作为 IBM 分析与预测解决方案的重要组成部分,IBM SPSS Modeler 是一组数据挖掘工具,通过这些工具可以采用商业技术快速建立预测性模型,并将其应用于商业活动,从而改进决策过程。随着于 2010 年其新版本 14.1 的发布,名字也由 PASW Modeler 更名为现在的 IBM SPSS Modeler 。
SPSS Modeler 提供了各种借助机器学习、人工智能和统计学的建模方法。通过建模选项板中的方法,您可以根据数据生成新的信息以及开发预测模型。每种方法各有所长,同时适用于解决特定类型的问题。
回页首
初次上手
典型的 SPSS Modeler 界面如下:
图 1. SPSS Modeler 界面
接下来将详细介绍其基本概念及操作。
基本概念:节点
节点代表要对数据执行的操作。
例如,假定您需要打开某个数据源、添加新字段、根据新字段中的值选择记录,然后在表中显示结果。在这种情况下,您的数据流应由以下四个节点组成:
表 1. 节点示例
变量文件节点,设置此节点后可以读取数据源中的数据。
导出节点,用于向数据集中添加计算的新字段。
选择节点,用于设置选择标准,以从数据流中排除某些记录。
表节点,用于在屏幕上显示操作结果。
基本概念:数据流
SPSS Modeler 进行的数据挖掘重点关注通过一系列节点运行数据的过程,我们将这一过程称为数据流。也可以说 SPSS Modeler 是以数据流为驱动的产品。这一系列节点代表要对数据执行的操作,而节点之间的链接指示数据的流动方向。如,上面提到的四个节点可以创建如下数据流:
图 2. 数据流示例
通常,SPSS Modeler 将数据以一条条记录的形式读入,然后通过对数据进行一系列操作,最后将其发送至某个地方(可以是模型,或某种格式的数据输出)。使用 SPSS Modeler 处理数据的三个步骤:
将数据读入 SPSS Modeler。 通过一系列操纵运行数据。 将数据发送到目标位置。
在 SPSS Modeler 中,可以通过打开新的数据流来一次处理多个数据流。会话期间,可以在 SPSS Modeler 窗口右上角的流管理器中管理打开的多个数据流。
图 3. 流管理器
节点选项板
节点选项板位于流工作区下方窗口的底部。
图 4. 节点选项板
每个选项板选项卡均包含一组不同的流操作阶段中使用的相关节点,如:
源:此类节点可将数据导入 SPSS Modeler,如数据库、文本文件、SPSS Statistics 数据文件、Excel、XML 等。 记录选项:此类节点可对数据记录执行操作,如选择、合并和追加等。 字段选项:此类节点可对数据字段执行操作,如过滤、导出新字段和确定给定字段的测量级别等。 图形:此类节点可在建模前后以图表形式显示数据。图形包括散点图、直方图、网络节点和评估图表等。 建模:此类节点可使用 SPSS Modeler 中提供的建模算法,如神经网络、决策树、聚类算法和数据排序等。 数据库建模:节点使用 Microsoft SQL Server、IBM DB2 和 Oracle 数据库中可用的建模算法直接在数据库里进行建模及评估。 输出:节点生成数据、图表和可在 SPSS Modeler 中查看的模型等多种输出结果。 导出:节点生成可在外部应用程序(如 IBM SPSS Data Collection 或 Excel)中查看的多种输出。 IBM SPSS Statistics:节点将 IBM SPSS Statistics 数据导入或导出为 SPSS Statistics 数据,以及运行 SPSS Statistics 提供的功能。
随着对 SPSS Modeler 的熟悉,您可以在收藏夹自定义常用的选项板内容。
使用节点和流
要将节点添加到工作区,请在节点选项板中双击图标或将其拖放到工作区。已添加到流工作区的节点在连接之前不会形成数据流,可以将各个图标连接以创建一个表示数据流动的流,节点之间的连接指示数据从一项操作流向下一项操作的方向。
