存储过程的优点:
1.存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
2.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
3.存储过程可以重复使用,可减少数据库开发人员的工作量
4.安全性高,可设定只有某此用户才具有对指定存储过程的使用权
一、基本语法
1.基本结构
CREATE [OR REPLACE] PROCEDURE procedure_name
[(parameter1 [model][U1] datatype1,parameter2 [model]datatype2 ...)]
IS [AS]
BEGIN
PL/SQL Block;
END [procedure_name];
其中:procedure_name是存储过程的名字,parameter用于指定参数,model用于指定参数模式,datatype用于指定参数类型,IS [AS]用于开始PL/SQL代码块。
注:当定义存储过程的参数时,只能指定数据类型,不能指定数据长度
1)建立存储过程时,既可以指定存储过程的参数,也可以不提供任何参数。
2)存储过程的参数主要有三种类型:输入参数(IN)、输出参数(OUT)、输入输出参数(INOUT),其中IN用于接收调用环境的输入参数,OUT用于将输出数据传递到调用环境,INOUT不仅要接收数据,而且要输出数据到调用环境。
3)在建立存储过程时,输入参数的IN可以省略。将select查询的结果存入到变量中,可以同时将多个列存储多个变量中,必须有一条。
示例:
CREATE OR REPLACE PROCEDURE USP_Learing
(
p_para1varchar2 :='参数一',
p_para2nvarchar2default '参数二',
p_para3 outvarchar2,
p_para4 in outvarchar2
)
IS
BEGIN
DECLARE
v_para5varchar2(20);
BEGIN
v_para5 :='输入输出:'||[U2] p_para4;
p_para3 :='输出:'||p_para1||p_para2;
p_para4 := v_para5;
END;
END USP_Learing;
2.变量赋值
V_TEST :=[U3] 123;
3.IF判断
IF V_TEST=1 THEN
BEGIN
do something
END;
END IF;
--if 范例
create or replace procedure myp12
is
begin
declare
test number(10);
begin
test := 100;
if test=100 then
dbms_output.put_line('相同');
else
dbms_output.put_line('不相同');
end if;
end;
end myp12;
4.while循环
WHILE V_TEST=1 LOOP
BEGIN
XXXX
END;
END LOOP;
注:SQL Server 中没有For循环,可以使用while循环代替
--while循环
create or replace procedure myp14
IS
BEGIN
DECLARE
bonus boolean;
BEGIN -- executable partstarts here
bonus := false;
while bonus=falseloop
dbms_output.put_line('进入while循环');
bonus :=true;
end loop;
END;
END myp14;
5.用for in 使用cursor(游标)
IS
CURSOR cur IS SELECT * FROM xxx;
BEGIN
FOR cur_result in cur LOOP
BEGIN
V_SUM :=cur_result.列名1+cur_result.列名2
END;
END LOOP;
END;
6.带参数的cursor
CURSOR C_USER(C_ID NUMBER) IS SELECT NAME FROM USER WHERETYPEID=C_ID;
OPEN C_USER(变量值);
LOOP
FETCH C_USER INTO V_NAME;
EXIT FETCH C_USER%NOTFOUND;
do something
END LOOP;
CLOSE C_USER;
二、存储过程的维护
1.删除存储过程
DROP PROCEDURE procedure_name;
2.编译存储过程
ALTER PROCEDURE procedure_name COMPILE;
3.与存储过程相关的几个查询
①查看无效的存储过程
SELECTobject_name
FROM USER_OBJECTS
WHERESTATUS='INVALID'
ANDOBJECT_TYPE='PROCEDURE'
②查看存储过程的代码
SELECT TEXT
FROM USER_SOURCE
WHERE NAME= procedure_name
其中: procedure_name是存储过程的名字
三、调用存储过程
当在SQL*PLUS中调用存储过程时,需要使用CALL或EXECUTE(exec)命令,而在PL/SQL块中可以直接引用。当调用存储过程时,如果无参数,那么直接引用存储过程名;如果存储过程带有输入参数,那么需要为输入参数提供数据值;如果存储过程带有输出参数,那么需要使用变量接收输出结果;如果存储过程带有输入输出参数,那么在调用时需要使用具有输入值的变量。
当为参数传递变量或者数据时,可以采用位置传递、名称传递和组合传递三种方法。
例:
(1)调用无参存储过程 EXEC procedure_name
