends on the settingdescribed in resolution #1 above.
一看到上面的project configuration,有一个CharacterSet,因此我就对比了我上次编译通过的的工程配置和今天我新建的工程配置,下面是对比的图:第一幅图是今天编译出错时的配置,第二幅是测试上次编译通过时的配置,发现在Character Set选项里有区别,编译出错时是把Character Set设置成了Use Unicode CharacterSet,按照上面的提示给设置成"UseMulti-Byte Character Set".顺利解决。
可我还是不知道为什么是这样的?上面说还有一种方法就是(不去设置工程配置):随便翻译一下<2>申明这个字符串,在这种情况下"Hello world!"作为一种特别编码,这可以通过把L作为前缀,比如这样写:L"Hello world!",或者使用通用的_T("Hello world!")宏的形式,后者将比前缀L更广泛吧,就是当你在使用unicode时而不是在设置为多字节编码。
如图:
当我再百度了几个关键字LPCWSTR,unicode,TCARH,后开始懂了为什么了,
TCARH百度百科:
定义
TCHAR是通过define定义的字符串宏
使用原理
因为C++支持两种字符串,即常规的ANSI编码(使用""包裹)和Unicode编码(使用L""包裹),这样对应的就有了两套字符串字符串处理函数,比如:strlen和wcslen,分别用于处理两种字符串
微软将这两套字符集及其操作进行了统一,通过条件编译(通过_UNICODE和UNICODE宏)控制实际使用的字符集,这样就有了_T("")这样的字符串,对应的就有了_tcslen这样的函数
为了存储这样的通用字符,就有了TCHAR:
当没有定义_UNICODE宏时,TCHAR= char,_tcslen =strlen
当定义了_UNICODE宏时,TCHAR= wchar_t , _tcslen =wcslen
当我们定义了UNICODE宏,就相当于告诉了编译器:我准备采用UNICODE版本。这个时候,TCHAR就会摇身一变,变成了wchar_t。而未定义UNICODE宏时,TCHAR摇身一变,变成了unsignedchar。这样就可以很好的切换宽窄字符集。
tchar可用于双字节字符串,使程序可以用于中日韩等国语言文字处理、显示。使编程方法简化。
LPCWSTR百度百科:
MSDN 原文
AnLPCWSTRis a 32-bitpointer to a constant string of 16-bit Unicode Charactor, which maybe null-terminated.
This type is declared as follows:
typedef const wchar_t* LPCWSTR;
简要解释
LPCWSTR是一个指向unicode编码字符串的32位指针,所指向字符串是wchar型,而不是char型。
因为在VS2005以后,编码方式默认为Unicode,部分函数在使用时默认调用Unicode方式(函数名+W,exp:MessageBox+W=MessageBoxW),而非ASNI方式(函数名+A,exp:MessageBox+A=MessageBoxA)。
请看winuser.h中的声明如下:
WINUSERAPI
int
WINAPI
MessageBoxA(
__in_opt HWND hWnd,
__in_opt LPCSTR lpText,
__in_opt LPCSTR lpCaption,
__in UINT uType);
WINUSERAPI
int
WINAPI
MessageBoxW(
__in_opt HWND hWnd,
__in_opt LPCWSTR lpText,
__in_opt LPCWSTR lpCaption,
__in UINT uType);
#ifdef UNICODE
#define MessageBox MessageBoxW
#else
#define MessageBox MessageBoxA
#endif
上述声明的意思是,在unicode编码下MessageBox被编译为MessageBoxW,否则就编译为MessageBoxA。而两者的区别则看函数声明中参数2、3就可以明白了。
关于错误
如果遇到参数错误(cannot convert parameter * from 'const char [**]'to 'LPCWSTR'),可以考虑察看声明,如果有ASNI方式的只要在函数后面加个A就可以了,或者在定义参数时把char*改为WCHAR*。
如果是混合使用的,那可以考虑转化,方法很多,不解释。
同时还了解了unicode和ASCII编码的相关知识。对C++数据类型wchar_t这种双字节的数据类型也复习了一遍,印象不是很深,C语言中没有该类型。在经过了很多时间的资料查找学习后,开始明白了上面的参数提示错误问题,主要就是char和wchar_t的问题了。当把工程配置里的Character Set 设置成"Use Multi-Byte CharacterSet"时,即编译器使用的是多种字符集编译,那么在使用Unicode字符集的时候,什么时候要在字符串前面加_T这个宏,其实关键就是函数所需传递参数是char*,还是TCHAR *。
下面是搜索的关于字符集的资料:
字符基础 -- ASCII, DBCS, Unicode
所有的 string 类都是以C-style字符串为基础的。C-style 字符串是字符数组。所以我们先介绍字符类型。这里有3种编码模式对应3种字符类型。第一种编码类型是单子节字符集(single-byte character set or SBCS)。在这种编码模式下,所有的字符都只用一个字节表示。ASCII是SBCS。一个字节表示的0用来标志SBCS字符串的结束。
第二种编码模式是多字节字符集(multi-byte character set orMBCS)。一个MBCS编码包含一些一个字节长的字符,而另一些字符大于一个字节的长度。用在Windows里的MBCS包含两种字符类型,单字节字符(single-byte characters)和双字节字符(double-byte characters)。由于Windows里使用的多字节字符绝大部分是两个字节长,所以MBCS常被用DBCS代替。
在DBCS编码模式中,一些特定的值被保留用来表明他们是双字节字符的一部分。例如,在Shift-JIS编码中(一个常用的日文编码模式),0x81-0x9f之间和 0xe0-oxfc之间的值表示 "这是一个双字节字符,下一个子节是这个字符的一部分。"这样的值被称作 "leading bytes ",他们都大于0x7f。跟随在一个leading byte子节后面的字节被称作 "trail byte"。在DBCS中,trail byte可以是任意非0值。像SBCS一样,DBCS字符串的结束标志也是一个单字节表示的0。
第三种编码模式是Unicode。Unicode是一种所有的字符都使用两个字节编码的编码模式。Unicode字符有时也被称作宽字符,因为它比单子节字符宽(使用了更多的存储空间)。注意,Unicode不能被看作MBCS。MBCS的独特之处在于它的字符使用不同长度的字节编码。Unicode字符串使用两个字节表示的0作为它的结束标志。
单字节字符包含拉丁文字母表,accented characters及ASCII标准和DOS操作系统定义的图形字符。双字节字符被用来表示东亚及中东的语言。Unicode被用在COM及Windows NT操作系统内部。
你一定已经很熟悉单字节字符。当你使用char时,你处理的是单字节字符。双字节字符也用char类型来进行操作(这是我们将会看到的关于双子节字符的很多奇怪的地方之一)。Unicode字符用wchar_t来表示。Unicode字符和字符串常量用前缀L来表示。
今天通过对这个问题的处理,虽然还不是全理解了,但也了解了很多相关的知识。