SPSS Modeler 中最常见的鼠标用法如下所示:
单击。使用鼠标左键或右键选择菜单选项,打开上下文相关菜单以及访问其他各种标准控件和选项。单击节点并按住按键可拖动节点。 双击。双击鼠标左键可将节点置于流工作区,编辑工作区现有节点。 中键单击。单击鼠标中键并拖动光标可在流工作区中连接节点。双击鼠标中键可断开某个节点的连接。如果没有三键鼠标,可在单击并拖动鼠标时通过按 Alt 键来模拟此功能。
创建了流以后,可以对流进行保存、添加注解,将其添加到工程。从文件主菜单中,选择流属性还可以为流设置各种选项,如优化、日期和时间设置、参数和脚本。使用流属性对话框中的消息选项卡,可以轻松查看有关运行、优化和模型构建和评估所用时间等流操作有关的消息,流操作的错误消息也将在这里报告。
SPSS Modeler 管理器
可以使用流选项卡打开、重命名、保存和删除在会话中创建的多个流。
图 5. 流管理器
输出选项卡中包含由 SPSS Modeler 中的流操作生成的输出或图形文件。您可以显示、保存、重命名和关闭此选项上列出的表格、图形和报告。
图 6. 输出文件管理器
模型选项卡是管理器选项卡中功能最强大的选项卡。该选项卡中包含所有模型块,如当前会话中生成的模型,通过 PMML 导入的模型等。这些模型可以直接从模型选项卡上浏览或将其添加到工作区的流中进行数据分析。
图 7. 模型管理器
窗口右侧底部是工程工具,用于创建和管理数据挖掘工程(与数据挖掘任务相关的文件组)。有两种方式可查看您在 SPSS Modeler 中创建的工程 - 类视图或 CRISP-DM 视图。
依据跨行业数据挖掘过程标准 CRISP-DM选项卡提供了一种组织工程的方式。不论是有经验的数据挖掘人员还是新手,使用 CRISP-DM 工具都会使您事半功倍。
图 8. 工程工具 -CRISP-DM 视图
类选项卡提供了一种在 SPSS Modeler 中按类别(按照所创建对象的类别)组织您工作的方式。此视图在获取数据、流、模型的详尽目录时十分有用。
图 9. 工程工具 - 类视图
回页首
建模简介
模型是一组规则、公式或方程式,可以用它们根据一组输入或变量来预测输出。例如,一家财务机构可根据对过往申请人的已知信息,使用模型预测贷款申请人可能存在优良还是不良风险。预测结果是预测性分析的中心目标,了解建模过程是使用 SPSS Modeler 的关键。
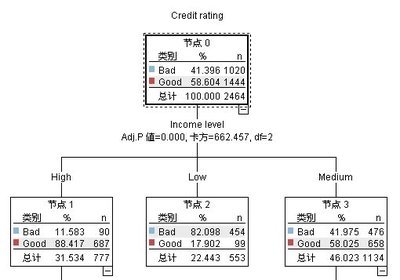
图 10. 简单的决策树模型
本示例使用 CHAID(卡方自动交互效应检测)模型,通过一系列决策规则对记录进行分类(并预测用户响应),例如:
如果收入 = 中等 并且卡 <5 则 ->“优良”
本示例旨在介绍使用 SPSS Modeler 进行数据挖掘的基本流程,其中大部分概念可广泛应用于 SPSS Modeler 中的其他建模类型。
无论要了解哪种模型,均需要首先了解进入该模型的数据。此示例中的数据包含有关银行客户的信息。其中使用了下列字段:
表 2. 数据字段
字段名 描述
Credit_rating 信用评价:0= 不良,1= 优良,9= 丢失值
年龄 客户年龄
收入 收入水平:1= 低,2= 中,3= 高
Credit_cards 持有的信用卡数量:1= 少于五张,2= 五张或更多
教育 教育程度:1= 高中,2= 大学
Car_loans 贷款的汽车数量:1= 没有或一辆,2= 超过两辆
银行可维护银行贷款客户的历史信息,包括客户是正常还贷(信用评价 = 优良)还是在拖欠贷款(信用评价 = 不良)。银行希望使用现有的数据建立一个模型,允许他们预测未来贷款申请人拖欠贷款的可能性。使用决策树模型,您可分析这两组客户的特征,并预测不良客户拖欠贷款的可能性。
构建流
本示例使用了名为 modelingintro.str的流,数据文件是 tree_credit.sav。(与示例一起使用的数据文件和样本流安装在产品安装目录下的 Demos 文件夹中。)