(2)调用带有输入输出参数的存储过程
declare
v_para1varchar2(10);
v_para2nvarchar2(10);
v_para3varchar2(30);
v_para4varchar2(30);
begin
-- 调用存储过程
v_para1 := '123';
v_para2 := '456';
v_para4 := '789';
-- 位置传递
USP_Learing(v_para1,v_para2,v_para3,v_para4);
-- 值传递
USP_Learing(p_para1=>v_para1,p_para2=>v_para2,p_para3=>v_para3,p_para4=>v_para4);
-- 组合传递
USP_Learing(v_para1,v_para2,p_para3=>v_para3,p_para4=>v_para4);
dbms_output.put_line(v_para3);
dbms_output.put_line(v_para4);
end;
四、存储过程使用范例
1.运行存储过程范例
(1)首先dos环境连接到oracle数据库
将内容为:
create or replace procedure myp
is
begin
DBMS_OUTPUT.PUT_LINE('Hello World!');
end myp;
的sql文件放在E盘根目录下。
(2)接着执行命令 @文件名
输入“/”,回车
(3)执行execute 文件名(或者 exec 文件名)
此时并没有输出'Hello World!',看不到效果。
可以先执行:SET SERVEROUTPUT ON 命令后,再执行execute 文件名,就可看到输出语句了。
另一种方法就是使用工具来执行、完成存储过程,如PLSQL。步骤如下:
(1)打开command window,输入创建存储过程代码,结束后加“/”,回车。
(2)输入执行语句执行execute 文件名(或者 exec 文件名)
若看不到输出语句,则可先执行set serveroutput on 语句,即可看到输出语句。
2.调用存储过程范例
myp.sql
create or replace procedure myp
is
begin
declare
testvarchar2(20);
test2varchar2(20);
num1number(10);
num2number(10);
begin
test := '我是渔歌';
test2 := 'XXXXXXX'||test;
num1 := 100;
num2 := 200;
DBMS_OUTPUT.PUT_LINE(num1+num2);
DBMS_OUTPUT.PUT_LINE('Hello World!');
DBMS_OUTPUT.PUT_LINE(test);
DBMS_OUTPUT.PUT_LINE(test2);
end;
end myp;
myp2.sql
create or replace procedure myp2
is
begin
myp();
end myp2;
3.查询存储过程范例
myp3.sql
create or replace procedure myp3
(NAME_OUT out varchar2,mgr_in in number)
is
begin
select ENAME into NAME_OUT from empwhere MGR = mgr_in;
end myp3;
myp4.sql
create or replace procedure myp4
is
begin
declare NAME_OUT varchar2(20);
begin
myp3(NAME_OUT,7902);
DBMS_OUTPUT.PUT_LINE('NAME: '||NAME_OUT);
end;
end myp4;
4.插入存储过程范例
myp5.sql
create or replace procedure myp5
(name_in in varchar2,mgr_in in number,eno innumber)
is
begin
insert into emp (EMPNO,ENAME,MGR) values(eno,name_in,mgr_in);
commit;
end myp5;
myp6.sql
create or replace procedure myp6
is
begin
myp5('XXXX',7902,1002);
end myp6;
五、存储过程中常用的复合数据类型、CTE
PL/SQL记录(RECORD),单行多列
PL/SQL 表(TABLE),多行多列
PL/SQL嵌套表(TABLE),多行多列
变长数组(VARRY),多行单列
Common Table Expression(CTE)
1.RECORD范例
--Record查询(type)Record主要用于处理单行多列数据
create or replace procedure myp7
is
begin
declare
type EMP_OUT is record(n emp.ename%type,jemp.job%type,
m emp.mgr%type);
A_EMP_OUT EMP_OUT;
begin
select ENAME,JOB,MGR into A_EMP_OUT from empwhere
ENAME = 'CLARK';
dbms_output.put_line(A_EMP_OUT.n);
dbms_output.put_line(A_EMP_OUT.j);
dbms_output.put_line(A_EMP_OUT.m);
end;
end myp7;
--Record查询(rowtype)Record主要用于处理单行多列数据
create or replace procedure myp8
