论文关键词:数字化 图书管理 档案化
论文摘要:随着社会主义现代化的发展,计算机技术的进步,信息技术在社会发展的各个领域都扮演着极其重要的角色。信息化建设更是被我国列为经济社会发展的首要内容。网页档案化管理包括文档、文字翻译转换、图片资料、声像资料、多媒体远程会议等。尤其是大学档案馆更侧重教学与科研,网页档案化管理是必然的趋势。
在信息化发展的今天,图书馆,特别是大学图书馆不仅要对信息进行简单的数字转换和管理,更要对新兴事物网络进行档案化管理和归档,包括文档、文字翻译转换、图片资料、声像资料、多媒体远程会议等。所以网络档案化管理,成为当今图书管理的必然趋势,这就必须对档案化管理的技术和法律相关问题进行深入阐述和探讨。
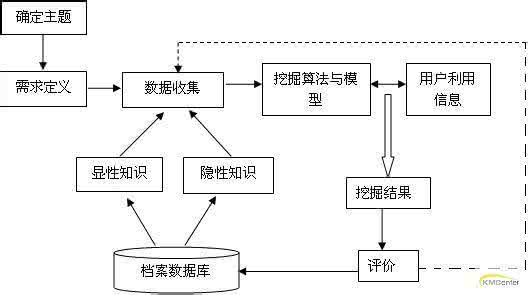
所谓数据挖掘(Data Mining),就是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的但又是潜在有用的信息和知识的过程。这些数据可以是结构化的,如关系数据库中的数据,也可以是半结构化的,如文本,图形,图像数据,甚至是分布在网络上的异构型数据。发现知识的方法可以是数学的,也可以是非数学的;可以是演绎的,也可以是归纳的。发现了的知识可以被用于信息管理、查询优化、决策支持、过程控制等,还可以进行数据自身的维护。数据挖掘借助了多年来数理统计技术和人工智能以及知识工程等领域的研究成果构建自己的理论体系,是涉及数据库、人工智能、数理统计、机械学、人工神经网络、可视化、并行计算等的交叉学科,是目前国际上数据库和决策支持领域的最前沿的研究方向之一。
一、数据挖掘的功能
数据挖掘通过预测未来趋势及行为,做出预测性的、基于知识的决策。数据挖掘的目标是从数据库中发现隐含的、有意义的知识,按其功能可分为以下几类。
1、关联分析
关联分析能寻找到数据库中大量数据的相关联系,常用的一种技术为关联规则和序列模式。关联规则是发现一个事物与其他事物间的相互关联性或相互依赖性。
2、聚类
输入的数据并无任何类型标记,聚类就是按一定的规则将数据划分为合理的集合,即将对象分组为多个类或簇,使得在同一个簇中的对象之间具有较高的相似度,而在不同簇中的对象差别很大。聚类增强了人们对客观现实的认识,是概念描述和偏差分析的先决条件。聚类技术主要包括传统的模式识别方法和数学分类学。
3、自动预测趋势和行为
数据挖掘自动在大型数据库中进行分类和预测,寻找预测性信息,自动地提出描述重要数据类的模型或预测未来的数据趋势,这样以往需要进行大量手工分析的问题如今可以迅速直接由数据本身得出结论。
4、概念描述
对于数据库中庞杂的数据,人们期望以简洁的描述形式来描述汇集的数据集。概念描述就是对某类对象的内涵进行描述并概括出这类对象的有关特征。概念描述分为特征性描述和区别性描述,前者描述某类对象的共同特征,后者描述不同类对象之间的区别。生成一个类的特征性只涉及该类对象中所有对象的共性。生成区别性描述的方法很多,如决策树方法、遗传算法等。
5、偏差检测
数据库中的数据常有一些异常记录,从数据库中检测这些偏差很有意义。偏差包括很多潜在的知识,如分类中的反常实例、不满足规则的特例、观测结果与模型预测值的偏差、量值随时间的变化等。偏差检测的基本方法是寻找观测结果与参照值之间有意义的差别。这常用于金融银行业中检测欺诈行为,或市场分析中分析特殊消费者的消费习惯。