快速排序算法和合并排序算法一样,也是基于分治模式。对子数组A[p...r]快速排序的分治过程的三个步骤为:
分解:把数组A[p...r]分为A[p...q-1]与A[q+1...r]两部分,其中A[p...q-1]中的每个元素都小于等于A[q]而A[q+1...r]中的每个元素都大于等于A[q];
解决:通过递归调用快速排序,对子数组A[p...q-1]和A[q+1...r]进行排序;
合并:因为两个子数组是就地排序的,所以不需要额外的操作。
快速排序算法的伪代码:
- QUICKSORT(A, p< r) {
- 1if p<r {
- 2 q= PARTITION(A,p, r);
- 3QUICKSORT(a, p,q-1);
- 4QUICKSORT(a, q+1,r);
- 5}
- }
这个算法的关键在于数组的划分,即PARTITION:
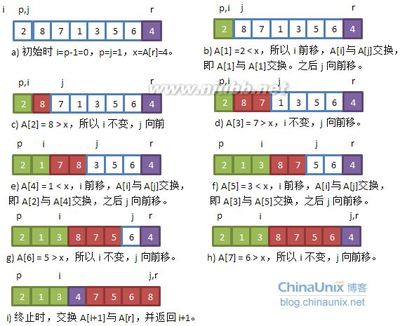
- PARTITION(A,p, r) {
- 1 x= A[r];
- 2 i= p-1;
- 3for j = p tor-1 {
- 4if A[j] ≤ x{
- 5i = i + 1;
- 6exchange(A[i],A[j]);
- 7}
- 8}
- 9 exchange(A[i+1],A[r]);
- 10return i+1;
- }
PARTITION直观上的看是做如下的操作:
我们给出PARTITION代码中第3行至第8行迭代的循环不变式:
每一轮迭代的开始,对于任何数组下标k,有:
1) 如果p≤k≤i,则A[k]≤x。
2) 如果i+1≤k≤j-1,则A[k]>x。
3) 如果k=r,则A[k]=x。
下面便是证明这个循环不变式:
初始化:循环开始前,有i=p-1和j=p。不存在k使得p≤k≤i或i+1≤k≤j-1,所以1)和2)成立。程序第一行代码里的x=A[r]使得条件3)成立。
保持:根据第4行代码的比较结果,有两种情况:
一、A[j] >x时,仅做一个j增加1的操作,所以条件1)和3)不受影响。j增加后A[j-1]>x,又因为A[1...j-2]在迭代前同样都大于x,所以条件2)成立;
二、A[j] ≤x时,i增加1,因为A[p...i-1]都小于等于x,而A[i]也小于等于x,所以A[p...i]都小于等于x,条件1)成立。j也增加1,与情况1一样,条件2)和条件3)也都成立。
终止:循环结束时j=r,根据条件1) A[p...i]都会小于等于x,而A[i+1...r-1]都大于x。
快速排序的性能
快速排序算法的性能与数组如何被切分有关。在最坏情况下,n个元素的数组被切分为n-1个元素和0个元素的两部分,PARTITION因为要经历n-1次迭代,所以运行代价为Ө(n)。即:
T(n) = T(n-1) + T(0) + Ө(n) = T(n-1) +Ө(n) (元素数为0时,QUICKSORT直接返回,所以运行代价为Ө(1))
利用代换法,可以得到最坏情况下快速排序算法的运行时间为Ө(n^2)。
在最好情况下,每次PARTITION都得到两个元素数分别为floor(n/2)和ceiling(n/2)-1的子数组,这种情况下:
T(n) ≤ 2*T(n/2) + Ө(n)
所以最佳情况下快速排序算法的运行时间为Ө(n*lg(n))。
考虑平均情况,假设每次都以9:1的例划分数组,则得到:
T(n) ≤ T(9*n/10) + T(n/10) + Ө(n)
它的递归树如下:
树的到最近的叶结点的路径长度为log_10(n),在这层之前这棵树每层都是满的,所以运行时间为cn,而越往下直至最底层log_(10/9)(n),每层的代价都会小于cn。所以以9:1划分情况下,总的运行时间
T(n) ≤ log_(10/9) (n) = O(lg(n))
事实上只要以常数比例划分数组的情况,哪怕是99:1,运行时间也仍然为O(lg(n)),只不过O记号中隐含的常量因子要大些。而一般情况下,平均下来的划分情况不应该比9:1差,直观上看来平均情况下快速算法的运行时间为O(lg(n))。
稍后会对快速排序的性能做更深入的分析。
快速排序的随机化版本
因为在平均情况下,快速排序的运行时间为O(n*lg(n)),还是比较快的,所以使所有的输入都能获得较好的平均情况性能,可以使快速排序随机化,即随机选择作为分割点的元素,而不总是数组尾部的元素:
- RANDOMIZED_PARTITION(A,p, r) {
- 1 i= RANDOM(p,r);