is
begin
declare
EMP_OUT emp%rowtype;
begin
select * into EMP_OUT from emp where ENAME ='CLARK';
dbms_output.put_line(EMP_OUT.ENAME);
dbms_output.put_line(EMP_OUT.MGR);
end;
end myp8;
2.TABLE范例
--Table表是Oracle早期版本用于处理PL/SQL集合的数据类型,表的下标可以为负值,并且元素个数无限制,不可以作为表列的数据类型使用。
create or replace procedure myp9
is
begin
declare
type EMP_OUT_TABLE is table ofemp%rowtype
index by binary_integer;
EMP_TABLE EMP_OUT_TABLE;
begin
select * bulk collect into EMP_TABLE fromemp where EMP.DEPTNO = 10;
dbms_output.put_line('NAME:'||EMP_TABLE(1).ENAME);
end;
end myp9;
--从OracleDataTabse9i开始,允许使用varchar2定义表的下标。当使用varchar2定义下标时,会按照下标值的升序方式确定元素顺序。
create or replace procedure myp10
is
begin
declare type dz_table_type is table ofnvarchar2(30)
index byvarchar2(20);
dz_table dz_table_type;
begin
dz_table('张三'):=1;
dz_table('李四'):=2;
dz_table('王五'):=3;
dz_table('赵六'):=4;
dbms_output.put_line('第一个元素:'||dz_table.first[U4] );
dbms_output.put_line(
'王五的前一个元素:'||dz_table.prior[U5] ('王五'));
dbms_output.put_line(
'李四的后一个元素:'||dz_table.next[U6] ('李四'));
dbms_output.put_line('最后一个元素:'||dz_table.last[U7] );
end;
end myp10;
3.VARRAY范例
--VARRAY用于处理PL/SQL集合的数据类型,表的下标以1开始,并且元素个数有限制,可以作为表列的数据类型使用。
create or replace procedure myp11
is
begin
declare
type emp_varray_out isvarray(20) of emp.ename%type;
emp_varrayemp_varray_out;
begin
select emp.ename bulk collectinto emp_varray from emp where emp.deptno=10;
dbms_output.put_line('NAME:'||emp_varray(1));
end;
end myp11;
4.CTE(Common Table Expression)
Common Table Expression,简称 CTE,是SQLServer中的三种保存临时结果的方法之一。另外两种是临时表和View,当然你也可以说View并不保存数据,从这一点上来将,CTE更像View一些。
当你的查询需要从一个源表中统计出结果,基于这个结果再做进一步的统计,如此3次以上的话,你必然会用到View或者临时表,现在你也可以考虑用CTE了。
CTE的语法相当的简单, 如下:
With CTE的名字 AS
(
子查询
)
Select * from CTE的名字
CTE可以实现很多不可思议的功能,巧妙之处在于CTE可以出现自己的子查询里。让我们从简单的问题开始。
先假设一个需求,贵公司的员工表存放着员工号,员工直接经理的员工号,以及员工的Title,现在需要查询出各个员工所在的层次,从0开始。
于是你看到这样的表:
create table Employee
(
MgrId int,
EmpId int,
Title nvarchar(256)
)
表中的内容如下:
NULL 1 CEO
1 2 VP
2 3 Dev Manager
2 4 QA Manager
1 5 Sales Manager
3 30 Developer
3 31 Developer
4 40 Tester
4 41 Tester
你期望得到这样的结果:
NULL 1 CEO 0
1 2 VP 1
1 5 SalesManager 1
2 3 DevManager 2
2 4 QAManager 2
4 40 Tester 3
4 41 Tester 3
3 30 Developer 3
3 31 Developer 3
最后一列为所得到的层次数字。
使用如下的SQL能得到上面的效果:
With DirectReports as
(
select MgrId, EmpId, Title, 0 as [Level] from Employee whereMgrId is null
union all
select a.MgrId, a.EmpId, a.Title, [Level]+1 as [Level]
from Employee a join DirectReports b on a.MgrId=b.EmpId
)
select * from DirectReports
为什么这个语句能够沿着CEO往下一层一层走下去,最终找到所有的员工呢?