我们来看一下流:
从主菜单中选择下列选项:文件 > 打开流 单击“打开”对话框的工具栏上的金色模型块图标,然后选择 Demos 文件夹。见图示。 双击 streams 文件夹。 双击名为 modelingintro.str的文件。
图 11. “打开”对话框
在本例中,我们使用 CHAID 建模节点。CHAID,或卡方自动交互效应检测,是一种通过使用称作卡方统计量的特定统计类型识别决策树中的最优分割来构建决策树的分类方法。
要构建流以创建模型,至少需要三个元素:
从外部源读取数据的源节点,在本示例中为 IBM SPSS Statistics 数据文件。 指定字段属性的类型节点,字段属性包括测量级别(字段包含的数据类型)以及每个字段在建模过程中的角色是目标还是输入等。 在运行流时生成模型块的建模节点。
该流中还包含表节点和分析节点,当创建模型块并将其添加到流以后,可使用这两个节点查看评分结果以评估模型。
图 12. 流 modelingintro.str
Statistics 文件源节点从 tree_credit.sav 数据文件读取 SPSS Statistics 格式数据,该文件安装在 Demos 文件夹中。(名为 $CLEO_DEMOS 的特殊变量用于引用安装目录位于 Demos 目录下的文件。这样,无论当前的安装文件夹或版本是什么,均可以确保路径有效。如在本例中可以写作:$CLEO_DEMOS/tree_credit.sav,与图中全路径效果是一样的。)
图 13. 源节点
类型节点指定每个字段的测量级别。测量级别是一种指示字段中数据类型的类别。我们的源数据文件使用三种不同的测量级别:
连续字段(Continuous,例如年龄字段)包含连续的数字值,而名义字段(Nominal,例如信用评价字段)有两个或多个不同值,如不良、优良或无信用历史。有序字段(Ordinal,例如收入水平字段)用于描述具有顺序固定的不同值的数据,在本例中为低、中和高。
对于每个字段,类型节点还指定角色,以指示每个字段在建模中扮演的部分。字段信用评价(Credit rating)指示指定的客户是否拖欠贷款,这是要预测的目标字段,将其角色设置为目标。对于其他字段,将角色设置为输入。输入字段也称为预测变量,即建模算法用来预测目标字段值的字段。
CHAID建模节点生成模型。在建模节点的字段选项卡中,已选中使用预定义角色,这意味着将使用在类型节点中指定的目标字段和输入字段。可以在此处更改字段角色,但在本例中不做任何更改。
图 14. CHAID 模型节点 - 字段页
单击“构建选项”选项卡。
图 15. CHAID 模型节点 - 构建选项页 - 目标项
此处包含的选项可以用于指定要构建的模型类型。由于我们想要一个全新的模型,因此使用默认选项构建新模型。我们还要求它为单个标准决策树模型,并且不使用任何增强,因此保留默认目标选项构建单个树。还可以选择启动交互会话对模型进行手动的微调,本示例只使用默认设置来生成模型。
对于此示例,我们希望保持树的结构简单,因此通过增加用于父节点和子节点的最小记录数限制树的增长。
在构建选项选项卡上,从左侧的导航器窗格选择停止规则。 选择使用绝对值选项。 将父分支中的最小记录数设置为 400。 将子分支中的最小记录数设置为 200。
图 16. CHAID 模型节点 - 构建选项页 - 停止规则项
我们可以使用所有其他默认选项,然后单击运行以创建模型。(或者,也可以右键单击该节点然后选择运行,或选择节点并从工具主菜单中选择运行。)
浏览模型
等一小段时间当流执行完成后,模型块将被添加到应用程序窗口右上角的模型选项板中,它还会被自动连接在流工作区中,并带有指向创建它的建模节点的链接。要查看模型的详细信息,右键单击模型块并选择浏览(在模型选项板上)或编辑(在工作区上)。
图 17. 包含模型块的流 modelingintro.str