- 2swap(A[i],A[r]);
- 3return PARTITION(A, p,r);
- }
- RANDOMIZED_QUICKSORT(A,p, r) {
- 1if p <</SPAN> r {
- 2 q=RANDOMIZED_PARTITION(A,p, r);
- 3RANDOMIZED_QUICKSORT(A,q-1, p);
- 4RANDOMIZED_QUICKSORT(A,q+1, r);
- 5}
- }
快速排序分析
前面我们从直觉上获得最坏情况下快速排序的运行时间为O(n^2),下面来证明:
设T(n)为最坏情况下规模为n的QUICKSORT的运行时间,则有:
T(n) = max<0≤q≤n-1> (T(q) + T(n-q-1) - 1) +Ө(n) (max(...)表示即所有的划分情况下,运行时间最长的情况所花费的时间)
我们猜测T(n) ≤ c*n^2成立,于是:
T(n) ≤ max<0≤q≤n-1> (c*q^2 + c*(n-q-1)^2) + Ө(n) = c *max<0≤q≤n-1> (q^2 + (n-q-1)^2) + Ө(n)
表达式q^2 + (n-q-1)^2在取值空间0≤q≤n-1的某个端点取得最大值,因为该表达式关于q的二阶导数是正的(即关于q的二次函数是凹的),所以max<0≤q≤n-1>(q^2 + (n-q-1)^2) ≤ (n-1)^2 = n^2 - 2*n + 1,所以对于T(n)有:
T(n) ≤ c*n^2 - c*(2n-1) + Ө(n) ≤ n^2
因为我们可以选择足够大的常数c,使得项c*(2n-1)可以支配Ө(n),使得不等式成立,所以T(n) = O(n^2)。
同样,我们也可以证明T(n) = Ω(n^2),所以在最坏情况下快速排序的运行时间为Ө(n^2)。
下面来分析一下平均情况。快速排序主要在递归地调用PARTITION过程。我们先看下PARTITION调用的总次数,因为每次划分时,都会选出一个主元元素(作为基准、将数组分隔成两部分的那个元素),它将不会参与后续的QUICKSORT和PATITION调用里,所以PATITION最多只能执行n次。在PARTITON过程里,有一段循环代码(第3至第8行,将各元素与主元元素比较,并根据需要将元素调换)。我们把这段循环代码单独提出来考虑,这样在每次PATITIOIN调用里,除循环代码外的其它代码的运行时间为O(1),所以在整个排序过程中,除循环代码外的其它代码的总运行时间为O(n*1)= O(n)。
接下来分析整个排序过程中,上述循环代码的总运行时间(注意:不是某次PATITION调用里的循环代码的运行时间)。可以看到在循环代码里,数组中的各个元素之间进行比较。设总的比较次数为X,因为一次比较操作本身消耗常量时间,所以比较的总时间为O(X)。如此整个排序过程的运行时间为O(n+X)。
为了得到算法总运行时间,我们需要确定总的比较次数X的值。为了便于分析,我们将数组A中的元素重新命名为z_1,z_2,z_3,...,z_n。其中z_i是数组A中的第i小的元素。此外,我们还定义Z_i_j = {z_i,z_(i+1), ..., z_j}为z_i和z_j之间(包含这两个元素)的元素集合。
我们用指示器随机变量X_i_j = I{z_i与z_j进行比较}。这样总的比较次数:
X = ∑ ∑ X_i_j
求期望得:
E[X] = E[∑ ∑ X_i_j] = ∑ ∑ E[X_i_j] = ∑ ∑Pr{z_i与z_j进行比较}
注意两个元素一旦被划分到两个不同的区域后,则不可能相互进行比较。它们能进行比较的条件只能为:z_i和z_j在同一个区域,且z_i或z_j被选为主元元素,这样:
Pr{z_i与z_j进行比较} = Pr{z_i或z_j是从Z_i_j中选出的主元元素} =Pr{z_i是从Z_i_j中选出的主元元素} + Pr{z_j是从Z_i_j中选出的主元元素}
= 1/(j-i+1) + 1/(j-i+1) = 2/(j-i+1) (因为两事件互斥,所以概率可以直接相加)
得到x_i_j的概率后,就可以得到总的比较次数:
E[X] = ∑ ∑ Pr{z_i与z_j进行比较} = ∑ ∑ 2/(j-i+1)
设变量k = j - 1,则上式变为:
E[X] = ∑ ∑ 2/(k+1)
< ∑ ∑ 2/k
= ∑ O(lg(n)) (调合级数求和)
= O(n*lg(n))
所以在平均情况下快速排序的运行时间为O(n*lg(n))。