显然要理解这一SQL必须理解包含在 as只有括号里的嵌套查询。它由两个查询结合而成:
select ..
Union All
Select..
这两个Select语句在CTE中有特殊的意义。
第一个Select子句被称为锚点语句,它返回的结果跟普通的SQL没有区别,在这里返回MgrID为null的员工。可见没有Manager是件多么美好的事情。
第二个子句就没那么普通了,它被称为 递归 语句,请注意到在from后面,Employee和DirectReport进行了链接操作。您一定会问,DirectReport的定义还没完成,这个名字代表什么结果呢?答案是它不只是代表了一个结果,实际上代表了一系列的结果。换句话说,在DirectReport这个名字下,包含着DirectReport0,DirectReport1,DirectReport2...这些较小的集合。
DirectReport0 是Employee和 锚点 结合的产物;
DirectReport1 是Employee和 DirectReport0 结合的产物;
依次类推, DirectReport n是Employee和DirectReport n-1结合的产物;
当DirectReport_n为空的时候,这个过程就结束了。
最后 锚点和DirectReport0,DirectReport1... 的并集就是DirectReport的内容。
作为一个程序员,每次看到递归的程序,必然会想到无限递归这个错误。为了避免了在开发阶段,无限递归导致数据库的崩溃,SQLServer提供了一个QueryHint,MaxRecursion,可以控制递归的最大层数,如果超过这个数字而仍为结束,则视为代码错误,强制退出。以本文所用的SQL为例,可以如下使用MaxRecursion。
With DirectReports as
(
select MgrId, EmpId, Title, 0 as [Level] from Employee whereMgrId is null
union all
select a.MgrId, a.EmpId, a.Title, [Level]+1 as [Level]
from Employee a join DirectReports b on a.MgrId=b.EmpId
)
select * from DirectReports
Option(MaxRecursion 10)
六、存储过程中异常处理
为了提高存储过程的健壮性,避免运行错误,当建立存储过程时应包含异常处理部分。
异常(EXCEPTION)是一种PL/SQL标识符,包括预定义异常、非预定义异常和自定义异常;
预定义异常是指由PL/SQL提供的系统异常;非预定义异常用于处理与预定义异常无关的Oracle错误(如完整性约束等);自定义异常用于处理与Oracle错误的其他异常情况。
RAISE_APPLICATION_ERROR用于自定义错误消息,并且消息号必须在-20000~-20999之间。
模板:
BEGIN
SELECT col1,col2 into 变量1,变量2 FROM typestruct wherexxx;
EXCEPTION
WHEN NO_DATA_FOUND THEN
xxxx;
END;
范例:
-- EXCEPTION、IFELSE、WHEN THEN
create or replace procedure myp13
IS
BEGIN
DECLARE
--real数据类型:从-3.40^38到3.40^38之间的浮点数字数据。
bonus number;
comm_missingEXCEPTION;
BEGIN -- executable partstarts here
SELECT EMP.SALINTO bonus FROM EMP WHERE EMP.empno='7369';
IF bonus IS notnull THEN
dbms_output.put_line('7369的薪金为:'||bonus);
ELSE
RAISEcomm_missing;
END IF;
null;
EXCEPTION --异常绑定
WHEN comm_missingTHEN
dbms_output.put_line('查无此人');
END;
END myp13;
七、存储过程中事务处理
事务用于确保数据的一致性,由一组相关的DML语句组成,该组DML语句所执行的操作要么全部确认,要么全部取消。
当执行事务操作(DML)时,Oracle会在被作用的表上加锁,以防止其他用户改变表结构,同时也会在被作用的行上加行锁,以防止其他事务在相应行上执行DML操作。
当执行事务提交或事务回滚时,Oracle会确认事务变化或回滚事务、结束事务、删除保存点、释放锁。
提交事务(COMMIT)确认事务变化,结束当前事务、删除保存点,释放锁,使得当前事务中所有未决的数据永久改变。
保存点(SAVEPOINT)在当前事务中,标记事务的保存点。
回滚事务(ROLLBACK)回滚整个事务,删除该事务所定义的所有保存点,释放锁,丢弃所有未决的数据改变。
回滚事务到指定的保存点(ROLLBACK TOSAVEPOINT)回滚当前事务到指定的保存点,丢弃该保存点创建后的任何改变,释放锁。