对于 CHAID 模型块,模型选项卡以规则集的形式显示详细信息,规则集实际上是可根据不同输入字段的值将各个记录分配给相应子节点的一组规则。
图 18. CHAID 模型块 - 模型页
对于每个决策树终端节点 -- 意味着那些树节点没有再进一步拆分 -- 返回优良或不良的预测值。对于落在该节点内的记录,所有个案中的预测均由模式或最常见的响应决定。
在规则集的右侧,模型选项卡显示预测变量重要性图表,该图表显示评估模型时每个预测变量的相对重要性。通过这一点,我们看到收入水平 (Income level)在此个案中最显著,而其他唯一显著的因子是信用卡数量(Number of credit cards)。
图 19. CHAID 模型块 - 变量重要性
模型块中的查看器选项卡以树的形式显示相同的模型,每个决策点上都有一个节点。可使用工具栏上的缩放控件放大特定节点,或缩小节点以查看更完整的树。
图 20. CHAID 模型块 - 查看器页
查看树的上部分,第一个节点(节点 0)为我们提供数据集中所有记录的摘要。数据集中超过 40% 的个案分类为不良风险。这是相当高的比例,因此让我们看看树能否提示哪些因素起决定作用。我们可以看到第一个分割是根据收入水平产生的。收入水平位于低类别的记录被指定到节点 2,可以看到此类别包含贷款拖欠的百分比最高 --82%。因此我们认为此类别的客户都具有高风险。但是要注意的是,此类别中有 16% 客户实际上没有拖欠,因此说预测并非始终准确。事实上没有模型能够精确预测所有的结果,但好的模型能够根据可用数据预测出最接近的结果。
同样,如果我们查看高收入客户(节点 1),我们看到绝大部分 (89%) 是优良风险。但是在这个类别中 10 位客户也有 1 位会拖欠。还能继续精炼贷款标准以便将此处的风险最小化吗?我们继续看,接下来模型根据客户持有的信用卡数量,将这些客户分成两个子类别(节点 4 和节点 5)。对于高收入客户,如果我们只向那些信用卡少于 5 张的客户贷款,则可以将我们的成功率从 89% 提高到 97%-- 很明显是一个更满意的结果。
图 21. CHAID 模型块 - 高收入客户
回过头来看看中等收入类别(节点 3)中的那些客户是什么情况呢?他们更加均匀地划分为优良和不良评价。子类别(节点 6 和 7)这次仍然能帮助我们。如果只向那些信用卡少于 5 张的中等收入客户贷款,可将优良评价的百分比从 58% 提高到 85%-- 显著的改进。
图 22. CHAID 模型块 - 中等收入客户
至此,我们了解到输入此模型的每项记录都将被分配到一个特定节点,并且根据该节点最常见的结果分配在优良或不良中二选一的预测值。
为各个客户记录分配预测值的过程称为评分 (Scoring)。因为我们已经知道原始记录中每个客户的情况,通过对这些原始记录进行评分并与实际值相比较,可以评估该模型的准确度。让我们看看如何做到这一点。
评估模型
要评估模型的准确度,需要对一些记录(这里我们用原始记录)进行评分,并将模型预测的结果与实际结果进行比较。
图 23. 包含输出的流 modelingintro.str
要查看分数或预测值,请将表节点连接到模型块,双击表节点,然后单击运行。
可以从表中看到,模型创建了一个名为 $R-Credit rating 的字段,用来显示预测值。我们可以将这些值与原始信用评价字段进行比较。
图 24. CHAID 模型输出表格
在 SPSS Modeler 中,在评分过程中生成的字段的名称基于目标字段,再加上标准前缀,例如 $R- 表示预测值,$RC- 表示置信度值。不同的模型类型使用不同的前缀集。置信度值(confidence value)是模型自己做的评估,尺度从 0.0 到 1.0,表示每个预测值的精确程度。
与预期的一样,预测值与大多数(并非全部)记录的实际值相匹配。原因是每个 CHAID 终端节点均包含混合值,而预期值与大部分结果相匹配,对于该节点中的其他结果,该预期值是错误的。(还记得节点 2 中 16% 的少部分低收入客户其实是没有拖欠的吗?)若要避免出现此情况,可继续将树分割为更小的分支,直到每个节点都不含混合值 (100%) 为止—即全部为优良或不良。但是,这样的模型会非常复杂,并且不易推广到其他数据集。