当执行数据库模式定义语言DDL(Data Definition Language)、DCL(Data ControlLanguage)语句,或退出SQL*PLUS时,会自动提交事务;
事务期间应避免与使用者互动;
查询数据期间,尽量不要启动事务;
尽可能让事务持续地越短越好;
在事务中尽可能存取最少的数据量。
八、SQL使用时应注意的地方
当使用SELECT子句查询数据时,应尽量避免使用万用字符(*),传回所有数据行。尽量利用WHERE子句进一步限制查询结果,以确保所得的数据是有用的数据,降低传送过多数据所造成的负荷;
尽量避免反复访问同一张或几张表,尤其是数据量较大的表,可以考虑先根据条件提取数据到临时表中,然后再做连接;
尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该改写;如果使用了游标,就要尽量避免在游标循环中再进行表连接的操作;
注意where字句写法,必须考虑语句顺序,应该根据索引顺序、范围大小来确定条件子句的前后顺序,尽可能的让字段顺序与索引顺序相一致,范围从大到小;
不要在where子句的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引;
注意存储过程中参数和数据类型的关系,并注意表之间连接的数据类型,避免不同数据类型之间的连接;
尽可能的使用索引字段作为查询条件,尤其是聚簇索引。
九、Java与存储过程
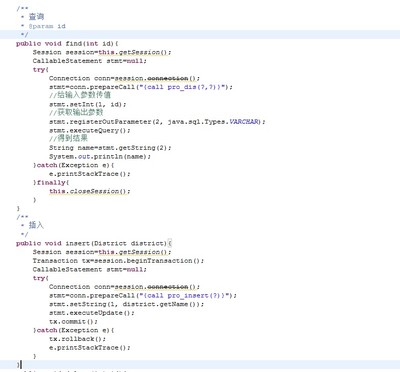
1.Java调用存储过程(JDBC)
JDBC中处理存储过程的结果集的通用流程:
(1)获取CallableStatement语句:
CallableStatement cs = conn.prepareCall("{callspName(?,?,?)}");
(2)传入输入参数和注册输出参数
cs.setXXX(index,value);//输入参数
cs.registerOutParameter(index,type);//输出参数
(3)执行存储过程:
cs.execute();或者cs.executeUpdate();
(4)有返回值的获取返回值。
(1)无返回值的(更新,插入,删除)
Sql代码:
--简单插入
create or replace procedure myp5
(name_in in varchar2,mgr_in in number,eno innumber)
is
begin
insert into emp (EMPNO,ENAME,MGR) values(eno,name_in,mgr_in);
commit;
end myp5;
Java代码:
public class TestProcedure {
Connection conn = null;
CallableStatement [U8] cstmt = null;
PreparedStatement pstmt =null;
String url ="jdbc:oracle:thin:@localhost:1521:oracle";
String driver ="oracle.jdbc.driver.OracleDriver";
String name = "";
public TestProcedure() {
try {
Class.forName(driver);
conn =DriverManager.getConnection(url, "scott", "tiger");
cstmt =conn.prepareCall[U9] ("{call[U10] myp5(?,?,?)}");
cstmt.setString(1,"间谍部2");
cstmt.setInt(2,1000);
cstmt.setInt(3,1000);
cstmt.executeUpdate();
System.out.println("success");
} catch(Exception e) {
e.printStackTrace();
} finally{
try {
cstmt.close();
conn.close();
}catch (SQLException e) {
e.printStackTrace();
}
}
}
public staticvoid main(String[] args){
TestProcedure x =new TestProcedure();
}
}
结果:
(2)有简单返回值的
Sql代码
--简单查询
create or replace procedure myp3
(NAME_OUT out varchar2,mgr_in in number)
is
begin
select ENAME into NAME_OUT from emp whereMGR = mgr_in;
end myp3;
Java代码
public class TestProcedure2 {
public staticvoid main(String[] args) {
String driver ="oracle.jdbc.driver.OracleDriver";
String strUrl ="jdbc:oracle:thin:@127.0.0.1:1521:oracle";
Statement stmt =null;
ResultSet rs =null;
Connection conn= null;
CallableStatement proc =null;
try {
Class.forName(driver);
conn =DriverManager.getConnection(strUrl, "scott", "tiger");
proc =conn.prepareCall("{ call myp3(?,?) }");
proc.setString(2[U11] , "7902");
proc.registerOutParameter[U12] (1[U13] , Types.VARCHAR);
proc.execute();
String testPrint =proc.getString(1);
System.out.println("得到的:"+ testPrint);
}
catch(SQLException ex2) {
ex2.printStackTrace();
}
catch(Exception ex2) {
ex2.printStackTrace();
}
finally{
try {
if(rs != null) {
rs.close();
if(stmt != null) {
stmt.close();
}
if(conn != null) {
conn.close();
}
}
}
catch(SQLException ex1) {
}
}
}
}
执行结果:
(3)有复杂返回值的
由于oracle存储过程没有返回值,它的所有返回值都是通过out参数来替代的,列表同样也不例外,但由于是集合,所以不能用一般的参数,必须要用pagkage了.
Sql代码
-------建一个程序包,包内只定义一个游标
CREATE OR REPLACE PACKAGE[U14] myppackage AS
--创建游标引用
TYPE Test_CURSOR IS REFCURSOR[U15] ;
end myppackage;
-------存储过程
CREATE OR REPLACE PROCEDURE myp15(p_CURSORout myppackage.Test_CURSOR[U16] )
IS
BEGIN
OPEN p_CURSOR FOR SELECT * FROM emp;
END myp15;
Java代码
public class TestProcedure3 {
public TestProcedure3() {
}
public staticvoid main(String[] args) {
String driver ="oracle.jdbc.driver.OracleDriver";
String strUrl ="jdbc:oracle:thin:@127.0.0.1:1521:oracle";
Statement stmt =null;
ResultSet rs =null;
Connection conn= null;
try {
Class.forName(driver);
conn =DriverManager.getConnection(strUrl, "scott", "tiger");
CallableStatementproc = null;
proc =conn.prepareCall("{ call myp15(?) }");
proc.registerOutParameter(1,oracle.jdbc.OracleTypes.CURSOR[U17] );
proc.execute();
rs =(ResultSet) proc.getObject(1);[U18]
while(rs.next()) {
System.out.println(rs.getString(1) + "***** " + rs.getString(2));
}
}
catch(SQLException ex2) {
ex2.printStackTrace();
}
catch(Exception ex2) {
ex2.printStackTrace();
}
finally{
try {
if(rs != null) {
rs.close();
if(stmt != null) {
stmt.close();
}
if(conn != null) {
conn.close();
}
}
}catch (SQLException ex1) {
}
}
}
}
结果:
2.Ibatis调用存储过程
在Ibatis中已经集成了存储过程的调用实现,这也是Ibatis的一大优势。Ibatis配置文件中的procedure节点对应着存储过程:如下
resultMap="get_user_result">
{call sp_getUserList()}
简单例子:
在这以现有的oa项目为例,举一个小例子(通过传入user_id得到login_name的存储过程)。
(1)SQL代码:
create or replace procedure TEST(user_idnumber,login_name out varchar)
is
begin
select LOGIN_NAME intologin_name from T_USERS where T_USERS.USER_ID = user_id;