要查看具体有多少预测值正确,我们可通读表格,并数一数预测字段 $R-Credit rating的值匹配信用评价的值的记录数量。幸运的是,我们有更简单的方式 -- 使用分析节点,它将帮助我们自动进行此项操作:将模型块连接到分析节点,双击分析节点,然后单击运行。
分析表明,2464 个记录中有 1960 个记录(约 80%)的模型预测值与实际值相匹配。
图 25. CHAID 模型分析结果
注意我们用来评分的记录和评估模型的记录是同一批数据。在真实情况中,可使用分区(partition)节点将数据分割为两个样本分别用于培训模型和评估模型。通过使用一个样本生成模型并使用另一个样本对模型进行检验,您可更有意义地评估将模型推广到其他数据集的情况。
这一阶段我们通过分析节点可以针对已知道其实际结果的记录来检验模型。下一阶段将介绍如何使用模型对我们不知道结果的记录进行评分。例如,当前不是银行客户但是可做为促销对象的人群。
对记录评分
现在,我们要查看如何对不同的记录集进行评分。这是进行建模的目标:研究已知道结果的记录,以找出模式可以让您预测未知结果记录的结果。
图 26. 包含评分数据的流 modelingintro.str
我们可以更新 Statistics 文件源节点使它指向其他数据文件,也可以添加一个新的源节点,用它读取要评分的数据。无论采用哪种方式,新数据集必须包含建模所使用的所有输入字段(年龄、收入水平、教育等),但不包含目标字段信用评价。运行表节点即可得到结果,我们就不在这里执行了。
另外,也可以将模型块添加到包含输入字段的任何流中。无论数据源是文件还是数据库,只要字段名和类型与模型使用的相匹配,源类型都无关紧要。还可以将模型块保存为单独的文件、或将模型导出为 PMML 格式以用于其他支持此格式的应用程序,或将模型存储到 IBM SPSS Collaboration and Deployment Services 存储库中,这样可以在企业范围对模型进行部署、评分和管理。无论使用何种基础结构,模型自身都按相同的方式工作。
摘要
本示例演示创建、评估模型以及对模型评分的基本步骤。
建模节点通过研究已知道结果的记录来建立模型,并创建模型块。也可称为训练模型。 可将模型块添加到包含预期字段的任何流中,以对记录进行评分。通过对已知道结果的记录(如现有客户)进行评分,可以评估模型的运行情况。 如果您对模型的运行情况感到满意,则可以对新数据(如准客户)进行评分,以预测他们的响应。 用于训练或评估模型的数据可以称为分析数据或历史数据(analytical or historical data);评分数据也可以称为业务数据(operational data )。
回页首
自动建模
对客户响应建模(自动分类器)
通过自动分类器(Auto Classifier node )节点,您可以为标志字段(例如某个客户是否很可能拖欠贷款或者是否会对特定的报价做出响应)或名义(集合)字段目标自动创建和比较多个不同模型。在本例中,我们将使用标志(是或否)字段。在一个相对简单的流中,节点生成一组候选模型并对它们进行排序,选择最有效的模型然后将它们合并为一个汇总(整体)模型。此方法将自动化操作的方便性与组合多个模型的优势融为一体,通常能产生单一模型所不能带来的更为准确的预测。
本示例以某虚构的公司为例,该公司希望通过为每个客户提供最合适的报价以获取更丰厚的收益。此方法突出了自动操作的优势。我们使用安装在 streams 目录下 Demo 文件夹中的流 pm_binaryclassifier.str,所使用的数据文件为 pm_customer_train1.sav。
图 27. 流 pm_binaryclassifier.str
历史数据