end TEST;
(2)在T_USERS_SqlMap.xml文件中加入如下配置:
parameterMap[U19] ="procedure">
{call[U20] TEST(?,?)}
[U21] "javaType="java.lang.Integer" mode="IN[U22] " />
[U23] "resultMap[U24] ="TestNAME"/>
(3)在Dao层进行调用:
SearchDAO:
public interface SearchDAO {
public Stringexecute(int user_id);
}
SearchDAOImpl:
@Repository("searchDAO")
public class SearchDAOImplextends BasicDaoiBatis[U25] implements SearchDAO{
public Stringexecute(int user_id) {
return(String)this.get[U26] ("T_USERS[U27] .testPro[U28] ",user_id);
}
}
(4)接着自己实现service层,取得到searchDAO,调用execute方法。
(5)在Flex代码的Proxy中,调用service,从而拿到数据,完成一个流程。
3.Hibernate调用存储过程
Sql创建存储过程代码:
Create procedure SP_get_UserInfo
is
begin
select * from user order byId;
end SP_get_UserInfo;
hibernate相对应的配置文件User.hbm.xml:
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
--
Mapping file autogenerated byMyEclipse Persistence Tools
-->
catalog="user">
--
-->
--调用存储过程就在这里配-->
{call [U29] SP_get_UserInfo() }
在该文件中需注意中的这段代码,调用的存储过程在其中定义,并定义了调用存储过程后将记录组装成User对象,同时对记录的字段与对象的属性进行相关映射。
调用存储过程的Java代码:
SessionquerySession = HibernateSessionFactory.getSession();
querySession.clear();
List lst =uerySession.getNamedQuery("getUserList[U30] ").list();
for(int i=0;i
{
usr=(User)lst.get(i);
System.out.println(usr.getId()+ " " + usr.getName() + " "
+usr.getSex() + " " + usr.getBorn() + " "
+usr.getAddress());
}
HibernateSessionFactory.closeSession();
一个简单的存储过程调用就这样完成了!
这个例子提出了在hibernate3中调用mysql的存储过程的实现方案,可以看出,hibernate提供了在*.hbm.xml中配置调用存储过程,并通过向用户提供session.getNamedQuery(“…”)方法来调用配置的调用查询相关的存储过程的方法,另外,hibernate还提供了取得sql的connection的方法,从而能够通过connection中存储过程调用相关的方法来实现存储过程的调用(拿到connection后,用jdbc调用的存储过程的方法来实现)。
[U1]IN、OUT、INOUT
[U2]字符串连接符
[U3]中间不能有空格
[U4]第一个元素
[U5]王五的前一个元素
[U6]李四的下一个元素
[U7]最后一个
[U8]用于执行SQL 存储过程的接口
[U9]调用存储过程
[U10]只能用call关键字,EXECUTE不可以使用
[U11]为IN的参数是第二个参数
[U12]按顺序位置parameterIndex 将 OUT 参数注册为 JDBC 类型sqlType
[U13]为OUT的参数是第一个参数
[U14]创建包
[U15]游标
[U16]可以看到,它是把游标(可以理解为一个指针),作为一个out参数来返回值的。
[U17]类型为CURSOR
[U18]拿到结果集
[U19]参数映射,结合后面节点对映射关系加以定义。
[U20]调用存储过程关键字
[U21]该数据类型应对应数据库的数据类型,而不是Java的数据类型
[U22]输入参数
[U23]输出参数
[U24]返回结果集参数,结合节点经行定义
[U25]平台的Dao都继承BasicDaoiBatis
[U26]该方法请参阅BasicDaoiBatis代码
[U27]
对应T_USERS_SqlMap.xml文件中的namespace属性值
[U28]对应T_USERS_SqlMap.xml文件中的存储过程ID(procedure节点)
[U29]引用关键字
[U30]与sql-query节点的name属性对应