文件 pm_customer_train1.sav的历史数据包含过去的营销活动中为特定客户提供的报价,由 campaign字段的值表示,其中值为 Premium account的记录数最多。campaign 字段的值在数据中实际编码为整数(例如 2 = Premium account)。稍后,您可为这些值定义标签以产生更有意义的输出。
图 28. 数据样本
此外,其中还有字段表示每位客户的相关人口统计和财务信息。这些字段可用于构建或训练一个模型,通过基于收入、年龄或每月交易次数等特征来预测单个用户或用户群的响应概率。
构建流
添加使用 pm_customer_train1.sav的 Statistics 文件源节点,该文件位于 SPSS Modeler 安装程序的 Demos 文件夹中。(您可以在文件路径中指定 $CLEO_DEMOS/ 作为引用此文件夹的快捷方式。请注意,路径中必须使用正斜线而非反斜线,如图所示。)
图 29. 源节点
添加类型节点,然后选择响应(response)作为目标字段(设置其角色为目标)。将此字段的测量设置为标志。
对于以下字段,将角色设置为无:customer_id、campaign、response_date、purchase、purchase_date、product_id、Rowid和 X_random。因为这些字段(如用户 ID)对于构建模型其实是无意义的,把角色设置为无以后,构建模型时将自动忽略这些字段。
单击类型节点的读取值按钮以确保值获得实例化。
常见问题:当您在运行流的时候出现以下错误时,可以在类型节点中(流中没有类型节点时请先手动添加一个)单击读取值然后再运行流:
为字段 campaign 指定的类型不足 字段 campaign 未知,或有未实例化的类型
我们的源数据包含四项不同活动的信息,每个活动针对不同类型的客户。这些活动在数据中编码为整数,为了方便记住每个整数所代表的帐户类型,让我们为每个整数都定义一个标签。
在活动(campaign)字段的行上,单击值列中的条目。从下拉列表选择指定。
图 30. 类型节点
在标签列中,键入活动字段四个值中每个值将显示的标签。单击确定。
图 31. 类型节点 - 指定标签
现在我们可在输出窗口中显示标签而非仅仅是整数了。
将表节点附加到类型节点。 打开表节点,然后单击运行。 在输出窗口上,单击显示字段和值标签工具栏按钮(左起第三个)以显示标签。 单击确定关闭输出窗口。
图 32. 输出标签的表格
尽管数据包含有关四项不同活动的信息,但每一次的分析应集中关注其中一项活动。由于 Premium account 活动(在数据中编码为 campaign=2)中的记录数最多,因此可以使用选择节点实现仅在流中包含这些记录。
图 33. 选择节点
生成和比较模型
附加一个自动分类器节点,然后选择总体精确性作为对模型进行排序的度量。
将要使用的模型数设置为 3。这意味着在执行节点时将只选择三个最佳模型。
图 34. 自动分类器节点 - 模型页
在专家选项卡上,可从最多 11 种不同模型算法中进行选择。
取消选择判别式和 SVM模型类型。(这些模型需要花费更多时间培训这些数据,因此取消选中它们将可以加快示例的执行速度。如果您不介意稍等一下,也可以保留它们的选中状态。)由于在模型选项卡上将要使用的模型数设置为 3,因此节点将计算所选择九个算法的准确性,然后选择三个最准确的算法来构建一个模型块。
图 35. 自动分类器节点 - 专家页
在设置选项卡上,选择整体方法为置信度加权投票。此选项将确定如何为每条记录生成一个评分。
使用简单投票方式时,若三个模型中有两个模型均预测是,则是将以 2 比 1 的投票结果取胜。在使用置信度加权投票方式时,将基于各预测的置信度值进行加权投票。因此,如果一个预测否的模型的置信度比两个预测是的模型合在一起的置信度还高的话,则否取胜。
图 36. 自动分类器节点 - 设置页
单击运行。
几分钟后(实际情况中,由于大型数据集往往需要创建数百个模型,这可能会花费数小时或更长的时间),构建生成的模型块将放到工作区和窗口右上角的模型选项板中。您可浏览模型块,或以多种其他方式将其保存或部署。
我们从工作区打开模型块,它将列出在运行期间所创建的每个模型的详细信息。如果需要进一步探索任何单独的模型,可在模型列中双击此模型块图标,以浏览单独模型结果,甚至可以用它们生成建模节点、模型块或评估图表。在图形列中,可以双击缩略图生成标准大小的图形进行直观的显示。
图 37. 自动分类器模型块 - 模型页
默认情况下,模型会基于总体精确性排序,这是我们在自动分类器节点模型选项卡中选择的度量。根据这一度量,C51 模型的精确性最高,但 C&R 树和 CHAID 模型的精确性与之相差不大。您可以通过单击其他列的标题对该列进行排序,或者也可以从工具栏的排序方式下拉列表中选择所需的度量。
基于这些结果,我们决定使用所有三个最准确的模型。通过结合多个模型的预测,可以避免单个模型的局限性,从而使整体准确性更高。在是否使用列中,选择 C51, C&R 树和 CHAID 模型。
在模型块后附加一个分析节点(位于下方输出选项板)。右键单击分析节点,然后选择运行以运行流。
由整体模型生成的汇总得分将显示在名为 $XF-response 的字段中。当根据训练数据评分时,预测值与实际响应(如原始响应字段中的记录所示)匹配的总体精确性为 92.82%。尽管这不如本例中三个模型的最高精确性高(C51 为 92.86%),但它们之间的差距小得可以忽略不计。一般来说,整体模型应用到训练数据之外的数据集时,通常比单个模型效果更好。
图 38. 自动分类器模型块的分析结果
摘要
综上所述,我们使用自动分类器节点比较了多种不同的模型,然后使用三个最准确的模型并将它们作为一个整体自动分类器模型块添加到流中。
基于总体精确性,“C51”、“C&R 树”和 CHAID 模型对于训练数据效果最佳。 整体模型与最好的单个模型相比效果相差不大,而且当应用到其他数据集时可以起到更好的效果。如果您的目标是自动执行这一过程,您可以通过此方法获得在大多数情况下都很稳健的模型,而无需深入挖掘单个模型的细节。换句话说假设您不是对每个模型都很熟悉,那么可以尝一下自动建模,它将会自动为您提供专业的选择。 除了自动分类器节点(预测标志或名义字段),SPSS Modeler 还提供了自动数值节点(预测数值目标)和自动聚类节点(生成聚类模型),共三个自动节点。
回页首
小结
本文从 IBM SPSS Modeler 基本概念开始详细介绍其基本操作,通过典型的数据挖掘算法介绍使用 SPSS Modeler 进行数据挖掘的基本流程,以及 SPSS Modeler 强大的自动建模功能。
本文所展示的只是 SPSS Modeler 很基础的一小部分使用。随着用户使用的加深,将会了解到 SPSS Modeler 更为强大的功能,如 ADP(自动数据准备)、数据库建模等等。
参考资料
学习
developerWorks 上的 Cognos 页:获取用以提高您在 Cognos 业务分析方面的技能和资源。
developerWorks Information Management 专区:了解关于信息管理的更多信息,获取技术文档、how-to 文章、培训、下载、产品信息以及其他资源。
随时关注 developerWorks 技术活动 和 网络广播。
获得产品和技术
下载 IBM 产品评估版 或 在线试用 IBM SOA Sandbox,并开始使用来自 DB2?、Lotus?、Rational?、Tivoli? 和 WebSphere? 的应用程序开发工具和中间件产品。
讨论
加入 developerWorks 博客,并加入 My developerWorks 中文社区;您可以通过个人档案和定制主页获得符合自己的兴趣的 developerWorks 文章,并与其他 developerWorks 用户进行交流。